







Title:Convolutional Pose Machines
1 Summary
整体来说结构很清晰,不同的CNN块有不同的分工,通过CNN 拟合key points,加上了中间监督模块方式模型过深导致梯度消失的问题。
2 Research Objective(s)
- model long range dependencies between variables in structed prediction task.
3 Problem Statement
key problem: feature representations for both image, spatial context
- using CNN 一个序列化的卷积网络,它以之前阶段输出的belief maps为输入,一级级地生成越来越准确的骨架估计,而不需要显式地进行图形化模型推理。
4 Method(s) 作者解决问题的方法/算法是什么?
- 在CPM的每个特定阶段,belief maps所包含的空间上下文信息会为之后的阶段提供明确的线索(cues),因此CPM的每个阶段会产生越来越好的maps来对关节进行越来越准确的定位(见图1)。Note: 卷积的时候感受野越大越能捕获到远距离的上下文关系,因此在整个卷积过程中,都保持着最大感受野。
- add intermediate supervision periodically through the network to produce increasingly accurate belief maps
4.1 前人的工作:
- 图形结构模型(pictorial structures)
身体各个部分(关节和肢体)的空间关系表示为具有运动学先验(哪些四肢应该相连)的树状图形模型。这些方法在那些所有肢体都可见的图像中效果是很好的,但是当树状结构模型没有捕获到变量间的关系时,这种方法就会出现特征错误。- 层级模型(Hierarchical models)
层级模型表示的是不同尺度、尺寸的parts之间的关系。这些模型的基本假设是较大的部分(对应于四肢而不是关节)通常具有易区分的图像结构,可以更容易检测出来,进而有助于推断较小的、更难检测的部分。- 非树模型
非树模型结合交互作用,引入循环来增强带有额外边的树结构,这些额外的边可以捕获对称性、遮挡和长距离关系。这些方法不论是在训练还是在测试的时候,通常必须使用近似推理,因此不得不去平衡空间关系精确建模与推理有效性之间的关系,一般都是使用简单的参数形式来进行快速推理。(4)基于顺序化预测的方法(methods based on a sequential prediction)[29] 相比之下,基于顺序化预测的方法通过直接训练推理过程来学习隐式空间模型,其中变量之间可能具有复杂的交互关系。- 卷积结构
最近很多方法还是使用卷积结构来完成姿态估计任务[6,7,23,24,28,38,39]。例如Toshev等人[40]使用标准的卷积结构直接回归笛卡尔坐标。 最近的工作将图像回归为置信度图(confidence maps),并应用到图形学模型中,这需要手工设计能量函数或者空间概率先验的启发式初始化来去除回归置信度图上的离群值;它们中的一些还使用专门的网络模块来进行精度细化(refinement)。
假设目标可以分成
p
p
p个部分,那么目标的各个部分坐标可以表示为
Y
=
(
Y
1
,
.
.
.
,
Y
P
)
Y=(Y_1, ..., Y_P)
Y=(Y1,...,YP),而我们目标就是为了预测这
P
P
P个part的坐标。在传统的pose machine中,由一系列multi-class predicttors组成。
g
(
⋅
)
g(·)
g(⋅)是可以训练的,用于预测 location of each part in each level of the hierarchy.

每一步中
g
t
g_t
gt都在 brief 中预测 part 的 location。具体来说,第
t
t
t阶段,
g
t
g_t
gt都吃两个东西,一个是根据当前图像得到的坐标信息,第二个就是之前计算出来的坐标信息(
t
t
t阶段每个位置
Y
P
Y_P
YP的邻域的上下文信息)。
g
t
g_t
gt的输出是:每个parts 在图像
z
z
z处位置的概率。其中,这个
z
z
z可以取图上中的任意一点。
其中,
p
p
p部分在各个点的概率表示为下面这个式子
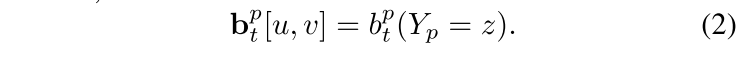
这样的话,图片中每个像素其实都是
p
+
1
p+1
p+1个类(P个part+1个background),所以
b
t
\bold{b}_t
bt的维度应该就是
w
×
h
×
(
P
+
1
)
w \times h \times (P+1)
w×h×(P+1),其中
w
w
w,
h
h
h就分别为图像的宽和高。
那么对于第一帧来说(没有先前的知识),公式化表示一下就是
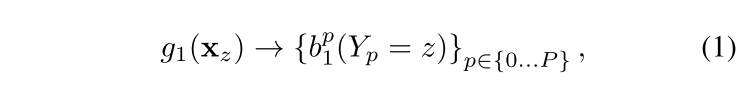
对于后续帧来说,表达式就是这样的
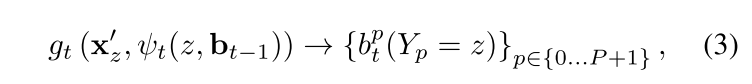
在上式中,
ψ
t
>
1
\psi_{t>1}
ψt>1代表一个映射,可以将
b
t
−
1
\bold{b}_{t-1}
bt−1映射到context feature
(论文在这里定义、解释了一大堆,现在来看其实就是heatmaps,各通道表示各关键点在每个像素位置处的概率)
4.2 作者的方法
4.2.1 Keypoint Localization Using Local Image Evidence

思想:先简单用five convolutional layers followed by two 1 × 1 convolutional layer生成一个part detection,这个part detection 是一个local 的,因为感知野是一个输出像素位置附近的一个small patch。
应用:输入图像大小为:368 x 368,感知野大小为160 x 160像素,整个网络可以看成一个在图像上滑动的 deep network,这个deep network的作用是从每个160x160的图片中regress
P
+
1
P+1
P+1个output vector,这个output vector代表each part的score。
4.2.2 Sequential Prediction with Learned Spatial Context Features
对于对于具有外观一致性的关键点(例如头和肩膀)的检测率还不错,但是对于在人体骨骼运动链中处于较低位置的关键点来说,精度要低得多,这是由于它们外观变化很大。我们发现,关键点周围的heatmaps虽然噪声很多,但是信息量也很大。如图3所示,当检测具有挑战性的关键点(例如右肘)时,右肩的heatmaps具有尖峰(右肩检测的比较好),这可以作为右肘检测的强有力信息。
作者发现大的感知野精度更高。We found that our stride-8 network performs as well as a stride-4 one even at high precision region, while it makes us easier to achieve larger receptive fields.
4.2.3. Learning in Convolutional Pose Machines
整体网络的需求:
- 足够大的感知野(参数量可能过多)
- 足够多的卷积网络(梯度消失问题)
- 总共有6个阶段
- loss定义为每个stage
t
t
t 生成的brief map和ideal brief map的
l
2
l_2
l2距离(The ideal belief map for a part
p
p
p is written as
b
∗
P
(
Y
p
=
z
)
b_*^P(Y_p=z)
b∗P(Yp=z), which are created by putting
Gaussian peaks at ground truth locations of each body part p p p.)
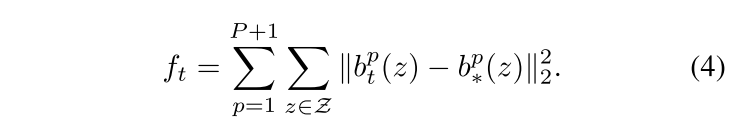
整个网络的loss为:
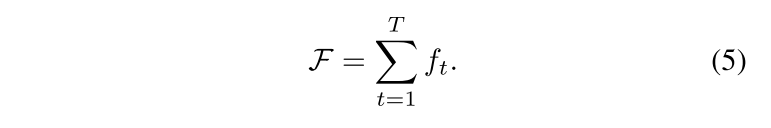
5. Evaluation
- addressing vanishing gradients
each term in the summation is applied to the network after each stage t effectively enforcing supervision in intermediate stages through the network - Benefit of end-to-end learning.
- Comparison on training schemes: a global loss function + enforces intermediate supervision
6. Conclusion
- strong conclusion:
CPM is capable of learning a spatial models for pose by communicating increasingly refined uncertainty-preserving beliefs between stages.
we do observe failure cases mainly when multiple people are in close proximity.
6. Notes(optional)
- 在keypoint施加一个高斯函数作为引导关键点的搜寻
- 强行中间监督方法解决梯度消失的问题
- 通过级联的方式不断抽取特征
- 数据集链接其中包含了14个关键点,每个关键点由[x, y, isvisible]三个值组成,is_visible是这个点是否可见
- 代码链接
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









