







在前面的文章中,我们讨论了数据埋点的基础知识、技术实现以及数据质量保证。现在,我们拥有了高质量的数据,是时候深入挖掘这些数据的价值了。本文将带你探索如何通过数据分析和可视化,将原始数据转化为有价值的业务洞察。

目录
1. 数据分析基础
在开始深入分析之前,让我们先回顾一些基本的统计概念和分析方法。
1.1 描述性统计
描述性统计帮助我们总结和描述数据的基本特征。

import pandas as pd
import numpy as np
def descriptive_stats(df, column):
stats = {
"Mean": df[column].mean(),
"Median": df[column].median(),
"Mode": df[column].mode().values[0],
"Std Dev": df[column].std(),
"Min": df[column].min(),
"Max": df[column].max(),
"25th Percentile": df[column].quantile(0.25),
"75th Percentile": df[column].quantile(0.75)
}
return pd.DataFrame(stats, index=[column])
# 使用示例
df = pd.read_csv("user_data.csv")
print(descriptive_stats(df, "age"))
1.2 推断统计

推断统计允许我们从样本数据推断总体特征。
from scipy import stats
def ttest_between_groups(df, value_column, group_column, group1, group2):
group1_data = df[df[group_column] == group1][value_column]
group2_data = df[df[group_column] == group2][value_column]
t_stat, p_value = stats.ttest_ind(group1_data, group2_data)
print(f"T-statistic: {t_stat}")
print(f"P-value: {p_value}")
print(f"Significant difference: {p_value < 0.05}")
# 使用示例
ttest_between_groups(df, "purchase_amount", "user_type", "new", "returning")
1.3 相关性分析
相关性分析帮助我们理解变量之间的关系。
def correlation_analysis(df, method='pearson'):
corr_matrix = df.corr(method=method)
return corr_matrix
# 使用示例
correlation_matrix = correlation_analysis(df[['age', 'income', 'purchase_frequency']])
print(correlation_matrix)
2. 用户行为分析技术

理解用户行为是产品优化的关键。以下是一些常用的用户行为分析技术。
2.1 漏斗分析
漏斗分析用于追踪用户在一系列步骤中的流失情况。

def funnel_analysis(df, steps, user_id_col):
funnel_data = []
total_users = df[user_id_col].nunique()
for step in steps:
users_in_step = df[df['event'] == step][user_id_col].nunique()
conversion_rate = users_in_step / total_users if total_users > 0 else 0
funnel_data.append({
'Step': step,
'Users': users_in_step,
'Conversion Rate': conversion_rate
})
return pd.DataFrame(funnel_data)
# 使用示例
steps = ['view_product', 'add_to_cart', 'start_checkout', 'purchase']
funnel_df = funnel_analysis(event_df, steps, 'user_id')
print(funnel_df)
2.2 同期群分析
同期群分析帮助我们理解不同用户群体随时间的行为变化。
def cohort_analysis(df, date_col, user_id_col, metric_col):
# 确定每个用户的首次购买日期
df['cohort'] = df.groupby(user_id_col)[date_col].transform('min').dt.to_period('M')
# 计算每个用户在每个时间段的指标总和
df['period'] = (df[date_col].dt.to_period('M') - df['cohort']).apply(lambda r: r.n)
cohort_data = df.groupby(['cohort', 'period'])[metric_col].sum().unstack()
# 计算留存率
cohort_sizes = cohort_data.iloc[:,0]
retention_data = cohort_data.divide(cohort_sizes, axis=0)
return retention_data
# 使用示例
retention_df = cohort_analysis(purchase_df, 'purchase_date', 'user_id', 'purchase_amount')
print(retention_df)
2.3 RFM分析
RFM(Recency, Frequency, Monetary)分析用于客户分群。
from datetime import datetime
def rfm_analysis(df, customer_id_col, date_col, amount_col):
# 计算最近一次购买距今的天数(Recency)
current_date = datetime.now()
df['Recency'] = (current_date - df[date_col]).dt.days
# 计算购买频率(Frequency)和总金额(Monetary)
rfm = df.groupby(customer_id_col).agg({
'Recency': 'min',
date_col: 'count',
amount_col: 'sum'
})
rfm.columns = ['Recency', 'Frequency', 'Monetary']
# 将RFM值划分为等级
r_labels = range(4, 0, -1)
r_quartiles = pd.qcut(rfm['Recency'], q=4, labels=r_labels)
f_labels = range(1, 5)
f_quartiles = pd.qcut(rfm['Frequency'], q=4, labels=f_labels)
m_labels = range(1, 5)
m_quartiles = pd.qcut(rfm['Monetary'], q=4, labels=m_labels)
rfm['R'] = r_quartiles
rfm['F'] = f_quartiles
rfm['M'] = m_quartiles
rfm['RFM_Score'] = rfm['R'].astype(str) + rfm['F'].astype(str) + rfm['M'].astype(str)
return rfm
# 使用示例
rfm_df = rfm_analysis(purchase_df, 'customer_id', 'purchase_date', 'purchase_amount')
print(rfm_df.head())
3. 高级分析方法

随着数据量的增加和复杂性的提高,我们需要更先进的分析方法。
3.1 机器学习在用户分析中的应用
机器学习可以帮助我们预测用户行为和个性化推荐。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
def predict_churn(df):
# 准备特征和目标变量
features = ['age', 'total_purchases', 'avg_purchase_value', 'days_since_last_purchase']
X = df[features]
y = df['churned']
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测并评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:")
print(report)
# 特征重要性
feature_importance = pd.DataFrame({
'feature': features,
'importance': model.feature_importances_
}).sort_values('importance', ascending=False)
return feature_importance
# 使用示例
feature_importance = predict_churn(user_df)
print(feature_importance)

3.2 时间序列分析
时间序列分析对于预测趋势和季节性变化非常有用。
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
def time_series_analysis(df, date_col, value_col, freq='D'):
# 将日期列设置为索引
df = df.set_index(date_col)
df.index = pd.to_datetime(df.index)
# 重采样到指定频率
ts = df[value_col].resample(freq).mean()
# 执行时间序列分解
result = seasonal_decompose(ts, model='additive')
# 绘制结果
fig, (ax1, ax2, ax3, ax4) = plt.subplots(4, 1, figsize=(12, 16))
result.observed.plot(ax=ax1)
ax1.set_title('Observed')
result.trend.plot(ax=ax2)
ax2.set_title('Trend')
result.seasonal.plot(ax=ax3)
ax3.set_title('Seasonal')
result.resid.plot(ax=ax4)
ax4.set_title('Residual')
plt.tight_layout()
plt.show()
# 使用示例
time_series_analysis(sales_df, 'date', 'sales', freq='W')
4. 数据可视化原则

数据可视化是将数据洞察传达给利益相关者的关键。以下是一些重要的原则。
4.1 选择正确的图表类型
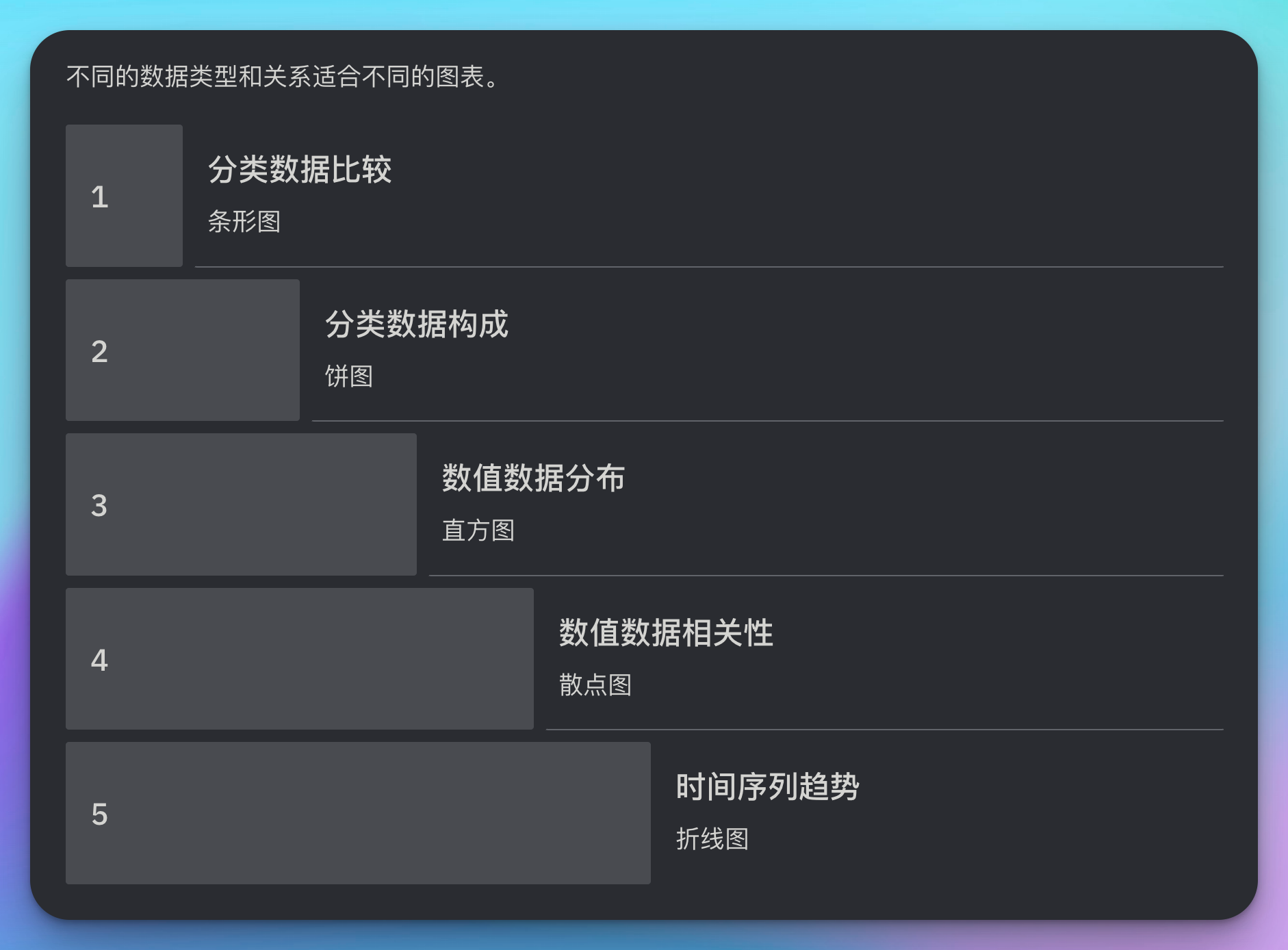
不同的数据类型和关系适合不同的图表。
import matplotlib.pyplot as plt
import seaborn as sns
def choose_chart(data_type, relationship):
chart_types = {
('categorical', 'comparison'): 'bar',
('categorical', 'composition'): 'pie',
('numerical', 'distribution'): 'histogram',
('numerical', 'correlation'): 'scatter',
('time_series', 'trend'): 'line'
}
return chart_types.get((data_type, relationship), 'Not found')
def plot_chart(df, x, y, data_type, relationship):
chart_type = choose_chart(data_type, relationship)
plt.figure(figsize=(10, 6))
if chart_type == 'bar':
sns.barplot(x=x, y=y, data=df)
elif chart_type == 'pie':
plt.pie(df[y], labels=df[x], autopct='%1.1f%%')
elif chart_type == 'histogram':
sns.histplot(df[x], kde=True)
elif chart_type == 'scatter':
sns.scatterplot(x=x, y=y, data=df)
elif chart_type == 'line':
sns.lineplot(x=x, y=y, data=df)
else:
print("Unsupported chart type")
return
plt.title(f"{relationship.capitalize()} of {y} by {x}")
plt.show()
# 使用示例
plot_chart(sales_df, 'product_category', 'sales', 'categorical', 'comparison')
plot_chart(user_df, 'age', 'purchase_amount', 'numerical', 'correlation')
4.2 色彩与布局考虑
正确的色彩选择和布局可以增强可视化的效果。
import matplotlib.pyplot as plt
import seaborn as sns
def set_custom_style():
# 设置自定义样式
plt.style.use('seaborn')
sns.set_palette("deep")
sns.set_context("notebook", font_scale=1.2)
# 自定义颜色映射
custom_cmap = sns.color_palette("husl", 8)
sns.set_palette(custom_cmap)
def plot_with_custom_style(df, x, y):
set_custom_style()
plt.figure(figsize=(12, 6))
sns.barplot(x=x, y=y, data=df)
plt.title(f"{y} by {x}", fontsize=16)
plt.xlabel(x.capitalize(), fontsize=12)
plt.ylabel(y.capitalize(), fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 使用示例
plot_with_custom_style(sales_df, 'product_category', 'sales')
5. 交互式仪表板
交互式仪表板可以让用户自主探索数据。这里我们使用Dash来创建一个简单的交互式仪表板。
import dash
import dash_core_components as dcc
import dash_html_components as html
from dash.dependencies import Input, Output
import plotly.express as px
import pandas as pd
# 加载数据
df = pd.read_csv('sales_data.csv')
app = dash.Dash(__name__)
app.layout = html.Div([
html.H1('Sales Dashboard'),
dcc.Dropdown(
id='category-dropdown',
options=[{'label': i, 'value': i} for i in df['category'].unique()],
value='All Categories'
),
dcc.Graph(id='sales-graph')
])
@app.callback(
Output('sales-graph', 'figure'),
Input('category-dropdown','value')
)
def update_graph(selected_category):
if selected_category == 'All Categories':
filtered_df = df
else:
filtered_df = df[df['category'] == selected_category]
fig = px.line(filtered_df, x='date', y='sales', color='product',
title=f'Sales Over Time for {selected_category}')
return fig
if __name__ == '__main__':
app.run_server(debug=True)
6. 构建数据分析流程

一个有效的数据分析流程可以帮助我们更系统地从数据中获取洞察。
6.1 提出正确的问题
开始分析之前,明确我们想要回答的问题是至关重要的。
def define_analysis_questions():
questions = [
"What is the trend of our monthly active users over the past year?",
"Which user segments have the highest lifetime value?",
"What factors are most strongly correlated with user churn?",
"How does user engagement vary across different product features?",
"What is the optimal time to send promotional emails to maximize open rates?"
]
return questions
# 使用示例
analysis_questions = define_analysis_questions()
for i, question in enumerate(analysis_questions, 1):
print(f"{i}. {question}")
6.2 数据探索
在深入分析之前,我们需要对数据有一个整体的了解。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def explore_data(df):
print("Data Shape:", df.shape)
print("\nData Types:")
print(df.dtypes)
print("\nMissing Values:")
print(df.isnull().sum())
print("\nSummary Statistics:")
print(df.describe())
# 可视化数据分布
numeric_columns = df.select_dtypes(include=['int64', 'float64']).columns
fig, axes = plt.subplots(nrows=len(numeric_columns), ncols=1, figsize=(10, 5*len(numeric_columns)))
for i, col in enumerate(numeric_columns):
sns.histplot(df[col], ax=axes[i])
axes[i].set_title(f'Distribution of {col}')
plt.tight_layout()
plt.show()
# 使用示例
df = pd.read_csv('user_data.csv')
explore_data(df)
6.3 假设检验
基于我们的初步探索,我们可以提出一些假设并进行检验。
from scipy import stats
def hypothesis_test(df, group_column, value_column, group1, group2):
group1_data = df[df[group_column] == group1][value_column]
group2_data = df[df[group_column] == group2][value_column]
t_stat, p_value = stats.ttest_ind(group1_data, group2_data)
print(f"Hypothesis: There is a significant difference in {value_column} between {group1} and {group2}.")
print(f"T-statistic: {t_stat}")
print(f"P-value: {p_value}")
print(f"Conclusion: {'Reject' if p_value < 0.05 else 'Fail to reject'} the null hypothesis.")
# 使用示例
hypothesis_test(df, 'user_type', 'purchase_amount', 'new', 'returning')
6.4 结果解释与行动建议
分析的最后一步是解释结果并提出actionable的建议。
def interpret_results(analysis_results):
interpretations = []
for result in analysis_results:
if result['metric'] == 'churn_rate' and result['value'] > 0.1:
interpretations.append({
'finding': f"Churn rate is high at {result['value']:.2%}",
'recommendation': "Implement a retention program focusing on at-risk users."
})
elif result['metric'] == 'conversion_rate' and result['value'] < 0.05:
interpretations.append({
'finding': f"Conversion rate is low at {result['value']:.2%}",
'recommendation': "Review and optimize the sales funnel, particularly focusing on steps with high drop-off rates."
})
return interpretations
# 使用示例
analysis_results = [
{'metric': 'churn_rate', 'value': 0.15},
{'metric': 'conversion_rate', 'value': 0.03}
]
interpretations = interpret_results(analysis_results)
for interpretation in interpretations:
print(f"Finding: {interpretation['finding']}")
print(f"Recommendation: {interpretation['recommendation']}\n")
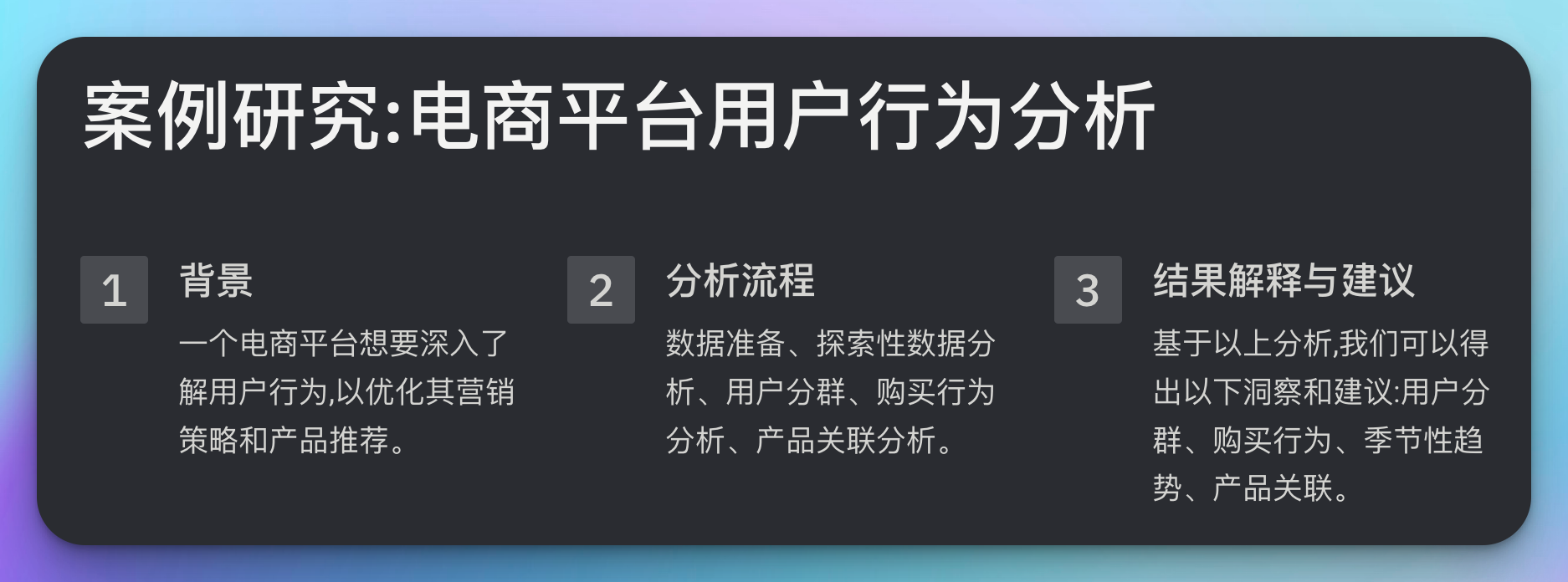
7. 案例研究:电商平台用户行为分析
让我们通过一个实际的案例研究来综合应用我们学到的知识。
背景
一个电商平台想要深入了解用户行为,以优化其营销策略和产品推荐。
分析流程
- 数据准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
df = pd.read_csv('ecommerce_data.csv')
# 数据清洗
df['purchase_date'] = pd.to_datetime(df['purchase_date'])
df['user_registration_date'] = pd.to_datetime(df['user_registration_date'])
df['days_since_registration'] = (df['purchase_date'] - df['user_registration_date']).dt.days
# 移除异常值
df = df[df['purchase_amount'] < df['purchase_amount'].quantile(0.99)] # 移除顶部1%的异常值
- 探索性数据分析
def eda(df):
# 基本统计信息
print(df.describe())
# 可视化购买金额分布
plt.figure(figsize=(10, 6))
sns.histplot(df['purchase_amount'], kde=True)
plt.title('Distribution of Purchase Amount')
plt.show()
# 可视化用户注册时间与购买金额的关系
plt.figure(figsize=(10, 6))
sns.scatterplot(x='days_since_registration', y='purchase_amount', data=df)
plt.title('Purchase Amount vs Days Since Registration')
plt.show()
# 各产品类别的销售额
category_sales = df.groupby('product_category')['purchase_amount'].sum().sort_values(ascending=False)
plt.figure(figsize=(12, 6))
category_sales.plot(kind='bar')
plt.title('Total Sales by Product Category')
plt.xticks(rotation=45)
plt.show()
eda(df)
- 用户分群
def user_segmentation(df):
# 计算每个用户的RFM指标
rfm = df.groupby('user_id').agg({
'purchase_date': lambda x: (pd.Timestamp('2023-05-01') - x.max()).days, # Recency
'purchase_id': 'count', # Frequency
'purchase_amount': 'sum' # Monetary
})
rfm.columns = ['recency', 'frequency', 'monetary']
# 使用K-means进行聚类
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm)
kmeans = KMeans(n_clusters=4, random_state=42)
rfm['cluster'] = kmeans.fit_predict(rfm_scaled)
# 可视化结果
plt.figure(figsize=(10, 8))
sns.scatterplot(x='recency', y='monetary', hue='cluster', data=rfm)
plt.title('User Segments based on RFM')
plt.show()
return rfm
user_segments = user_segmentation(df)
- 购买行为分析
def purchase_behavior_analysis(df):
# 计算每个用户的平均购买间隔
purchase_intervals = df.groupby('user_id')['purchase_date'].diff().dt.days
avg_purchase_interval = purchase_intervals.mean()
# 分析购买时间模式
df['purchase_hour'] = df['purchase_date'].dt.hour
hourly_purchases = df['purchase_hour'].value_counts().sort_index()
plt.figure(figsize=(12, 6))
hourly_purchases.plot(kind='bar')
plt.title('Number of Purchases by Hour of Day')
plt.xlabel('Hour')
plt.ylabel('Number of Purchases')
plt.show()
# 分析季节性趋势
df['purchase_month'] = df['purchase_date'].dt.month
monthly_sales = df.groupby('purchase_month')['purchase_amount'].sum()
plt.figure(figsize=(12, 6))
monthly_sales.plot()
plt.title('Monthly Sales Trend')
plt.xlabel('Month')
plt.ylabel('Total Sales')
plt.show()
purchase_behavior_analysis(df)
- 产品关联分析
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
def product_association_analysis(df):
# 创建购买矩阵
purchase_matrix = df.pivot_table(index='purchase_id', columns='product_id', values='purchase_amount', aggfunc='sum').fillna(0)
purchase_matrix = (purchase_matrix > 0).astype(int)
# 应用Apriori算法
frequent_itemsets = apriori(purchase_matrix, min_support=0.01, use_colnames=True)
# 生成关联规则
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
# 显示top 10规则
print(rules.sort_values('lift', ascending=False).head(10))
product_association_analysis(df)
结果解释与建议
基于以上分析,我们可以得出以下洞察和建议:
-
用户分群:
- 发现了4个主要的用户群体,包括高价值忠诚客户、潜在流失客户等。
- 建议:对高价值客户实施VIP计划,对潜在流失客户进行针对性的挽留活动。
-
购买行为:
- 平均购买间隔为30天,晚上8点是购买高峰。
- 建议:根据购买间隔设置个性化提醒,在晚上8点左右推送促销信息。
-
季节性趋势:
- 销售额在11月和12月达到峰值。
- 建议:提前规划假日季促销活动,增加库存以满足需求。
-
产品关联:
- 发现了几组经常一起购买的产品。
- 建议:优化产品推荐系统,在产品页面和购物车中展示相关产品。
8. 未来趋势
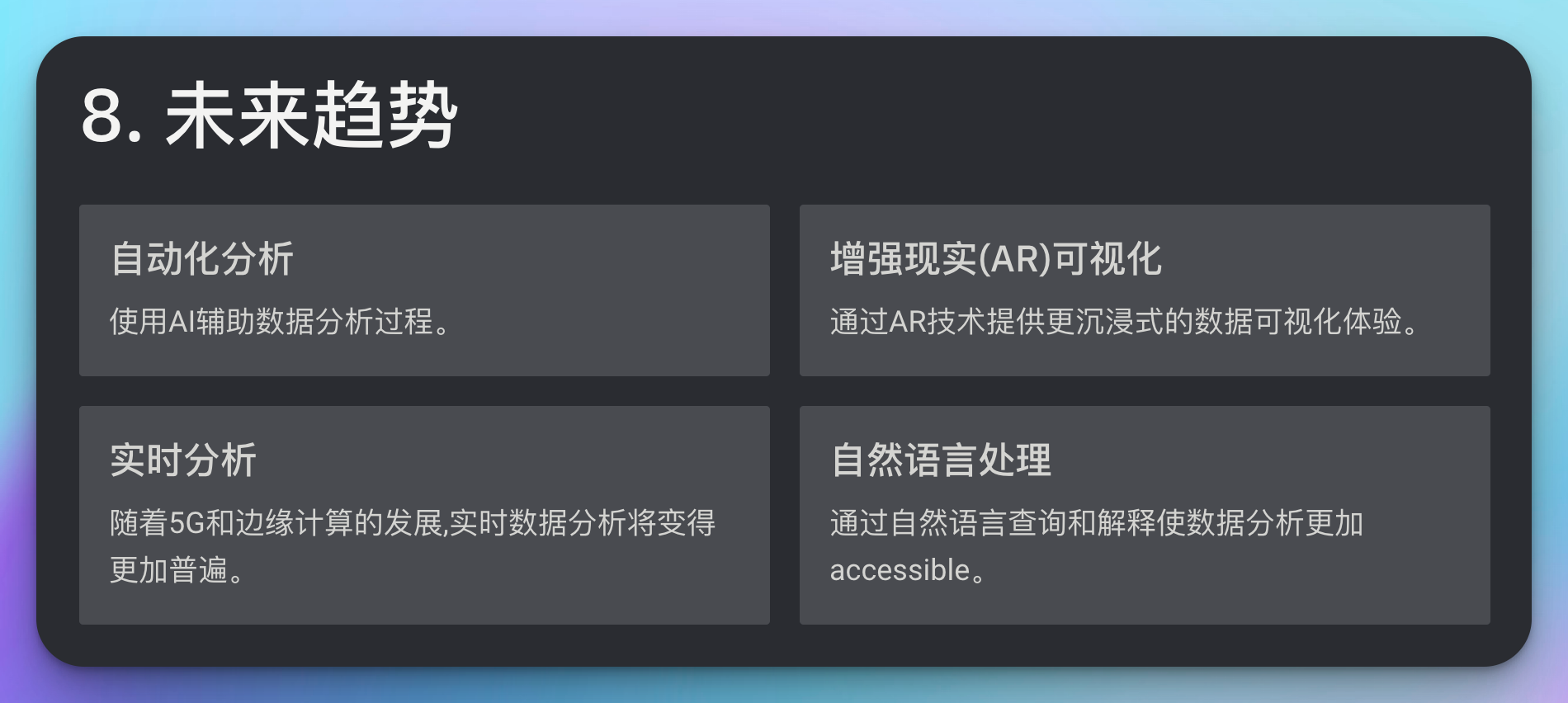
数据分析和可视化领域正在快速发展。以下是一些值得关注的趋势:
- 自动化分析:使用AI辅助数据分析过程。
- 增强现实(AR)可视化:通过AR技术提供更沉浸式的数据可视化体验。
- 实时分析:随着5G和边缘计算的发展,实时数据分析将变得更加普遍。
- 自然语言处理:通过自然语言查询和解释使数据分析更加accessible。
# 自然语言查询示例 (使用hypothetical NLP库)
import nlp_query
def natural_language_query(question, data):
query_engine = nlp_query.QueryEngine(data)
result = query_engine.ask(question)
return result
# 使用示例
question = "What was our total revenue last month?"
result = natural_language_query(question, sales_data)
print(result)
结语

数据分析和可视化是将原始数据转化为有价值洞察的关键过程。通过本文,我们探讨了从基础统计到高级机器学习技术的各种分析方法,以及如何通过有效的可视化技术来传达这些洞察。记住,好的数据分析应该是:
- 目标导向的:始终牢记我们要解决的业务问题
- 严谨的:使用适当的统计方法和验证技术
- 可解释的:确保结果可以被非技术人员理解
- 可行动的:提供清晰的、基于数据的建议
随着数据在决策中的作用越来越重要,掌握这些分析和可视化技能将成为每个数据专业人士的核心竞争力。通过不断学习和实践,你将能够从复杂的数据中揭示有价值的洞察,为组织创造实际的业务价值。
最后,让我们以爱因斯坦的一句名言来结束我们的探讨:"不是所有能被计数的东西都重要,也不是所有重要的东西都能被计数。"在追求数据洞察的同时,我们也要保持开放的思维,认识到某些重要的因素可能无法被简单地量化。真正的智慧在于知道何时依赖数据,何时依赖直觉和经验。
让我们继续在数据的海洋中探索,用数据照亮决策的道路,为组织创造更大的价值!
















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











