







浮点数是一种用二进制表示的实数,它由三个部分组成:sign(符号位)、exponent(指数位)和fraction(小数位)。不同的浮点数格式有不同的位数分配给这三个部分,从而影响了它们能表示的数值范围和精度。例如:
1、FP16
FP16也叫 float16,全称是Half-precision floating-point(半精度浮点数),在IEEE 754标准中是叫做binary16,简单来说是用 16位二进制(16 bit,2 byte) 来表示的浮点数,如图:

FP16一共有 16 位二进制,由三部分组成,其中:
- Sign(符号位): 1 位,0表示整数;1表示负数。
- Exponent(指数位):5位,表示整数部分,范围为00001(1)到11110(30),正常来说整数范围就是 2 1 − 2 30 2^1-2^{30} 21−230 。但为了指数位能够表示负数,在指数的基础上引入了一个偏置值,在二进制16位浮点数中,偏置值是 15,这个偏置值确保了指数位可以表示从-14到+15的范围即 2 − 14 − 2 15 2^{-14}-2^{15} 2−14−215 ,而不是1到30
注:当指数位都为00000和11111时,它表示的是一种特殊情况,在IEEE754标准中叫做非规范化情况,后面可以看到这种特殊情况怎么表示的。
- Fraction(尾数位):10位,表示小数部分,存储的尾数位数为10位,但其隐含了首位的1,实际的尾数精度为11位,这里的隐含位可能有点难以理解,通俗来说,假设尾数部分为1001000000,为默认在其前面加一个1,最后变成1.1001000000然后换成10进制就是:
# 第一种计算方式
1.1001000000 = 1 * 2^0 + 1 * 2^(-1) + 0 * 2^(-2) + 0 * 2^(-3) + 1 * 2^(-4) + 0 * 2^(-5) + 0 * 2^(-6) + 0 * 2^(-7) + 0 * 2^(-8) + 0 * 2^(-9) = 1.5625
# 第二种计算方式
1.1001000000 = 1 + 576(1001000000变成10进制)/1024 = 1.5625
所以 fp16 转换成十进制有两种方式:

举一个例子来计算,这个是FP16(float16)能表示的最大的正数:
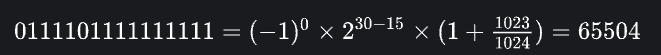
例如,FP16(float16)能表示最小的正数:

这就是FP16(float16)表示的范围[-65504,65504]。
贴一个FP16(float16)特殊数值的情况:
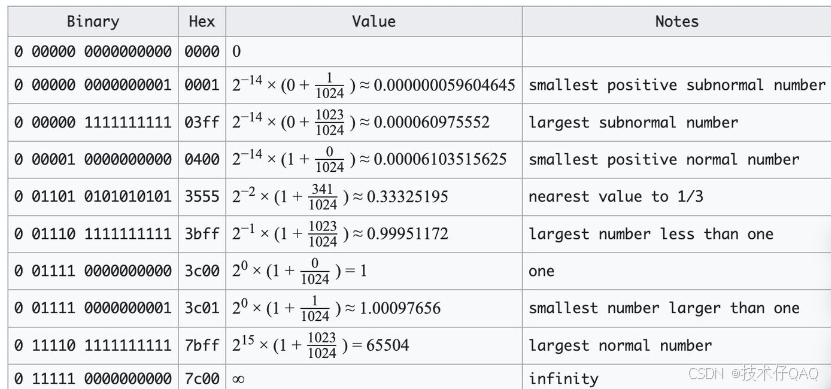
接下来看一下在pytorch中是如何表示 fp16 的:
torch.finfo(torch.float16)
# 结果
finfo(resolution=0.001, min=-65504, max=65504, eps=0.000976562, smallest_normal=6.10352e-05, tiny=6.10352e-05, dtype=float16)
其中:
- resolution(分辨率):这个浮点数类型的在十进制上的分辨率,表示两个不同值之间的最小间隔。对于 torch.float16,分辨率是 0.001,就是说两个不同的 torch.float16 数值之间的最小间隔是 0.001。
- min(最小值):对于 torch.float16,最小值是 -65504。
- max(最大值):对于 torch.float16,最大值是 65504。
- eps(机器精度):机器精度表示在给定数据类型下,比 1 大的最小浮点数,对于 torch.float16,机器精度是 0.000976562,对应上表中的smallest number larger than one。
- smallest_normal(最小正规数):最小正规数是大于零的最小浮点数,对于 torch.float16,最小正规数是 6.10352e-05,对应上表中的smallest positive normal number
- tiny(最小非零数):最小非零数是大于零的最小浮点数,对于 torch.float16,最小非零数也是 6.10352e-05,也是对应上表中的smallest positive normal number
这里简单解释下为什么fp16的resolution(分辨率)为0.01?
因为在计算机中 float16值 是以2进制存储计算的,而 float16 所能表示的最小值为 2^{-10}=0.0009765625,近似等于0.001,所以当10进制数的变化超过 0.001 时 float16 值才有变化。
2、BF16
BF16也叫做bfloat16(这是最常叫法),全称brain floating point,也是用 16位二进制(16 bit,2 byte) 来表示的,和FP16不一样的地方就是指数位和尾数位所占用的位数不一样:

其中:
- Sign(符号位): 1 位,0表示整数;1表示负数
- Exponent(指数位):8位,表示整数部分,偏置值是 127
- Fraction(尾数位):7位,表示小数部分,也是隐含了首位的1,实际的尾数精度为8位
计算公式:

看一下在pytorch中是如何表示的:
import torch
torch.finfo(torch.bfloat16)
# 结果
finfo(resolution=0.01, min=-3.38953e+38, max=3.38953e+38, eps=0.0078125, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=bfloat16)
每个字段的含义和上述是一致的,主要注意的是bfloat16的10进制间隔精度是0.01(注:在-1~1之间精度是0.001),表示范围是[-3.40282e+38,3.40282e+38]。可以明显的看到bfloat16比float16精度降低了但是表示的范围更大了,能够有效的防止在训练过程中的溢出。
3、FP32
FP32也叫做 float32,全称是Single-precision floating-point(单精度浮点数),在IEEE 754标准中是叫做binary32,简单来说是用 32位二进制(32 bit,4 byte) 来表示的浮点数:

其中:
- Sign(符号位): 1 位,0表示整数;1表示负数
- Exponent(指数位):8位,表示整数部分,偏置值是 127
- Fraction(尾数位):23位,表示小数部分,也是隐含了首位的1,实际的尾数精度为24位
计算公式:

在pytorch中的表示:
import torch
torch.finfo(torch.float32)
# 结果
finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32)
每个字段的含义和上述是一致的,主要注意的是float32的10进制间隔精度是0.000001(注:在-1~1之间精度是0.0000001),表示范围是[-3.40282e+38,3.40282e+38]。可以看到float32精度又高,范围又大,可是32位的大小对于现在大模型时代的参数量太占空间了。
4、不同精度的显存占用
以显卡NVIDIA A40 48G,模型用llama-2-7b-hf,这个模型保存的精度通过查看模型文件的congfig.json可以看到是"torch_dtype": “float16”。
打印相关的版本和显卡信息:
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 打印版本号
print("transformers version:", transformers.__version__)
print("torch version:", torch.__version__)
# 检查系统中是否有可用的 GPU
if torch.cuda.is_available():
# 获取可用的 GPU 设备数量
num_devices = torch.cuda.device_count()
print("可用 GPU 数量:", num_devices)
# 遍历所有可用的 GPU 设备并打印详细信息
for i in range(num_devices):
device = torch.cuda.get_device_properties(i)
print(f"\nGPU {i} 的详细信息:")
print("名称:", device.name)
print("计算能力:", f"{device.major}.{device.minor}")
print("内存总量 (GB):", round(device.total_memory / (1024**3), 1))
else:
print("没有可用的 GPU")
输出如下:
transformers version: 4.32.1
torch version: 2.0.1+cu117
可用 GPU 数量: 1
GPU 0 的详细信息:
名称: NVIDIA A40
计算能力: 8.6
内存总量 (GB): 44.4
然后用transformers加载模型,精度设为float16:
# 加载模型
model_name = "/path/to/llama-2-7b-hf" # 你模型存放的位置
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda:0", torch_dtype=torch.float16)
加载模型后,查看模型的总参数:
total_parameters = model.num_parameters()
print("Total parameters in the model:", total_parameters)
# 结果
Total parameters in the model: 6738415616 # 6.73B
- 以float16进行加载,也就是每个参数16个bit,2个byte,计算一下参数占多少显存:
# 计算每个参数的大小(以字节为单位)
size_per_parameter_bytes = 2
# 计算模型在显存中的总空间(以字节为单位)
total_memory_bytes = total_parameters * size_per_parameter_bytes
# 将字节转换为更常见的单位(GB)
total_memory_gb = total_memory_bytes / (1024**3)
print("Total memory occupied by the model in MB:", total_memory_gb)
# 结果
Total memory occupied by the model in GB: 12.551277160644531
打印GPU上模型的显存占用:
# 计算模型的显存占用
memory_allocated = torch.cuda.memory_allocated(device='cuda:0')
# 将字节转换为更常见的单位(GB)
memory_allocated_gb = memory_allocated / (1024**3)
print("Memory allocated by the model in GB:", memory_allocated_gb)
# 结果
Memory allocated by the model in GB: 12.582542419433594
可以看到 llama-2-7b-hf 模型有7B(70亿)个参数,其在参数类型为 float16 时(每个参数占2字节),加载模型占用的显存大约为 12.6 GB。
- 再看一下使用bfloat16加载的结果:
# 加载模型float32
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda:0", torch_dtype=torch.bfloat16)
......
# 结果
Total memory occupied by the model in GB: 12.551277160644531
Memory allocated by the model in GB: 12.582542419433594
可以看到bfloat16和float16占用的显存是完全一样的,也是12.6GB。
- 再看一下在float32下加载的情况:
# 加载模型float32
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda:0", torch_dtype=torch.float32)
......
# 结果
Total memory occupied by the model in GB: 25.102554321289062
Memory allocated by the model in GB: 25.165069580078125
可以看到 llama-2-7b-hf 模型有7B(70亿)个参数,其在参数类型为 float32 时(每个参数占4字节),加载模型占用的显存大约为 25.2 GB。
5、不同精度之间的转换
从huggingface下载的llama-2-7b-hf模型,通过查看模型文件的congfig.json可以看到是"torch_dtype": “float16”,那为何加载的时候可以指定float32和bfloat16呢?是如何转化的呢?
在加载模型时torch内置了转换函数,将模型的每一个参数进行类型转换,如下:
5.1 float16转化为float32
- 函数 float()
# 以float16加载
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda:0", torch_dtype=torch.float16)
# 计算模型的显存占用
memory_allocated = torch.cuda.memory_allocated(device='cuda:0')
# 将字节转换为更常见的单位(GB)
memory_allocated_gb = memory_allocated / (1024**3)
print("Memory allocated by the model in GB:", memory_allocated_gb)
# 转为float32
model.float()
# 计算模型的显存占用
memory_allocated = torch.cuda.memory_allocated(device='cuda:0')
# 将字节转换为更常见的单位(GB)
memory_allocated_gb = memory_allocated / (1024**3)
print("Memory allocated by the model in GB:", memory_allocated_gb)
# 结果
Memory allocated by the model in GB: 12.582542419433594
Total memory occupied by the model in GB: 25.165069580078125
5.2 float32转化为float16
- 函数 half()
# 以float32加载
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda:0", torch_dtype=torch.float32)
# 计算模型的显存占用
memory_allocated = torch.cuda.memory_allocated(device='cuda:0')
# 将字节转换为更常见的单位(GB)
memory_allocated_gb = memory_allocated / (1024**3)
print("Memory allocated by the model in GB:", memory_allocated_gb)
# 转为float16
model.half()
# 计算模型的显存占用
memory_allocated = torch.cuda.memory_allocated(device='cuda:0')
# 将字节转换为更常见的单位(GB)
memory_allocated_gb = memory_allocated / (1024**3)
print("Memory allocated by the model in GB:", memory_allocated_gb)
# 结果
Memory allocated by the model in GB: 25.165069580078125
Total memory occupied by the model in GB: 12.551277160644531

















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









