









自编码器
目录
- 在输出层模拟输入层的结果,中间层为code
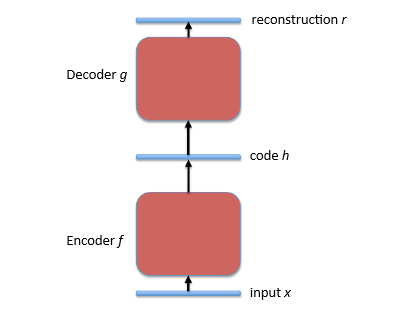
图一自编码器结构
其中:
- 输入, x
- 编码函数, f
- 内部表征,“码” h = f(x)
- 解码函数 g
- 输出, 重构 r=g(h)=g(f(x))
- 损失函数 L 计算 L(r, x) 的值来测量 r 对给定输入 x 表达的效果. 目标是最小化 L 的值
稀疏编码
By Olshausen and Field, 1996
经典表述:
h=f(x)=arghminL(g(h),x))+λΩ(h)
其中
- L 是损失函数
- f 是(无参)编码函数
- g 是(参数化)解码函数
稀疏编码的一个有趣的变种
predictive sparse decomposition (PSD) (Kavukcuoglu et al., 2008)
惩罚函数
除了 L1 :
还有 Student_t
∑ilog(1+α2h2i)和 KL-diverence−∑i(tloghi+(1−t)log(1−hi))其中 t 是目标稀疏指数
Auto-Encoders
- Try to copy its output to its input
figure 1 the schema of auto-encoders
Where:
- an input, x
- An encoder function, f
- A “code” or internal representation h = f(x)
- A decode function g
- An output, or “reconstruction” r=g(h)=g(f(x))
- A loss function L computing a scalar L(r, x) measuring how good of r of a given input x. The objective is to minimize the expected value of L over the training set of examples {x}
Sparse coding
By Olshausen and Field, 1996
a particular form of inference:
h=f(x)=arghminL(g(h),x))+λΩ(h)
Where
- L is the reconstruction loss
- f is the (non-parametric) encoder
- g is the(parametric) decoder
What’s more:
To achieve sparsity, the optimized objective function includes a term that is minimized when the representation has many zero or near-zero values, such as the L1 penalty
|h|1=∑|hi|
An interesting variation of sparse coing
predictive sparse decomposition (PSD) (Kavukcuoglu et al., 2008)
About spare auto-encoders
Besides L1 penalty:
Student_t penalty
∑ilog(1+α2h2i)and KL-diverence penalty−∑i(tloghi+(1−t)log(1−hi))where t is a target sparsity level















 2528
2528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









