







什么是数据挖掘?
数据挖掘 (从数据中发现知识)
从大量的数据中挖掘哪些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识
挖掘的不仅仅是数据(所以“数据挖掘”并非一个精确的用词)
数据挖掘的替换词
数据库中的知识挖掘(KDD)
知识提炼、
数据/模式分析
数据考古
数据捕捞、信息收获等等。
从大量的数据中挖掘哪些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识
挖掘的不仅仅是数据(所以“数据挖掘”并非一个精确的用词)
数据挖掘的替换词
数据库中的知识挖掘(KDD)
知识提炼、
数据/模式分析
数据考古
数据捕捞、信息收获等等。
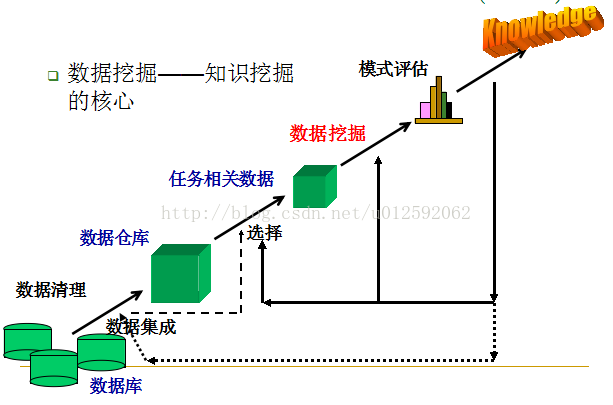
数据挖掘: 数据库中的知识挖掘(KDD)
从KDD对数据挖掘的定义中可以看到当前研究领域对数据挖掘的狭义和广义认识
--数据清理: (这个可能要占全过程60%的工作量)
--数据集成
--数据选择
--数据变换
--数据挖掘(选择适当的算法来找到感兴趣的模式)
--模式评估
--知识表示
--数据清理: (这个可能要占全过程60%的工作量)
--数据集成
--数据选择
--数据变换
--数据挖掘(选择适当的算法来找到感兴趣的模式)
--模式评估
--知识表示
典型数据挖掘系统的体系结构

在何种数据上进行数据挖掘
关系数据库
数据仓库
事务数据库
高级数据库系统和信息库
空间数据库
时间数据库和时间序列数据库
流数据
多媒体数据库
面向对象数据库和对象-关系数据库
异种数据库和历史(legacy)数据库
文本数据库和万维网(WWW)
数据仓库
事务数据库
高级数据库系统和信息库
空间数据库
时间数据库和时间序列数据库
流数据
多媒体数据库
面向对象数据库和对象-关系数据库
异种数据库和历史(legacy)数据库
文本数据库和万维网(WWW)
数据挖掘应用——市场分析和管理(1)
数据从那里来?
信用卡交易, 会员卡, 商家的优惠卷, 消费者投诉电话, 公众生活方式研究
目标市场
构建一系列的“客户群模型”,这些顾客具有相同特征: 兴趣爱好, 收入水平, 消费习惯,等等
确定顾客的购买模式
交叉市场分析
货物销售之间的相互联系和相关性,以及基于这种联系上的预测
信用卡交易, 会员卡, 商家的优惠卷, 消费者投诉电话, 公众生活方式研究
目标市场
构建一系列的“客户群模型”,这些顾客具有相同特征: 兴趣爱好, 收入水平, 消费习惯,等等
确定顾客的购买模式
交叉市场分析
货物销售之间的相互联系和相关性,以及基于这种联系上的预测
顾客分析
哪类顾客购买那种商品 (聚类分析或分类预测)
客户需求分析
确定适合不同顾客的最佳商品
预测何种因素能够吸引新顾客
提供概要信息
多维度的综合报告
统计概要信息 (数据的集中趋势和变化)
哪类顾客购买那种商品 (聚类分析或分类预测)
客户需求分析
确定适合不同顾客的最佳商品
预测何种因素能够吸引新顾客
提供概要信息
多维度的综合报告
统计概要信息 (数据的集中趋势和变化)
数据挖掘应用——公司分析和风险管理
财务计划
现金流转分析和预测
交叉区域分析和时间序列分析(财务资金比率,趋势分析等等)
资源计划
总结和比较资源和花费
竞争
对竞争者和市场趋势的监控
将顾客按等级分组和基于等级的定价过程
将定价策略应用于竞争更激烈的市场中
现金流转分析和预测
交叉区域分析和时间序列分析(财务资金比率,趋势分析等等)
资源计划
总结和比较资源和花费
竞争
对竞争者和市场趋势的监控
将顾客按等级分组和基于等级的定价过程
将定价策略应用于竞争更激烈的市场中
数据挖掘应用——欺诈行为检测和异常模式的发现
方法: 对欺骗行为进行聚类和建模,并进行孤立点分析
应用: 卫生保健、零售业、信用卡服务、电信等
汽车保险: 相撞事件的分析
洗钱: 发现可疑的货币交易行为
医疗保险
职业病人, 医生以及相关数据分析
不必要的或相关的测试
电信: 电话呼叫欺骗行为
电话呼叫模型: 呼叫目的地,持续时间,日或周呼叫次数. 分析该模型发现与期待标准的偏差
零售产业
分析师估计有38%的零售额下降是由于雇员的不诚实行为造成的
反恐怖主义
应用: 卫生保健、零售业、信用卡服务、电信等
汽车保险: 相撞事件的分析
洗钱: 发现可疑的货币交易行为
医疗保险
职业病人, 医生以及相关数据分析
不必要的或相关的测试
电信: 电话呼叫欺骗行为
电话呼叫模型: 呼叫目的地,持续时间,日或周呼叫次数. 分析该模型发现与期待标准的偏差
零售产业
分析师估计有38%的零售额下降是由于雇员的不诚实行为造成的
反恐怖主义
数据挖掘的主要功能 ——可以挖掘哪些模式?
一般功能
描述性的数据挖掘
预测性的数据挖掘
通常,用户并不知道在数据中能挖掘出什么东西,对此我们会在数据挖掘中应用一些常用的数据挖掘功能,挖掘出一些常用的模式,包括:
概念/类描述: 特性化和区分
关联分析
分类和预测
聚类分析
孤立点分析
趋势和演变分析
描述性的数据挖掘
预测性的数据挖掘
通常,用户并不知道在数据中能挖掘出什么东西,对此我们会在数据挖掘中应用一些常用的数据挖掘功能,挖掘出一些常用的模式,包括:
概念/类描述: 特性化和区分
关联分析
分类和预测
聚类分析
孤立点分析
趋势和演变分析
概念/类描述: 特性化和区分
概念描述:为数据的特征化和比较产生描述(当所描述的概念所指的是一类对象时,也称为类描述)
特征化:提供给定数据集的简洁汇总。
例:对AllElectronic公司的“大客户”(年消费额$1000以上)的特征化描述:40-50岁,有固定职业,信誉良好,等等
区分:提供两个或多个数据集的比较描述。
例:
特征化:提供给定数据集的简洁汇总。
例:对AllElectronic公司的“大客户”(年消费额$1000以上)的特征化描述:40-50岁,有固定职业,信誉良好,等等
区分:提供两个或多个数据集的比较描述。
例:

关联分析
关联规则挖掘:
从事务数据库,关系数据库和其他信息存储中的大量数据的项集之间发现有趣的、频繁出现的模式、关联和相关性。
广泛的用于购物篮或事务数据分析。
例:
从事务数据库,关系数据库和其他信息存储中的大量数据的项集之间发现有趣的、频繁出现的模式、关联和相关性。
广泛的用于购物篮或事务数据分析。
例:
分类和预测
根据训练数据集和类标号属性,构建模型来分类现有数据,并用来分类新数据(分类),用来预测类型标志未知的对象类(预测)。
比如:按气候将国家分类,按汽油消耗定额将汽车分类
导出模型的表示: 判定树、分类规则、神经网络
可以用来预报某些未知的或丢失的数字值
例:
IF age = “<=30” AND student = “no” THEN buys_computer = “no”
IF age = “<=30” AND student = “yes” THEN buys_computer = “yes”
IF age = “31…40” THEN buys_computer = “yes”
IF age = “>40” AND credit_rating = “excellent” THEN buys_computer = “yes”
IF age = “>40” AND credit_rating = “fair” THEN buys_computer = “no”
比如:按气候将国家分类,按汽油消耗定额将汽车分类
导出模型的表示: 判定树、分类规则、神经网络
可以用来预报某些未知的或丢失的数字值
例:
IF age = “<=30” AND student = “no” THEN buys_computer = “no”
IF age = “<=30” AND student = “yes” THEN buys_computer = “yes”
IF age = “31…40” THEN buys_computer = “yes”
IF age = “>40” AND credit_rating = “excellent” THEN buys_computer = “yes”
IF age = “>40” AND credit_rating = “fair” THEN buys_computer = “no”
聚类分析
聚类分析:
将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程。
最大化类内的相似性和最小化类间的相似性
例:对WEB日志的数据进行聚类,以发现相同的用户访问模式
将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程。
最大化类内的相似性和最小化类间的相似性
例:对WEB日志的数据进行聚类,以发现相同的用户访问模式
孤立点分析
孤立点分析
孤立点:一些与数据的一般行为或模型不一致的孤立数据
通常孤立点被作为“噪音”或异常被丢弃,但在欺骗检测中却可以通过对罕见事件进行孤立点分析而得到结论。
应用
信用卡欺诈检测
移动电话欺诈检测
客户划分
医疗分析(异常)
孤立点:一些与数据的一般行为或模型不一致的孤立数据
通常孤立点被作为“噪音”或异常被丢弃,但在欺骗检测中却可以通过对罕见事件进行孤立点分析而得到结论。
应用
信用卡欺诈检测
移动电话欺诈检测
客户划分
医疗分析(异常)
趋势和演变分析
描述行为随时间变化的对象的发展规律或趋势(时序数据库)
趋势和偏差: 回归分析
序列模式匹配:周期性分析
基于类似性的分析
趋势和偏差: 回归分析
序列模式匹配:周期性分析
基于类似性的分析















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









