








目录
摘要
在本文中,作者提出了一种名为动态区域感知卷积(DRConv) 的新卷积,它可以自动将多个滤波器分配给具有相似特征表示的空间区域。标准卷积层通常是增加滤波器的数量以提取更多的视觉信息,但这会导致较高的计算成本。而本文的DRConv使用可学习的指导将增加的滤波器转移到空间维度,这不仅提高了卷积的表示能力,而且保持了计算成本和标准卷积的平移不变性 。DRConv是处理复杂多变空间信息分布的一种有效而优雅的方法,由于其即插即用的特性,它可以代替现有网络中的标准卷积。论文:Dynamic Region-Aware Convolution
目的
卷积神经网络(CNNs)由于其强大的表示能力,在图像分类、人脸识别、目标检测等许多应用领域取得了重大进展。CNN强大的表示能力源于不同的滤波器负责在不同的抽象级别的信息提取。
然而,当前主流的卷积运算是以滤波器共享的方式跨空间域执行的,因此只有在重复应用这些卷积运算时,才能捕获更有效的信息(比如用更多的滤波器来增加通道数和深度)。但这种方式会带来几个局限性:首先,它的计算效率很低 ;其次,滤波器数量的增加会导致优化的困难 。
与滤波器共享的方法不同,为了对更多的视觉元素进行建模,目前一些研究侧重于通过在空间维度上使用多个滤波器来利用语义信息的多样性。比如,一些方法在每个像素上都使用单独的滤波器的替代卷积(在文中这类方法成为局部卷积),因此,每个位置的特征将被用不同方式地处理,这比标准卷积能够更有效地提取空间特征。虽然与标准卷积相比,局部卷积并没有增加计算复杂度,但它有两个致命的缺点:
- 局部卷积带来大量的参数,这些参数量和特征的大小呈正相关。
- 局部卷积破坏了平移不变性,这对某些需要平移不变性特征的任务 是不友好的 (例如,局部卷积不适用于分类任务)。
这两种方法都难以在神经网络中广泛应用。此外,局部卷积仍然在不同样本之间共享滤波器,这使模型对每个样本的特定特征不敏感。例如,在人脸识别和目标检测任务中,存在具有不同姿势或视点的样本。因此,跨不同样本的共享过滤器无法有效地提取特定于样本的特征。考虑到上述局限性,本文提出了一种新的卷积算法,称为动态区域卷积算法(DRConv) ,该算法能够自动将滤波器分配到相应的空间区域,因此,DRConv具有强大的语义表示能力,并完美地保持了平移不变性。具体来说,作者设计了一个可学习的引导掩模模块(guided mask module) ,根据每个输入图像的特征自动生成滤波器,并在相同的区域内共享滤波器。由于区域和滤波器都是基于样本的特征生成的,这种方法能更有效地关注样本自身的重要特征。

DRConv的结构如上图所示,首先用标准卷积从输入生成引导特征,然后根据引导特征,将空间维度划分为多个区域,每个区域用不同的颜色表示。在每个共享区域中,作者用滤波器生成器模块生成多个滤波器来执行二维卷积运算。因此需要优化的参数主要集中在滤波器生成器模块中,其参数量与特征空间大小无关。除了显著提高网络性能外,本文的DRConv与局部卷积相比可以大大减少参数量,并且与标准卷积相比几乎不增加计算复杂度。为了验证本文方法的有效性,作者在几个不同的任务上进行了一系列的实验研究,包括图像分类、人脸识别、目标检测和分割。实验结果表明,DRConv可以在这些任务上获得优异的性能。此外,作者还提供了充分的消融研究,以分析DRConv的有效性和鲁棒性。
方法
权重共享机制限制了标准卷积模拟语义的变化。因此,标准卷积必须在通道维度上增加滤波器的数量,以匹配更多的空间视觉元素,但是这种做法是低效的。局部卷积利用了空间信息的多样性,但牺牲了平移不变性。为了解决上述限制,作者提出了DRConv,它不仅通过在空间维度上使用多个滤波器来增加多样性,而且保持这些具有相似特征的区域的平移不变性。
Dynamic Region-Aware Convolution
标准卷积的输入可以表示为 X ∈ R U × V × C X\in\mathbb{R}^{U\times V \times C} X∈RU×V×C,其中 U , V , C U,V,C U,V,C分别为高度、宽度和通道。 S ∈ R U × V S\in\mathbb{R}^{U\times V} S∈RU×V代表二维空间维度, Y ∈ R U × V × O Y\in\mathbb{R}^{U\times V \times O} Y∈RU×V×O代表输出, W ∈ R C W\in\mathbb{R}^C W∈RC代表标准卷积滤波器。对于输出特征的第 O O O个通道,可以表示为 Y u , v , o = ∑ c = 1 C X u , v , c ∗ W c ( o ) ( u , v ) ∈ S Y_{u, v, o}=\sum^{C}_{c=1}X_{u, v, c}*W_c^{(o)} \quad (u, v)\in S Yu,v,o=c=1∑CXu,v,c∗Wc(o)(u,v)∈S其中, ∗ * ∗表示二维卷积。
对于局部卷积,使用
W
∈
R
U
×
V
×
C
W\in\mathbb{R}^{U\times V\times C}
W∈RU×V×C表示在空间维度上不共享滤波器。输出特征的第
O
O
O个通道表示为:
Y
u
,
v
,
o
=
∑
c
=
1
C
X
u
,
v
,
c
∗
W
u
,
v
,
c
(
o
)
(
u
,
v
)
∈
S
Y_{u, v, o}=\sum^{C}_{c=1}X_{u, v, c}*W_{u, v, c}^{(o)} \quad (u, v)\in S
Yu,v,o=c=1∑CXu,v,c∗Wu,v,c(o)(u,v)∈S其中
W
u
,
v
,
c
(
o
)
W_{u, v, c}^{(o)}
Wu,v,c(o)表示像素
(
u
,
v
)
(u,v)
(u,v)处的不共享的滤波器。
基于上述的公式,作者定义了引导掩膜(guided mask)KaTeX parse error: Expected 'EOF', got '}' at position 25: …\cdots ,S_{m-1}}̲表示从空间维度划分的多个区域,其中单个过滤器在同一个区域中是共享的,不同滤波器用于不同的区域。
这个引导掩膜是基于输入数据自适应学习的,相应的,每个区域对应的滤波器表示为
W
=
[
W
0
,
⋯
,
W
m
−
1
]
W=[W_0, \cdots, W_{m-1}]
W=[W0,⋯,Wm−1],其中第
t
t
t个滤波器
S
t
S_t
St滤波器
W
t
∈
R
C
W_t\in\mathbb{R}^C
Wt∈RC与第
t
t
t个区域
S
t
S_t
St对应。输出特征的第
o
o
o个通道可以表示为
Y
u
,
v
,
g
=
∑
c
=
1
C
X
u
,
v
,
c
∗
W
t
,
c
(
o
)
(
u
,
v
)
∈
S
Y_{u, v, g}=\sum^{C}_{c=1}X_{u, v, c}*W_{t, c}^{(o)} \quad (u, v)\in S
Yu,v,g=c=1∑CXu,v,c∗Wt,c(o)(u,v)∈S其中
W
(
o
)
t
,
c
W^(o)_{t, c}
W(o)t,c表示
W
t
o
W_t^{o}
Wto的第
c
c
c个通道,
(
u
,
v
)
(u, v)
(u,v)表示区域
S
t
S_t
St中的一个点。
本文的方法主要分为两个步骤。首先使用一个可学习的引导掩膜将特征划分为多个空间区域,从语义上将,语义相似的特征将被分配到同一区域。其次在每个共享区域中,使用滤波器生成器模块,生成一个基于驶入的滤波器来执行正常的二维卷积运算。可学习的引导掩膜决定哪个滤波器分配给哪个区域。滤波器生成器模块用于生成不同区域的相应滤波器。
Learnable guided mask
作为DRConv的重要部分之一,可学习引导掩膜决定了滤波器在空间维度上的分布,并通过损失函数进行优化。对于具有
m
m
m个共享局域的
k
×
k
k\times k
k×k的标准卷积基于输入来生成输出通道数为
m
m
m的引导特征。用
F
∈
R
U
×
V
×
m
F\in\mathbb{R}^{U\times V\times m}
F∈RU×V×m表示引导特征,用
M
∈
U
×
V
M\in\mathbb{U\times V}
M∈U×V表示引导掩膜。对于每一个点
(
u
,
v
)
(u, v)
(u,v),引导掩膜的计算为:
M
u
,
v
=
a
r
g
m
a
x
(
F
^
u
,
v
0
,
F
^
u
,
v
1
,
⋯
,
F
^
u
,
v
m
−
1
)
M_{u, v}=argmax(\hat{F}^0_{u,v},\hat{F}^1_{u,v}, \cdots, \hat{F}^{m-1}_{u,v})
Mu,v=argmax(F^u,v0,F^u,v1,⋯,F^u,vm−1)其中,
a
r
g
m
a
x
(
⋅
)
argmax(\cdot)
argmax(⋅)表示取出最大值的下表,因此
M
u
,
v
M_{u, v}
Mu,v的值域是在0到
m
−
1
m-1
m−1的范围内。但是
a
r
g
m
a
x
(
⋅
)
argmax(\cdot)
argmax(⋅)操作使得这一部分的梯度被阶段,从而无法端到端学习,因此需要重新设计这一操作的前向传播和后向传播,如下图所示.

Forward propagation
每个滤波器 W ^ u , v \hat{W}_{u, v} W^u,v的计算表示为: W ^ u , v = W M u , v M u , v ∈ [ 0 , m − 1 ] = W ∗ M u , v \hat{W}_{u, v}=W_{M_{u, v}} \quad M_{u, v}\in[0, m-1]=W*M_{u, v} W^u,v=WMu,vMu,v∈[0,m−1]=W∗Mu,v通过这种方式, m m m个滤波器将与所有位置建立对应关系,并且可以将整个空间像素划分为 m m m个组。空间上使用相同的滤波器的像素具有相似的上下文,因为具有平移不变性的标准卷积将其信息传递给了引导特征。
Backward propagation
在反向传播的时候引入了
F
^
\hat{F}
F^:
F
^
u
,
v
j
=
e
F
u
,
v
j
∑
n
=
0
m
−
1
e
F
u
,
v
n
j
∈
[
0
,
m
−
1
]
\hat{F}^j_{u, v}=\frac{e^{F^j_{u, v}}}{\sum^{m-1}_{n=0}e^{F^n_{u, v}}} \quad j\in[0, m-1]
F^u,vj=∑n=0m−1eFu,vneFu,vjj∈[0,m−1]通过上式的
s
o
f
t
m
a
x
softmax
softmax操作,
F
^
u
,
v
j
\hat{F}^j_{u, v}
F^u,vj可以看做是近似的one-hot形式,因此
F
^
u
,
v
j
\hat{F}^j_{u, v}
F^u,vj和one-hot形式的差距就会非常小。因此在训练过程中,
M
u
,
v
M_{u, v}
Mu,v近似为
[
F
^
u
,
v
0
,
⋯
,
F
^
u
,
v
m
−
1
]
[\hat{F}^0_{u, v},\cdots,\hat{F}^{m-1}_{u, v}]
[F^u,v0,⋯,F^u,vm−1]。
F
^
u
,
v
j
\hat{F}^j_{u, v}
F^u,vj的梯度可以表示为:
▽
F
^
u
,
v
j
L
=
⟨
▽
W
^
u
,
v
L
,
W
j
⟩
j
∈
[
0
,
m
−
1
]
\bigtriangledown_{\hat{F}^{j}_{u, v}}\mathcal{L}=\langle \bigtriangledown_{\hat{W}_{u, v}}\mathcal{L}, W_j\rangle\quad j\in[0, m-1]
▽F^u,vjL=⟨▽W^u,vL,Wj⟩j∈[0,m−1]其中,
⟨
,
⟩
\langle,\rangle
⟨,⟩代表点乘,
▽
.
L
\bigtriangledown_{.}\mathcal{L}
▽.L代表梯度。前向传播的近似反向传播可以表示为:
▽
F
u
,
v
L
=
F
^
u
,
v
⊙
(
▽
F
^
u
,
v
L
−
1
⟨
F
^
u
,
v
,
▽
F
^
u
,
v
L
⟩
)
\bigtriangledown_{F_{u, v}}\mathcal{L}=\hat{F}_{u, v}\odot(\bigtriangledown_{\hat{F}_{u, v}}\mathcal{L}-1\langle \hat{F}_{u, v}, \bigtriangledown_{\hat{F}_{u, v}}\mathcal{L} \rangle)
▽Fu,vL=F^u,v⊙(▽F^u,vL−1⟨F^u,v,▽F^u,vL⟩),其中
⊙
\odot
⊙代表逐元素相乘。
Dynamic Filter: Filter generator module
在DRConv中,多个滤波器将分配到不同的区域,滤波器生成器模块用于为这些区域生成滤波器。由于不同图像之间特征的多样性,跨图像的共享滤波器不足以有效地关注图像自身的特征。因此,提出了滤波器生成模块,基于输入数据自适应的生成滤波器。
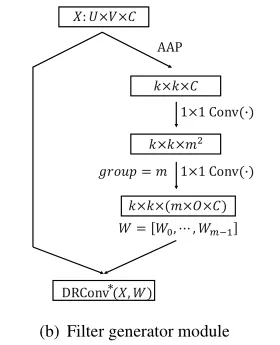
将输入特征表示为
X
∈
R
U
×
V
×
C
X\in\mathbb{R}^{U\times V\times C}
X∈RU×V×C,
G
(
⋅
)
G(\cdot)
G(⋅)代表滤波器生成模块。这些滤波器表示为
W
=
[
W
0
,
⋯
,
W
m
−
1
]
W=[W_0,\cdots, W_{m-1}]
W=[W0,⋯,Wm−1],并且在每个滤波器仅在同一个区域
R
t
R_t
Rt中共享。如上图所示,为了生成
m
m
m个卷积核大小为
k
×
k
k\times k
k×k的滤波器,作者首先用了adaptive average pooling将输入
X
X
X下采样到
k
×
k
k\times k
k×k,然后使用两个连续的
1
×
1
1\times 1
1×1卷积,中间用sigmoid激活函数,第二个卷积采用分组卷积
g
r
o
u
p
s
=
m
groups=m
groups=m。滤波器生成器模块可以增强捕获不同图像样本特征的能力。















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









