




上交所市价单包括:1,最优五档剩余撤销;2,最优五档剩余转限价。
深交所市价单包括:1,对手最优;2,本方最优;3,即时成交剩余撤销;4,最优五档剩余撤销;5,全额成交或撤销申报。
最优五档剩余撤销:
- 比如市价卖出1000股,盘口价格为:
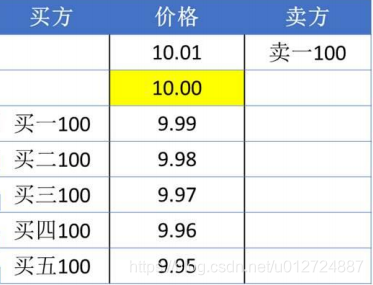
- 成交原则就是从买一到买五依次成交,剩余的委托撤销。即买一到买五都成交,剩余还有500股撤销。
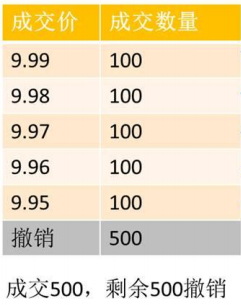
最优五档剩余转限价:
- 市价卖出1000股,盘口价格如上所示;
- 按照买一到买五分别成交,剩余500股转限价,限价为买5价,即五档价格,即9.95元卖出500股。
本方最优价:
- 市价卖出1000股,盘口价格如下图所示:
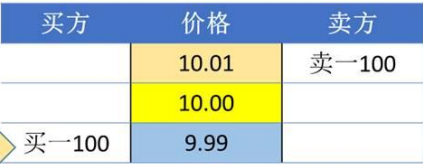
- 即下限价10.01元卖出1000股,即卖出的本方最优价就是卖一价
对手方最优价:
- 市价卖出1000股,盘口价格如上图所示:
- 即下限价9.99元卖出1000股,即卖出的对手方最优价就是买一家。
即时成交剩余撤销申报:
- 市价卖出1000股,盘口价格如下图所示:
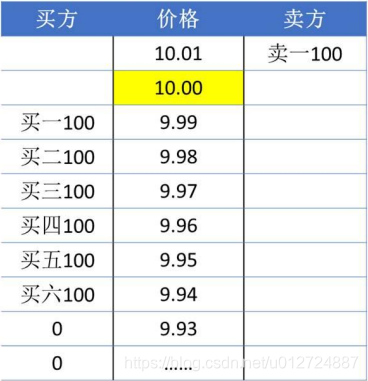
- 与最优五档剩余撤销不同的是,即时成交剩余撤销申报,扩大的范围,不限于最优五档,而是扩大到全部有效的价格范围,有多少买单就成交多少。按照买一、买二依次成交。
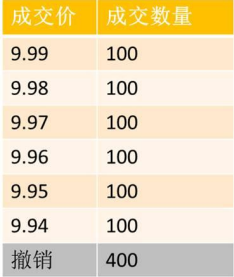
全额成交或撤销申报:
- 市价卖出1000股,盘口价格如上图所示:
- 成交同样不限于五档,但若此笔订单不能全部成交,则自动全部撤销。

















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









