







损失函数综述
语义分割损失函数
在文章开始之前先贴出参考:A survey of loss functions for semantic segmentation,代码地址,语义分割资源综述。我主要是参考这两个方面,然后其他更多资料也可以自行Google一下。本文章主要是以A survey of loss functions for semantic segmentation为主展开,并且尽可能地配上代码。
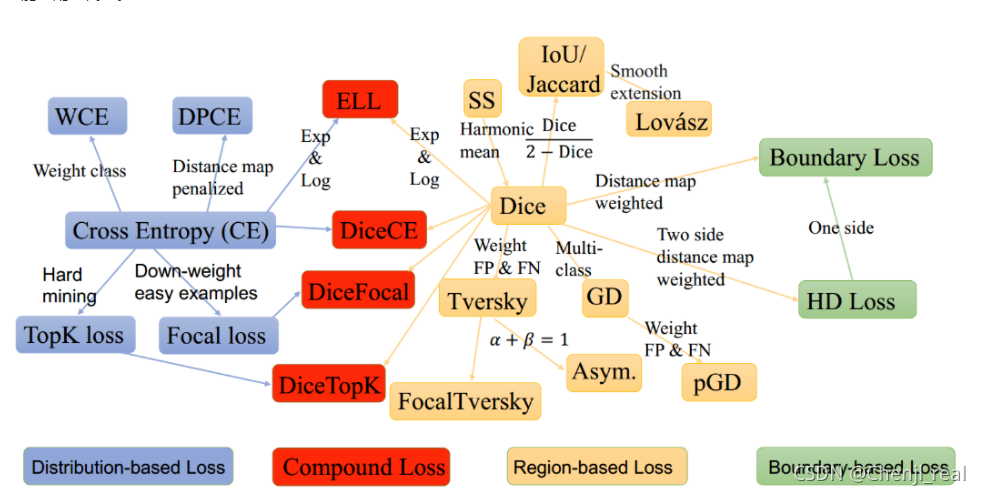
基于分布损失函数(Distribution-base loss)
Binary Cross-Entropy
公式:
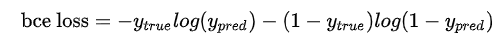
该损失主要是针对二分类的损失,当背景数量>>目标像素数量,模型会严重偏向背景
Weighted Cross-Entropy
为解决分类类别不均衡问题,提出了Weighted Cross-Entropy。公式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ynowgq5g-1631970391001)(https://www.zhihu.com/equation?tex=%5Ctext+%7Bpos_weight%7D+%3D+%5Cfrac%7B%5Ctext+%7Bnum_neg%7D%7D%7B%5Ctext+%7Bnum_pos%7D%7D+%5C%5C+%5Ctext+%7Bloss%7D+%3D+-+%5Ctext+%7Bpos_weight%7D+%5Ctimes+y_%7Btrue%7D+log+%28y_%7Bpred%7D%29+-+%281-y_%7Btrue%7D%29+log+%281-y_%7Bpred%7D%29%5C%5C)]](https://i-blog.csdnimg.cn/blog_migrate/1baf2d95bcb25b27264414e87ef82a5c.png)
Balanced Cross-Entropy
这个损失函数的公司类似于MAE。与Weighted Cross-Entropy不同的是,Balanced Cross-Entropy对负样本也进行加权。
公式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6WWKEzA5-1631970391007)(src/Balanced-CE-loss.png)]](https://i-blog.csdnimg.cn/blog_migrate/a863558cce8db1f023baa00269d8eed6.png)
Focal Loss

Focal loss主要解决两方面的问题:1. 解决正负样本不均衡的问题,里面的 α t \alpha_t αt参数负责控制;2. 解决正样本中的难易样本的区分,由 ( 1 − p t ) γ (1-p_t)^{\gamma} (1−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









