







前言
本文参考了wiki百科、周志华《机器学习》、论文GraphSage、博文《Inductive vs. Transductive Learning》。
简介
在 kipf-GCN 和 GraphSage 中,对 Transductive Learning 和 Inductive Learning 有了比较深刻的认识。
kipf-GCN 在其论文中提到算法属于 transductive node classification,也就是在训练节点embedding的时候要看到全图的节点,这是因为kipf-GCN使用了拉普拉斯矩阵。kipf-GCN 的半监督指的是只知道少部分节点的标签信息。基于 transductive 的 kipf-GCN 不会自然泛化到看不见的节点。
GraphSAGE 学习了一个聚合函数,该函数通过从节点特征信息(例如,文本属性)及本地邻域抽样和聚合特征来生成嵌入。可以有效地为训练期间看不见的数据生成embedding。
在周志华的《机器学习》半监督一节1中,也提到了transductive learning,翻译为直推学习,其解释为
半监督学习可进一步分为纯(pure)半监督学习和直推学习(transductive learning),前者假定训练数据中的未标记样本并非带预测的数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。换言之,纯半监督学习是基于“开放世界”假设,希望学到的模型能适用于训练过程中未观察到的数据;直推学习是基于“封闭世界”假设,仅试图对学习过程中观察到的未标记样本进行预测。
图示如下:
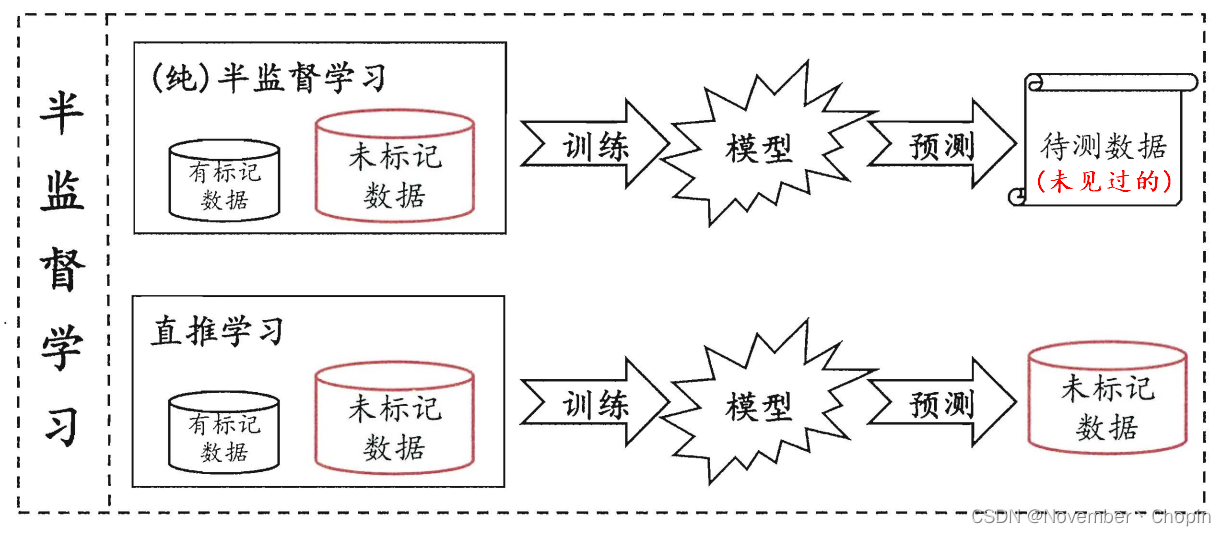
文中的(纯)半监督学习,可以理解为 Inductive Learning。当然,Transductive Learning 和 Inductive Learning 的概念并不局限于半监督学习。
Transductive Learning 的例子包括kipf-GCN、基于图的标签传播算法( Label Propagation Algorithm,LPA)。
Inductive Learning 的例子包括我们接触的绝大多数例子,比如CV中经典的ResNet图像分类、FaceNet人脸识别等。
定义
Transduction 是从观察到的、特定的训练样本到特定的测试的推理。
Induction 是从观察到的训练样本生成规则推理,然后将规则推理应用于测试样本。
Inductive learning 与我们通常所知的传统监督学习相同。基于已经拥有的标记训练数据集构建和训练机器学习模型。然后我们使用这个训练过的模型来预测以前从未遇到过的测试数据集的标签。
Transductive learning 事先看到了所有数据,包括训练和测试数据集。通常训练集是带标签的数据,测试集是不带标签的数据。从已经观察到的训练集和测试集中学习,然后预测测试数据集的标签。在训练过程中,使用的是测试集中除了标签以外的其他信息,比如在图中测试数据的结构信息(参见kipf-GCN)。
两者区别
| \qquad | \qquad Transductive Learning | \qquad Inductive Learning |
|---|---|---|
| 数据 | 训练模型时已经遇到了训练和测试数据集 | 在训练模型时只遇到训练数据,并将学习到的模型应用在它从未见过的数据集上。 |
| 模型 | 不会构建预测模型,如果测试数据集中添加了新的数据点,那么我们将不得不从头开始重新运行算法,训练模型然后用它来预测标签 | 构建预测模型,当你遇到新的数据点时,不需要从头开始重新运行算法。 |
| 总结 | 建立一个模型,适合它已经观察到的训练和测试数据点。这种方法利用标记点的知识和附加信息预测未标记点的标签。 | 试图建立一个通用模型,根据观察到的一组训练数据点来预测任何新的数据点 |
在输入流引入新数据点的情况下,Transductive Learning 可能会变得昂贵。每次新的数据点到达时,都必须重新运行所有内容。另一方面,Inductive Learning最初建立一个预测模型,新的数据点可以在很短的时间内用更少的计算来标记。
节点分类的例子
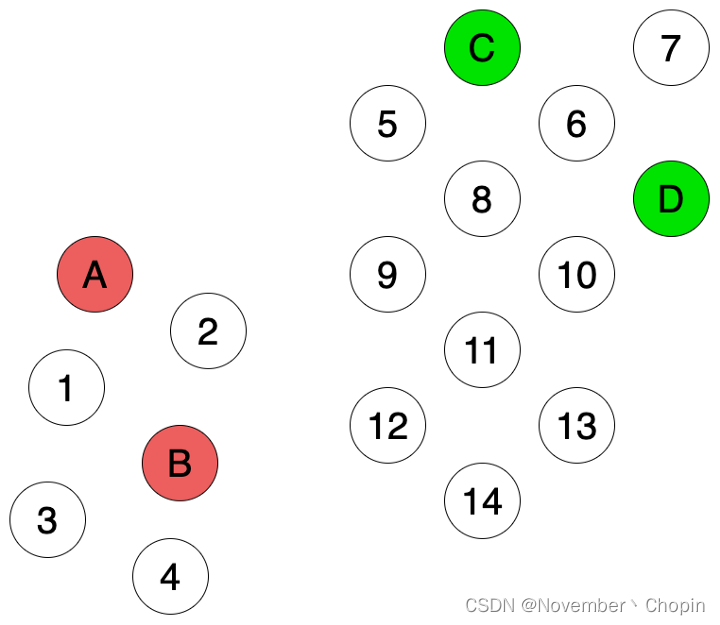
如图1所示,有A、B、C、D 四个有有标注的点。任务是基于现有信息给图中1~14的节点进行分类,称之为节点分类任务(node classification)。
Inductive Learning
如果使用Inductive Learning,将只使用A、B、C、D 四个点的标注信息,构建一个监督学习模型。比如基于SVM或KNN,我们将得到如下结果:
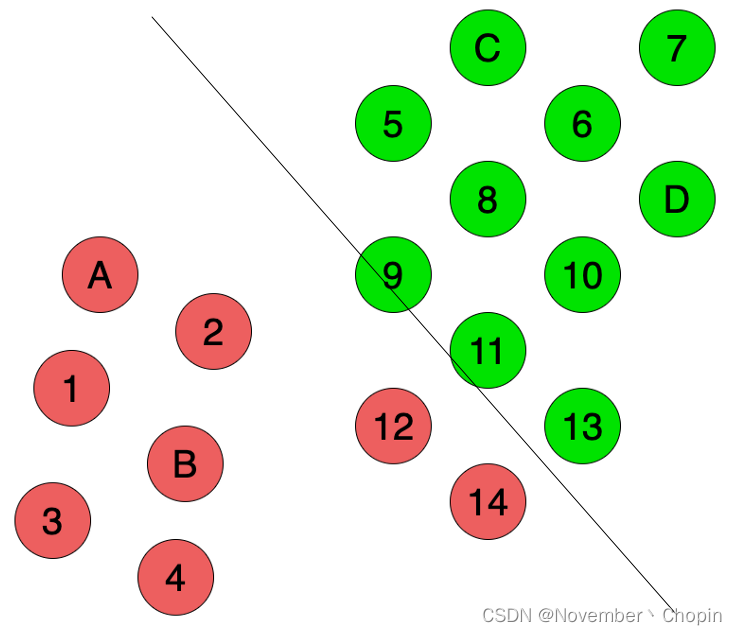
但很多时候,我们的训练样本很少,训练样本与整体样本的分布不一致,所以很难构建一个能捕捉数据完整结构的模型。
Transductive Learning
如果我们有一些关于数据点的附加信息,例如基于相似性等特征的点之间的连接信息(如图3所示),我们可以在训练模型和标记未标记点时使用这些附加信息。
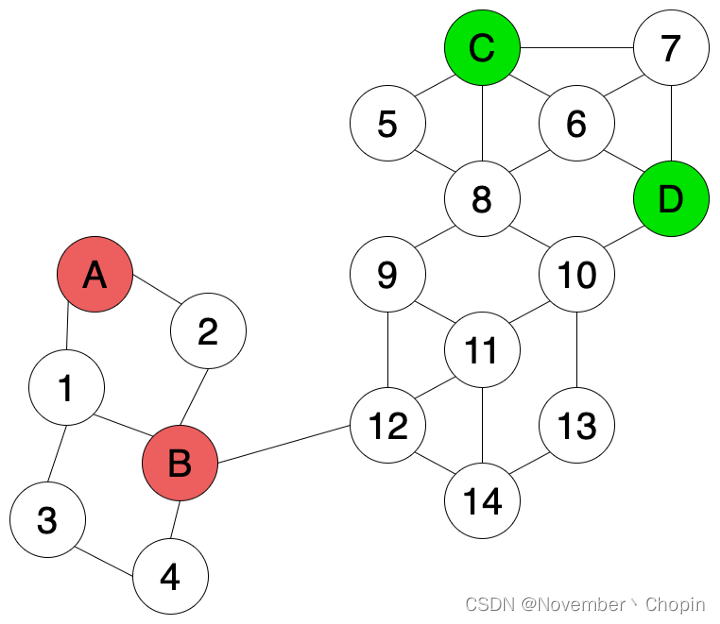
可以使用Transductive的方法如 基于图的半监督标签传播算法 或 kipf-CGN中提出的半监督的图卷积神经网络。如图4,使用了有标注数据和未标注数据的结构信息,,可以更好地识别图中的节点标签。因此节点12和节点14会被判定为绿色而不是红色。
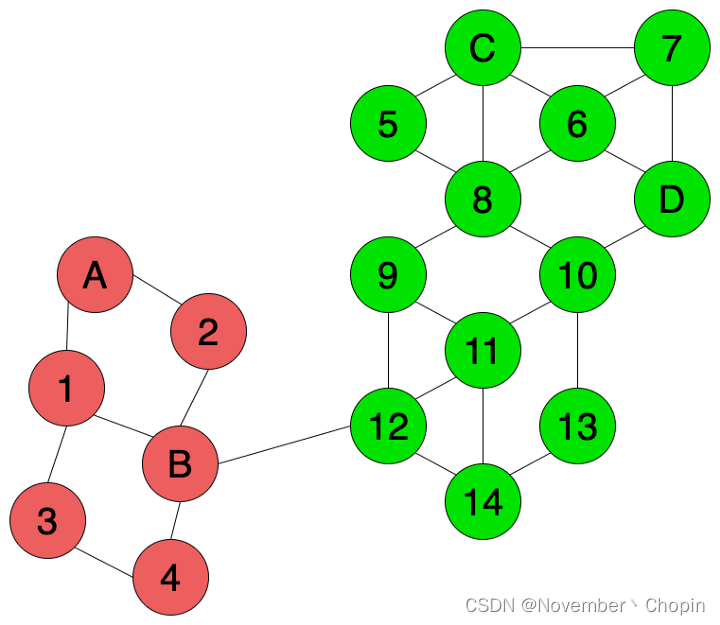
需要注意的是,因为我们一开始就知道了所有的训练和测试数据,如果不知道测试数据的话,那么就只能使用Inductive Learning。
《机器学习》,周志华 “第13章半监督学习” ,p295. ↩︎
















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









