







- 概念很简单,公式很复杂,要想学得好,还得看代码。
- 基于动态规划的强化学习算法主要有两种:一是策略迭代(policy iteration),二是价值迭代(value iteration)。
- 策略迭代由两部分组成:策略评估(policy evaluation)和策略提升(policy improvement)
- 策略评估的是状态价值。评估这个策略在每个状态的价值,然后才能计算出action价值,然后才能取最大的action,最后提升策略。
- 一个策略的好坏,其实朴素的思想就是,做的action是不是最优的。
- 转移矩阵,在当前state,做了action后的奖励与下一个状态。
- 策略迭代是策略评估( loss)和策略提升(梯度下降)不断循环交替,直至最后得到最优策略的过程。
- 其实就是每一轮都选择最好的action,那为啥要计算状态价值,因为action价值是状态价值计算过来的。
- 策略评估这一过程用来计算一个策略的状态价值函数。
- 策略评估是多轮迭代的。
- 可以看到,当知道奖励函数和状态转移函数时,我们可以根据下一个状态的价值来计算当前状态的价值。更一般的,考虑所有的状态,就变成了用上一轮的状态价值函数来计算当前这一轮的状态价值函数。
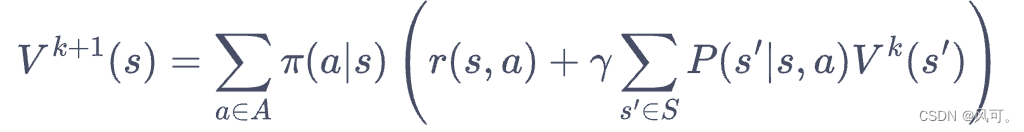
- 策略提升(策略就是action的集合),如果我们在状态s下面采取某个action比当前的状态价值高,那么这个状态就是最好的。注:因为状态价值是所有动作的价值的加权平均。所以取最大的价值就会超过平均数。所以选最好的action就会提升我们的策略,这就叫策略提升(看起来好简单,写成公式就很复杂)。
- 于是我们可以直接贪心地在每一个状态选择动作价值最大的动作(大括号里面的),也就是

- 策略迭代算法(就和梯度下降差不多)
- 初始化:状态价值v初始化价值为0, 策略π初始化为均匀随机策略
- 价值迭代算法,可以看做是只有一轮策略提升的策略迭代算法。
- 价值迭代是直接贪婪的往最大的state value走。(贪心策略)
- 策略迭代是取最大的action value的action。
- 这两个有点像,因为action value就是下一个state value计算得到的。
- 其实上面动态规划这种方法还没有进行交互,我觉得只能算是数学上的计算,而不像是交互。如果智能体无法事先得知奖励函数和状态转移函数,就只能通过和环境进行交互来采样(状态-动作-奖励-下一状态)这样的数据
- 其实动态规划算是greedy的算法,每次都是选最好的action,而不好的不会去选。如果带上埃普西隆-greedy,那么即使是差的也可能选。所以动态规划只适用于环境模型确定的情况,应为只有确定的情况才能知道哪个action是百分百最优的。















 1786
1786
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









