










序言
1. 内容介绍
本章介绍深度学习算法-自编码器,主要介绍自编码器的 原理、常见架构 以及 MNIST 数据集测试
2. 理论目标
- 自编码器 编码与解码 原理
- 自编码器 表示形式
- 欠完备自编码器 UAE
- 收缩自编码器 CAE
- 去噪自编码器 DAE 稀疏自编码器 SAE 等正则化编码器
3. 实践目标
- 掌握 自编码器 编码与解码 原理
- 掌握 自编码器 表示形式
- 掌握 欠完备自编码器
- 掌握 收缩自编码器
- 掌握 去噪自编码器、稀疏自编码器等正则化编码器
- 掌握 自编码器 用于 MNIST 的测试
4. 内容目录
- 1.自编码器简介
- 2.自编码器架构
- 3.PyTorch 代码复现
- 4.MNIST 数据集测试
第1节 自编码器简介
目前为止,前8章讨论神经网络在有 监督学习 (Supervised Learning) 中的应用,在此类学习中,所以训练样本都是有类别标签的。现在假设只有一个没有带类别标签的训练样本集合 \lbrace x^{(1)}, x^{(2)}, x^{(3)}, \ldots \rbrace{x(1),x(2),x(3),…},其中 x^{(i)} \in \Re^{n}x(i)∈ℜn, 自编码神经网络是一种 无监督学习 (Unsupervised Learning) 算法,它使用了反向传播算法,并让目标值等于输入值,比如 y^{(i)} = x^{(i)}y(i)=x(i)
1.1 自编码器起源
自编码器 (AutoEncoder) 在其研究早期是为解决表征学习中的 编码器问题 (Encoder Problem),即基于神经网络的降维问题而提出的联结主义模型的学习算法
- 1985 年,David H. Ackley、Geoffrey E. Hinton 和 Terrence J. Sejnowski 在玻尔兹曼机上对自编码器算法进行了首次尝试,并通过模型权重对其表征学习能力进行了讨论
- 1986 年,反向传播算法(Back Propagation, BP)被正式提出后,自编码器算法作为 BP 的实现之一,即 自监督的反向传播 (Self-Supervised BP)
- 1987 年,Jeffrey L. Elman 和 David Zipser 用于语音数据的表征学习试验
- 1987 年,Yann LeCun 发表的研究正式提出自编码器作为一类 神经网络 结构(包含编码器(Encoder)和解码器(Decoder)两部分,使用多层感知器(Multi-Layer Perceptron, MLP)构建了包含编码器和解码器的神经网络,并将其用于数据降噪。在同一时期,Bourlard and Kamp 使用 MLP 自编码器进行数据降维的研究
- 1994 年,Hinton 和 Richard S. Zemel 通过提出 最小描述长度原理(Minimum Description Length principle, MDL)构建了第一个基于自编码器的生成模型
- 自编码器的想法一直是神经网络历史景象的一部分, 传统自编码器被用于降维或特征学习
- 近年来,自编码器与潜变量模型理论的联系将自编码器带到了生成式建模的前沿。自编码器可以被看作是前馈网络的一个特例,并且可以使用完全相同的技术进行训练,通常使用小批量梯度下降法 (Mini-Batch SGD)
- 不同于一般的前馈网络,自编码器也可以使用再循环(recirculation)训练,这种学习算法基于比较原始输入的激活和重构输入的激活
1.2 自编码器原理
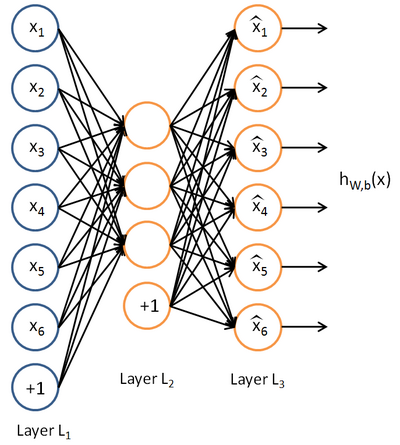
自动编码神经网络尝试学习一个 h_{W,b}(x) \approx xhW,b(x)≈x 的函数,换而言之,它尝试逼近一个 恒等函数,从而使得输出 \hat{x}x^ 接近于输入 xx。恒等函数虽然看上去不太有学习的意义,但是自编码神经网络加入某些限制,比如限定隐藏神经元的数量,就可以从输入数据中发现一些有趣的结构
举例来说,假设某个自动编码神经网络的输入 xx 是一张 10 \times 1010×10 图像, 即共 100 个像素灰度值,于是 n = 100n=100,其隐藏层 L_2L2 中有 5050 个隐藏神经元, 输出 yy 也是 100100 维的 \in \Re^{100}∈ℜ100。由于只有 5050 个隐藏神经元,迫使自动编码神经网络去学习输入数据的 压缩 表示,也就是说,它必须从 5050 维的隐藏神经元激活度向量 a^{(2)} \in \Re^{50}a(2)∈ℜ50 中 重构 出 100100 维的像素灰度值输入 xx。如果网络的输入数据是完全随机的,比如每一个输入 x_ixi 都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自动编码神经网络通常可以学习出一个跟主成分分析(PCA)结果非常相似的输入数据的低维表示
从直观上来看,自动编码器可以用于 特征降维,但是相比 PCA 其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器也可以起到 特征提取 器的作用
1.3 自编码器表示
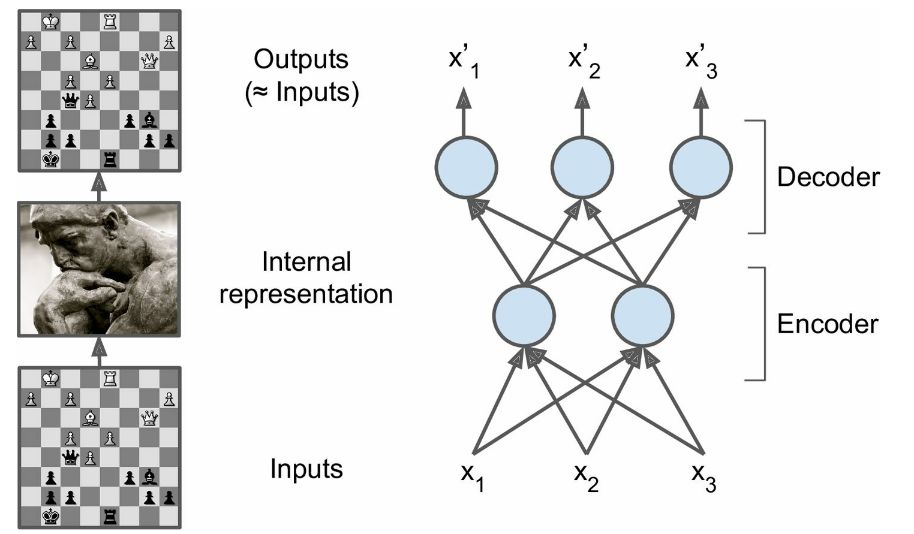
- 自动编码器是将输入 xx 进行编码,得到新的特征 \hat xx^ ,并且希望原始的输入 xx 能够从新的特征 yy 重构出来
\qquad\qquad y = f(Wx + b)y=f(Wx+b)
可以看到,和神经网络结构一样,其编码就是线性组合之后加上非线性的激活函数。如果没有非线性的包装,那么自动编码器就和普通的 PCA 没有本质区别
-
利用新的特征 yy ,可以对输入 xx 重构,即
\qquad\qquad\hat x = f(W'x + b')x^=f(W′x+b′)
-
为了使重构出的 \hat x \approx xx^≈x, 可以采用最小化负对数似然的损失函数来训练这个模型
\qquad\qquad \mathcal{L} = - \log P(x | \hat{x})L=−logP(x∣x^)
对于高斯分布的数据,采用均方误差,而对于伯努利分布可以根据似然函数推导采用交叉熵。一般情况下,会对自动编码器加上一些限制,常用的是使 W' = W^TW′=WT,这称为绑定权重 (Tied Weights)。有时候还会给自动编码器加上更多的约束条件,去噪自动编码器 以及 稀疏自动编码器 就属于这种情况,因为大部分时候单纯地重构原始输入并没有什么意义,反而自动编码器在近似重构原始输入的情况下能够捕捉到原始输入更有价值的信息
第2节 自编码器架构
所有自编码器的训练过程涉及两种推动力的 折中
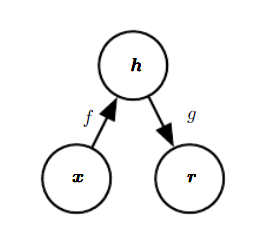
- 学习训练样本 xx 的表示 hh 使得 xx 能通过解码器近似的从 hh 中恢复
- 满足约束或正则惩罚
2.1 欠完备自编码器 UAE
将输入复制到输出听起来没什么用,但通常也不在意自解码器的输出,相反更重要的是,通过训练自编码器对输入进行复制而使隐藏单元 hh 获得有用的特性
从自编码器获得有用特征的一种方法是 限制 hh 的维度比输入 xx 小,这种编码维度小于输入维度的自编码器称为 欠完备自编码器 (Undercomplement AutoEncoder, UAE)。学习欠完备的表示将 强制 自编码器捕捉训练数据中最显著的特征
学习过程可以简单地描述为最小化一个损失函数
\qquad\qquad \color{red}{\mathcal{L}(x,g(f(x)))}L(x,g(f(x)))
其中 \mathcal{L}L 是一个损失函数,惩罚 \hat{x} \gets g(f(x))x^←g(f(x)) 与 xx 的差异,如均方误差。当解码器是线性的且 \mathcal{L}L 是均方误差,UAE 会学习出与 PCA 相同的生成子空间,即 UAE 在训练来执行复制任务的同时学到了训练数据的主元子空间
如果编码器和解码器被赋予过大的容量,自编码器会执行复制任务而捕捉不到任何有用信息
2.2 去噪自编码器 DAE
去噪自编码器(Denoising AutoEncoder, DAE)是一类接受损坏数据作为输入,并训练来预测原始未被损坏数据作为输出的自编码器。传统的自编码器最小化损失函数
\qquad\qquad\mathcal{L}(x,g(f(x)))L(x,g(f(x)))
上文已述,如果模型被赋予过大的容量,\mathcal{L}L 仅仅使得 g \circ fg∘f 学成一个恒等函数。相反,DAE 最小化
\qquad\qquad\color{red}{\mathcal{L}(x,g(f(\tilde{x})))}L(x,g(f(x~)))
其中 \tilde{x}x~ 是被某种 噪音 损坏 xx 的副本,因此 DAE 必须撤销这些损失,而不是简单地复制输入
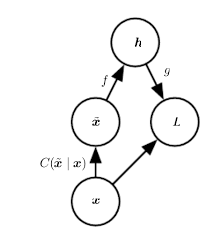
DAE 的计算过程为
- 从训练数据中采集一个样本 xx
- 从 C(\tilde{x} | x)C(x~∣x) 中采集一个损坏样本 \tilde{x}x~
- 将 (x, \tilde{x})(x,x~) 作为训练样本来估计自编码器的重构分布 p_{reconstruct}(x | \tilde{x}) = p_{decoder}(x | h)preconstruct(x∣x~)=pdecoder(x∣h),其中 hh 是编码器 f(\tilde{x})f(x~) 的输出,p_{decoder}pdecoder 根据解码函数 g(h)g(h) 定义
2.3 稀疏自编码器 SAE
之前的论述是基于隐藏神经元数量较小的假设,但是即使隐藏神经元的数量较大(可能比输入像素的个数还要多),仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。具体来说,如果给隐藏神经元加入 稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中的关联关系
稀疏性可以被简单地解释为如果当神经元的输出接近于 1 的时候认为它被 激活,而输出接近于 0 的时候认为它被 抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制
以上假设的神经元的激活函数是 sigmoid 函数; 如果使用 tanh 作为激活函数的话,当神经元输出为 -1 的时候,神经元是被抑制的
a^{(2)}_jaj(2) 表示隐藏神经元 jj 的激活度,但是这一表示方法中并未明确指出哪一个输入 xx 带来了这一激活度。所以需要使用 a^{(2)}_j(x)aj(2)(x) 来表示在给定输入为 xx 情况下,自编码神经网络隐藏神经元 jj,接下来让
\qquad\qquad\hat\rho_j = \frac{1}{m} \sum\limits^m_{i=1} a^{(2)}_j (x^{(i)})ρ^j=m1i=1∑maj(2)(x(i))
表示隐藏神经元 jj 在训练集上的平均活跃度,则可以近似的加入一条限制
\qquad\qquad\hat\rho_j = \rhoρ^j=ρ
\rhoρ 是 稀疏性参数,通常是一个接近于 00 的较小的值。例如假设 \rho = 0.05ρ=0.05, 即想要让隐藏神经元 jj 的平均活跃度接近 0.050.05。为了满足这一条件,隐藏神经元的活跃度必须接近于 00
为了实现这一限制,优化目标函数中将加入一个额外的 惩罚因子,而这一惩罚因子将惩罚那些 \hat\rho_jρ^j 和 \rhoρ 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,通常会选择
\qquad\qquad\sum\limits^{s_2}_{j=1} \rho \log \frac{\rho}{\hat\rho_j} + (1-\rho) \log \frac{1-\rho}{1-\hat\rho_j}j=1∑s2ρlogρ^jρ+(1−ρ)log1−ρ^j1−ρ
s_2s2 是隐藏层中隐藏神经元的数量,而索引 jj 依次代表隐藏层中的每一个神经元。如果对 相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是其的演变式,于是惩罚因子也可以被表示为
\qquad\qquad\sum\limits^{s_2}_{j=1} {\rm KL}(\rho || \hat\rho_j)j=1∑s2KL(ρ∣∣ρ^j)
其中 {\rm KL}(\rho || \hat\rho_j)= \rho \log \frac{\rho}{\hat\rho_j} + (1-\rho) \log \frac{1-\rho}{1-\hat\rho_j}KL(ρ∣∣ρ^j)=ρlogρ^jρ+(1−ρ)log1−ρ^j1−ρ 是一个以 \rhoρ 为均值和一个以 \hat\rho_jρ^j 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法
惩罚因子性质为当 \hat\rho_j = \rhoρ^j=ρ 时 {\rm KL}(\rho || \hat\rho_j) = 0KL(ρ∣∣ρ^j)=0,并且随着 \hat\rho_jρ^j 与 \rhoρ 之间的差异增大而单调递增
稀疏自编码器(Sparse AutoEncoder, SAE)是一类结合 稀疏惩罚 \Omega(h)Ω(h) 来训练预测原始数据作为输出的自编码器。SAE 最小化
\qquad\qquad\color{red}{\mathcal{L}(x,g(f(x))) + \Omega(h)}L(x,g(f(x)))+Ω(h)
\qquad\qquad\quad\Omega(h) = \lambda\sum\limits^{}_i |{h_i}|Ω(h)=λi∑∣hi∣
SAE 一般用来学习特征,以便用于像分类这样的任务, 其必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数
以这种方式训练,执行附带稀疏惩罚的复制任务可以得到能学习有用特征的模型
由于自编码器的潜在表示 yy 是对于输入 xx 的一种有损压缩, 优化和训练只能让它对于训练集合来说是很好的压缩表示,但并不是对于所有的输入都是这样。所以为了增加隐藏层的特征表示的鲁棒性和泛化能力,通常引入去噪自编码器 DAE
2.4 收缩自编码器 CAE
收缩自编码器 (Contractive AutoEncoder, CAE) 运用另外一种正则化自编码器策略,使用一个类似 SAE 中的惩罚项 \OmegaΩ
\qquad\qquad\color{red}{\mathcal{L}(x,g(f(x))) + \Omega(h,x)}L(x,g(f(x)))+Ω(h,x)
\qquad\qquad\quad\Omega(h,x) = \lambda\sum\limits^{}_i \left\|\nabla_xh_i\right\|^2Ω(h,x)=λi∑∥∇xhi∥2
迫使模型学习一个在 xx 变化小时,目标也没有太大变化的函数, 因为这个惩罚只对训练数据适用,迫使自编码器学习可以反应训练数据分布信息的特征
DAE 能抵抗小且有限的输入扰动,CAE 使特征提取函数能抵抗极小的输入扰动
CAE 鼓励将输入点领域映射到输出点处更小的领域
2.5 预测稀疏分解 PSD
预测稀疏分解 (Predictive Sparse Decomposition, PSD) 是稀疏编码和参数化自编码器的混合模型,训练算法交替的相对 hh 和模型的参数最小化如下式
\qquad\qquad\left\|x-g(h)\right\|^2 + \lambda|h|_1 + \gamma\left\|h-f(x)\right\|^2∥x−g(h)∥2+λ∣h∣1+γ∥h−f(x)∥2
预测稀疏分解是学习近似推断的一个例子, 详细解释在此章节不做多余展开
第3节 PyTorch 代码复现
3.1 定义 AE 模型网络
在此采用一个非常简单的 44 层架构,由于编码器网络多采用对称结构,所以此处也采用对称的结构进行搭建,输出的时候输出编码的结果以及解码的结果用于后续测试
# %load ae.py import torch import torch.nn as nn class AutoEncoder(nn.Module): def __init__(self): super(AutoEncoder,self).__init__() self.encoder = nn.Sequential( nn.Linear(28*28,128), nn.Tanh(), nn.Linear(128, 64), nn.Tanh(), nn.Linear(64, 32), nn.Tanh(), nn.Linear(32, 16), nn.Tanh(), nn.Linear(16, 3) ) self.decoder = nn.Sequential( nn.Linear(3,16), nn.Tanh(), nn.Linear(16, 32), nn.Tanh(), nn.Linear(32, 64), nn.Tanh(), nn.Linear(64, 128), nn.Tanh(), nn.Linear(128, 28*28), nn.Sigmoid() ) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return encoded,decoded
3.2 模型训练代码
加载同级目录下 train.py 程序代码
# %load train.py import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import time import argparse import sys import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from ae import build_ae from datasets.mnist import MNIST from datasets.fashion_mnist import FASHION_MNIST from datasets.config import FASHION_MNIST_ROOT, MNIST_ROOT parser = argparse.ArgumentParser( description='Convolutional Neural Network Training With Pytorch') train_set = parser.add_mutually_exclusive_group() parser.add_argument('--dataset', default='MNIST', choices=['MNIST', 'FASHION_MNIST'], type=str, help='MNIST or FASHION_MNIST') parser.add_argument('--dataset_root', default=MNIST_ROOT, help='Dataset root directory path') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--epoch_size', default=30, type=int, help='Number of Epoches for training') parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float, help='initial learning rate') parser.add_argument('--save_folder', default='weights/', help='Directory for saving checkpoint models') parser.add_argument('--photo_folder', default='results/', help='Directory for saving photos') args = parser.parse_args() if not os.path.exists(args.save_folder): os.mkdir(args.save_folder) if not os.path.exists(args.photo_folder): os.mkdir(args.photo_folder) def train(): if args.dataset == 'MNIST': if args.dataset_root == MNIST_ROOT: if not os.path.exists(MNIST_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = MNIST_ROOT dataset = MNIST(root=args.dataset_root,folder='train', transform=transforms.ToTensor()) elif args.dataset == 'FASHION_MNIST': if args.dataset_root == MNIST_ROOT: print("Using default FASHION_MNIST dataset_root") args.dataset_root = FASHION_MNIST_ROOT dataset = FASHION_MNIST(root=args.dataset_root,folder='train', transform=transforms.ToTensor()) net = build_ae(phase='train') optimizer = optim.Adam(net.parameters(), lr=args.lr) criterion = nn.MSELoss() epoch_size = args.epoch_size print('Loading the dataset...') data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) print('Training on:', dataset.name) print('Using model: AutoEncoder') print('Using the specified args:') print(args) loss_list = [] acc_list = [] for epoch in range(epoch_size): net.train() train_loss = 0.0 correct = 0 total = len(dataset) t0 = time.perf_counter() for step, data in enumerate(data_loader, start=0): images, labels = data images = images.view(-1,28*28) images_tilde = images.view(-1,28*28) # forward encoder,decoder = net(images) # backprop optimizer.zero_grad() loss = criterion(decoder, images_tilde) loss.backward() optimizer.step() # print statistics train_loss += loss.item() _, predicted = encoder.max(1) correct += predicted.eq(labels).sum().item() # print train process rate = (step + 1) / len(data_loader) a = "*" * int(rate * 50) b = "." * int((1 - rate) * 50) print("\rEpoch {}: {:^3.0f}%[{}->{}]{:.3f}".format(epoch+1, int(rate * 100), a, b, loss), end="") print(' Running time: %.3f' % (time.perf_counter() - t0)) acc = 100.*correct/ total loss = train_loss / step print('train loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) loss_list.append(loss) acc_list.append(acc/100) torch.save(net.state_dict(),args.save_folder + args.dataset + '.pth') plt.plot(range(epoch_size), loss_list, range(epoch_size), acc_list) plt.xlabel('Epoches') plt.ylabel('Sparse CrossEntropy Loss | Accuracy') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), args.photo_folder, args.dataset + "_train_details.png")) if __name__ == '__main__': train()
- dataset:
训练采用的数据集,目前提供MNIST ,FASHION_MNIST供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- batch_size:
单次训练所抓取的数据样本数量,default为32,MNIST数据集推荐参考为128
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- epoch_size:
训练次数, default为30
- cuda:
是否调用GPU训练
- lr:
超参数学习率,FNN采用Adam优化函数,default为 0.0010.001
- save_folder:
模型权重保存地址
- 训练细节
print 于 python console, 包括单个epoch训练时间、训练集损失值、准确率
- 模型权重
模型保存路径为 ./weight/%.pth
- 损失函数与正确率
图片保存路径为 ./photos/%_train_details.png
3.3 模型测试代码
加载同级目录下 test.py 程序代码
# %load test.py import sys import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import argparse import torch import torchvision.transforms as transforms import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.animation as animation from matplotlib import cm from mpl_toolkits.mplot3d import Axes3D mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from ae import build_ae from datasets.mnist import MNIST from datasets.fashion_mnist import FASHION_MNIST from datasets.config import FASHION_MNIST_ROOT, MNIST_ROOT parser = argparse.ArgumentParser( description='FeedForward Neural Network Testing With Pytorch') parser.add_argument('--dataset', default='MNIST', choices=['MNIST', 'FASHION_MNIST'], type=str, help='MNIST or FASHION_MNIST') parser.add_argument('--dataset_root', default=MNIST_ROOT, help='Location of MNIST root directory') parser.add_argument('--hidden_size', default=500, type=int, help='Hidden layer size') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--trained_model', default='weights/{}.pth', type=str, help='Trained state_dict file path to open') parser.add_argument('--cuda', default=True, type=bool, help='Use cuda to train model') parser.add_argument('-f', default=None, type=str, help="Dummy arg so we can load in Jupyter Notebooks") args = parser.parse_args() args.trained_model = args.trained_model.format(args.dataset) def show_dimensional_representation(images, labels, net): view_data = images[:200].view(-1, 28*28).type(torch.FloatTensor)/255. encoded_data, _ = net(view_data) fig = plt.figure(2) ax = Axes3D(fig) X = encoded_data.data[:, 0].numpy() Y = encoded_data.data[:, 1].numpy() Z = encoded_data.data[:, 2].numpy() values = labels[:200].numpy() for x, y, z, s in zip(X, Y, Z, values): c = cm.rainbow(int(255*s/9)) ax.text(x, y, z, s, backgroundcolor=c) ax.set_xlim(X.min(), X.max()) ax.set_ylim(Y.min(), Y.max()) ax.set_zlim(Z.min(), Z.max()) plt.show() plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), "results", args.dataset + "_dimensional_repr.png")) def show_comparison(images,net): plt.ion() plt.show() for i in range(10): test_data = images[i].view(-1,28*28).type(torch.FloatTensor)/255. _,result = net(test_data) im_result = result.view(28,28) plt.figure(1, figsize=(10, 3)) plt.subplot(121) plt.title('test_data') plt.imshow(images[i].numpy().squeeze(),cmap='Greys') plt.figure(1, figsize=(10, 4)) plt.subplot(122) plt.title('result_data') plt.imshow(im_result.detach().numpy(), cmap='Greys') plt.show() plt.pause(0.5) plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), "results", args.dataset + "_comparision.png")) plt.ioff() def test(): # load data if args.dataset == 'MNIST': if args.dataset_root == MNIST_ROOT: if not os.path.exists(MNIST_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = MNIST_ROOT dataset = MNIST(root=args.dataset_root,folder='test', transform=transforms.ToTensor()) elif args.dataset == 'FASHION_MNIST': if args.dataset_root == MNIST_ROOT: print("Using default FASHION_MNIST dataset_root") args.dataset_root = FASHION_MNIST_ROOT dataset = FASHION_MNIST(root=args.dataset_root,folder='test', transform=transforms.ToTensor()) data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) # load net net = build_ae(phase='test') net.load_state_dict(torch.load(args.trained_model)) print('Finish loading model: ', args.trained_model) net.eval() print('Training FFN on:', dataset.name) print('Using the specified args:') print(args) sample_images, sample_labels = next(iter(data_loader)) show_dimensional_representation(sample_images,sample_labels,net) show_comparison(sample_images,net) if __name__ == '__main__': test()
- dataset:
训练采用的数据集,目前提供MNIST ,FASHION_MNIST供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- batch_size:
单次训练所抓取的数据样本数量,default为32,MNIST数据集推荐参考为128
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- trained_model:
模型权重保存路径,default为 train.py 生成的ptb文件路径
- cuda:
是否调用GPU训练
- 三维聚类分析图
print 于 matplotlib 首个弹窗
- 输入与转码图像对比
print 于 matplotlib 后续弹窗
第4节 MNIST 数据集测试
-
MNIST 来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员,测试集(test set) 也是同样比例的 手写数字数据
-
MNIST 是机器学习领域中非常经典的一个数据集,由 60000 个训练样本和 10000 个测试样本组成,每个样本都是一张 28\times2828×28 像素的灰度手写数字图片
-
MNIST 已经是一个被”嚼烂”了的数据集, 作为机器学习在视觉领域的 hello world,很多教程都会对它”下手”, 几乎成为一个 “典范”
4.1 AE 训练结果
%run train.py --batch_size=128 --epoch_size=20
Loading the dataset...
Training on: MNIST
Using model: AutoEncoder
Using the specified args:
Namespace(batch_size=128, dataset='MNIST', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\MNIST', epoch_size=20, lr=0.001, num_workers=0, photo_folder='results/', save_folder='weights/')
Epoch 1: 100%[**************************************************->]0.068 Running time: 2.727
train loss: 0.072467, acc: 9.933% (5960/60000)
Epoch 2: 100%[**************************************************->]0.062 Running time: 2.712
train loss: 0.065726, acc: 9.928% (5957/60000)
Epoch 3: 100%[**************************************************->]0.053 Running time: 2.693
train loss: 0.057612, acc: 9.987% (5992/60000)
Epoch 4: 100%[**************************************************->]0.054 Running time: 2.680
train loss: 0.053796, acc: 11.967% (7180/60000)
Epoch 5: 100%[**************************************************->]0.050 Running time: 2.757
train loss: 0.051283, acc: 11.728% (7037/60000)
Epoch 6: 100%[**************************************************->]0.050 Running time: 2.721
train loss: 0.049714, acc: 11.760% (7056/60000)
Epoch 7: 100%[**************************************************->]0.051 Running time: 2.726
train loss: 0.048655, acc: 14.173% (8504/60000)
Epoch 8: 100%[**************************************************->]0.048 Running time: 2.699
train loss: 0.047522, acc: 13.845% (8307/60000)
Epoch 9: 100%[**************************************************->]0.044 Running time: 2.786
train loss: 0.045723, acc: 13.800% (8280/60000)
Epoch 10: 100%[**************************************************->]0.041 Running time: 2.733
train loss: 0.043869, acc: 16.388% (9833/60000)
Epoch 11: 100%[**************************************************->]0.040 Running time: 2.767
train loss: 0.042326, acc: 18.868% (11321/60000)
Epoch 12: 100%[**************************************************->]0.039 Running time: 2.791
train loss: 0.041145, acc: 21.045% (12627/60000)
Epoch 13: 100%[**************************************************->]0.038 Running time: 2.836
train loss: 0.040094, acc: 20.835% (12501/60000)
Epoch 14: 100%[**************************************************->]0.041 Running time: 2.729
train loss: 0.039158, acc: 20.695% (12417/60000)
Epoch 15: 100%[**************************************************->]0.037 Running time: 2.798
train loss: 0.038464, acc: 20.128% (12077/60000)
Epoch 16: 100%[**************************************************->]0.037 Running time: 2.727
train loss: 0.037818, acc: 20.020% (12012/60000)
Epoch 17: 100%[**************************************************->]0.038 Running time: 2.915
train loss: 0.037108, acc: 20.197% (12118/60000)
Epoch 18: 100%[**************************************************->]0.035 Running time: 2.743
train loss: 0.036513, acc: 20.140% (12084/60000)
Epoch 19: 100%[**************************************************->]0.034 Running time: 2.781
train loss: 0.035941, acc: 20.328% (12197/60000)
Epoch 20: 100%[**************************************************->]0.036 Running time: 2.912
train loss: 0.035511, acc: 20.182% (12109/60000)
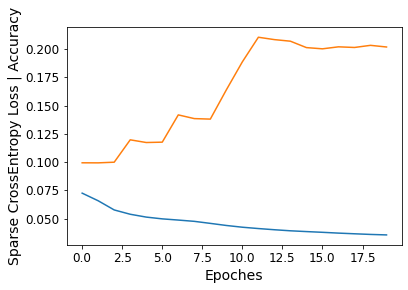
4.2 AE 图像测试
%run test.py --batch_size=128
Finish loading model: weights/MNIST.pth
Using the specified args:
Namespace(batch_size=128, cuda=True, dataset='MNIST', dataset_root='C:\\Users\\sbzy\\Documents/GitHub/dl_algorithm/datasets\\MNIST', f=None, hidden_size=500, num_workers=0, trained_model='weights/MNIST.pth')
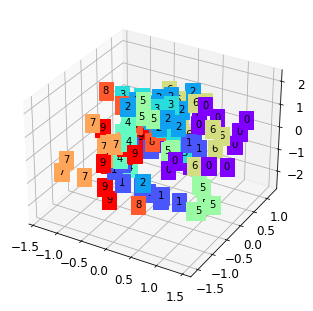
<Figure size 432x288 with 0 Axes>
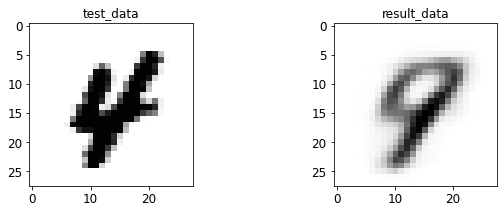

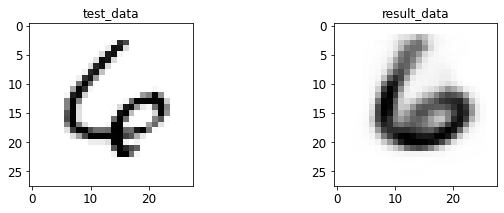
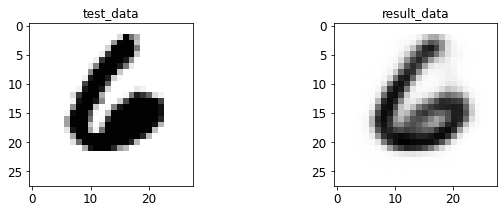
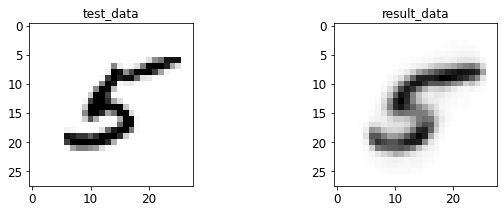
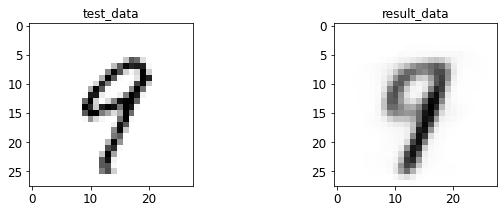
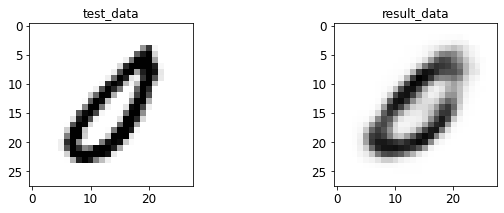
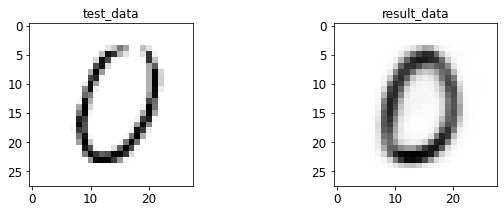

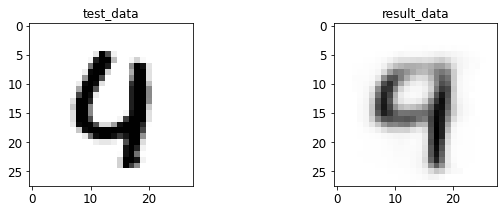

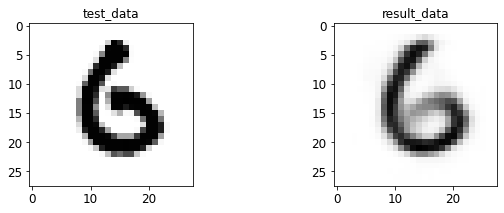
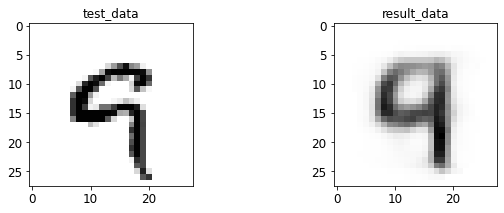
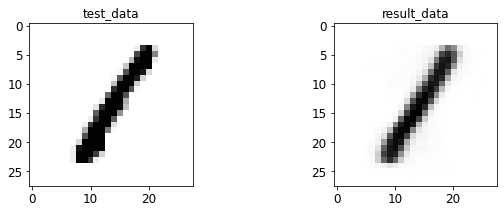
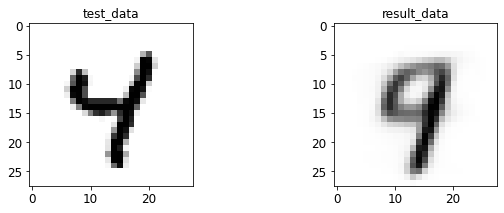
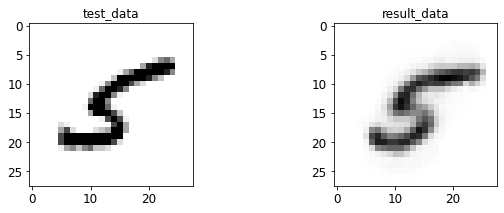
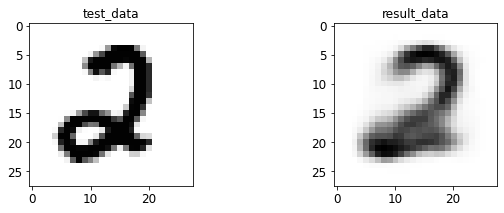
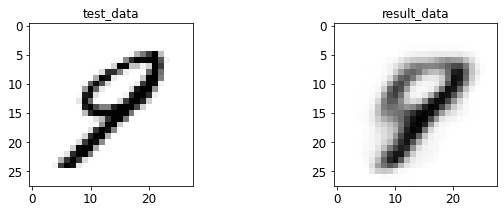

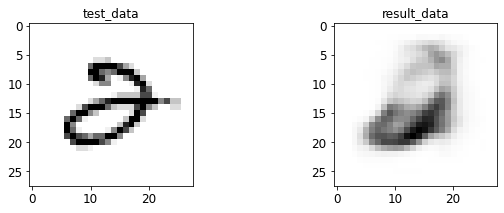
<Figure size 432x288 with 0 Axes>
开始实验
















 833
833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











