







TD-FP-Growth
两次数据库扫描
一次扫描计数
一次扫描建树
树结构的构建仍是FP-Tree的思想
挖掘频繁项集与之前的不同:从上到下依次挖掘
算法思想
1.扫描数据库,构建项头表
项头表包括三个属性:itemName itemCount side-link
side-link主要是用来标注该item在树结构中所在的位置集合
如下图可以很清晰的看出来:
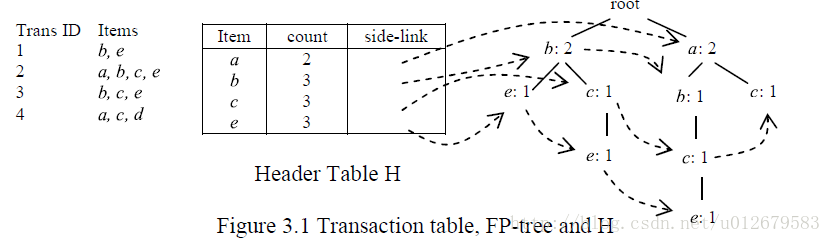
2.构建树的过程在这里就不详细记录了。。。
3.挖掘频繁项集的过程
首先看 a
a节点出现树结构的第一层 且是频繁项 直接输出频繁模式{a:2}
b
b节点在第二层出现了
构建b的子项头表H_b
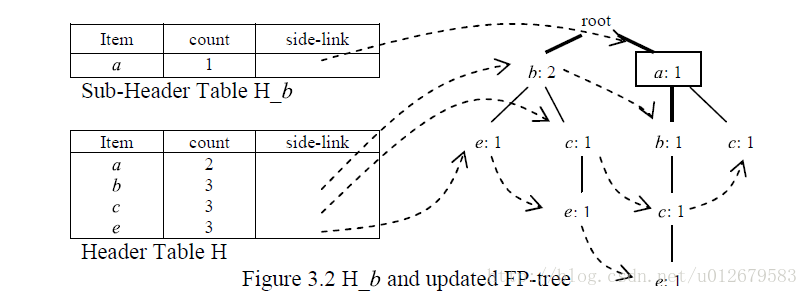
从上到下扫描树结构,有两条路径root-b root-a-b
修改a节点的计数,因为这时root-a-b只出现了1次
最小支持度阈值为2,则ab是不频繁的
将H_b从内存中删除
若ab是频繁项,则继续构建子项头表H_ab,然后挖掘FP-Tree
同理,挖掘剩余的item
延伸:
https://wenku.baidu.com/view/609cf0d6c1c708a1284a44f9.html
参考文献:
[1] Wang K, Tang L, Han J, et al. Top Down FP-Growth for Association Rule Mining[J]. 2002, 2336:334-340.















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









