







《Learning Deconvolution Network for Semantic Segmentation》阅读笔记
FCN
首先论文对比《Fully convolutional networks for semantic segmentation》提到的FCN:
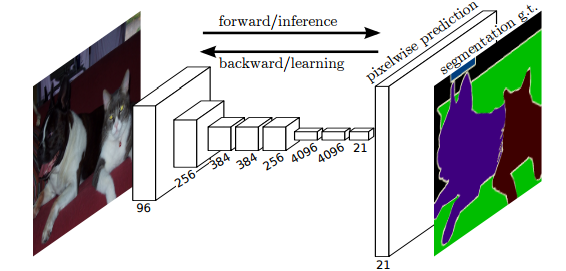
基于CNN的语义分割算法致力于解决原始图片每个像素的标签(pixel-wise labeling)问题。将用于分类问题的CNN改为FCN(fully convolutional network),将从分类网络中获取的粗粒度的标签图(label map,这里应该指的是高层输出),经过一个简单的反卷积,之所以说简单,是因为这个反卷积操作只是对标签图进行双线性插值,恢复到原始图片大小。由于标签图大小只有
16×16
,需要将其“反卷积”来生成与原始图片大小相同的分割结果图,显然会造成细节丢失。
网络结构
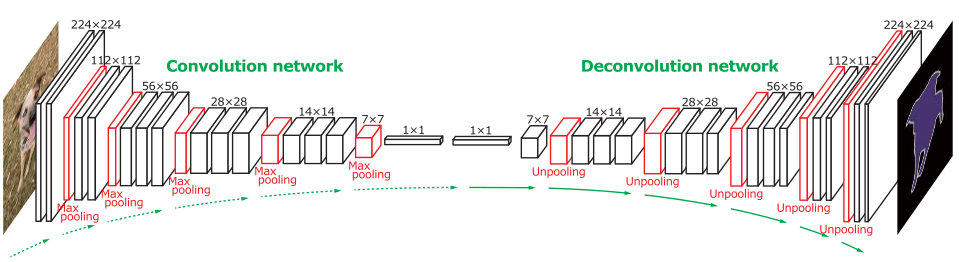
网络分为两个部分:卷积网络和反卷积网络。卷积网络负责特征提取,将输入图片转化为多维的特征向量;而反卷积网络则根据特征提取图片中对象的形状(shape)。最终网络的输出为一个与输入图片相同尺寸的矩阵,表示每个像素属于某一个预定类的概率。
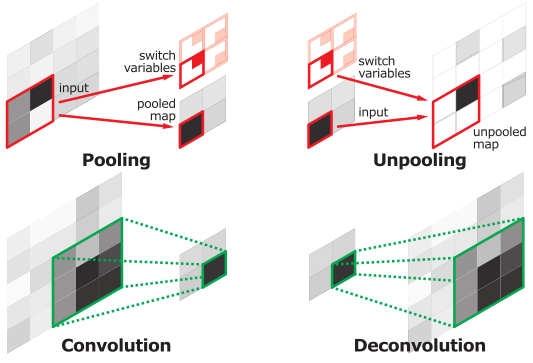
卷积网络采用VGG 16-layer net,去除最后一个分类层,共有13个卷积层(全连接视为特殊的卷积层,卷积核大小与输入相同)。反卷积网络为镜像操作:unpooing, deconvolution, 以及 rectification。
反卷积效果
同卷积网络一样,反卷积网络同样有层次结构,低层输出只能表示出对象的大致形状,而高层的输出则包含了更多的细节。
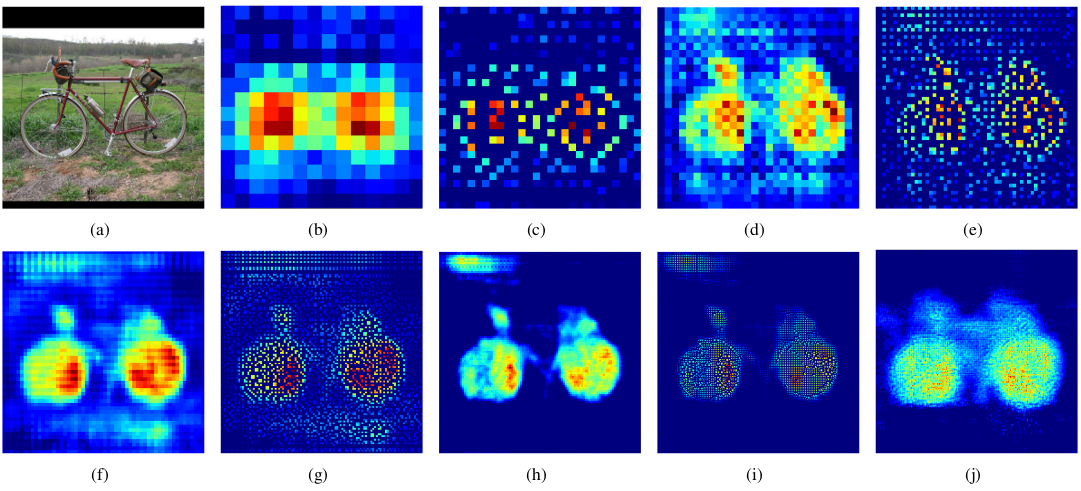
(a)为输入图片,(b)(d)(f)(h)(j)依次为第1,2,3,4,5层反卷积层输出,剩下的为unpooling层输出。
可以看到,随着反卷积网络的传播,重构的对象结构由粗到精。低层倾向于捕捉粗粒度,大概的信息(e.g. location, shape and region),高层捕捉到的信息则更加具体。
可以这样总结:unpooling操作通过跟踪激活值的位置信息,对上层反卷积结果进行了一次放大,得到一个稀疏的图片。而deconvlution则类似于双线性插值,有选择地“填充”放大后的稀疏的结果图。















 3231
3231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









