






是什么?
基本概念
Apache Doris 是一个基于 MPP(Massively Parallel Processor) 架构的高性能实时分析数据库,以极速和易用性着称。海量数据下仅需亚秒级(响应时间小于1s)响应时间即可返回查询结果,不仅可以支持高并发点查询场景,还可以支持高吞吐量的复杂分析场景。这一切使得 Apache Doris 成为报表分析、即席查询、统一数仓、数据湖查询加速等场景的理想工具。在Apache Doris上,用户可以构建用户行为分析、AB测试平台、日志检索分析、用户画像分析、订单分析等多种应用。

基础架构
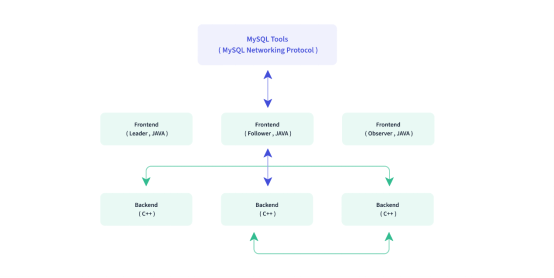
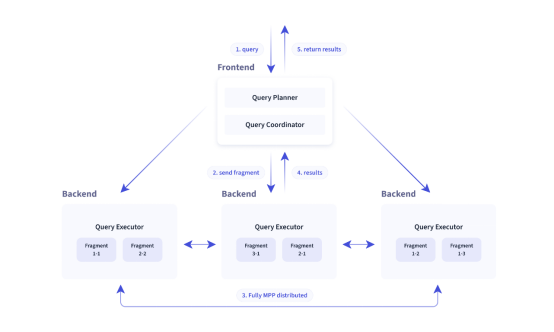
Doris的架构主要分为FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维,FE、BE可线性扩展(增加资源(如服务器数量、CPU核心数等),使系统的性能能够按比例增长的能力);
FE
用户请求接入、查询解析与规划、元数据管理和节点管理等。主要有三种角色:
Leader和Follower
主要用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响到整个服务,Leader算是特殊的Follower;
Observer
用于扩展查询节点,同时起到元数据备份的作用,如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点,observer不参与任何的写入,只参与读取。
BE
数据存储和查询计划执行,依据FE生成的物理计划,分布式地执行查询,数据的可靠性由BE保证,BE对整个数据存储多副本或者三副本,副本数可根据需求动态调整。
字段类型
| TINYINT | 1字节 | 范围:-2^7 + 1 ~ 2^7 - 1 |
| SMALLINT | 2字节 | 范围:-2^15 + 1 ~ 2^15 - 1 |
| INT | 4字节 | 范围:-2^31 + 1 ~ 2^31 - 1 |
| BIGINT | 8字节 | 范围:-2^63 + 1 ~ 2^63 - 1 |
| LARGEINT | 16字节 | 范围:-2^127 + 1 ~ 2^127 - 1 |
| FLOAT | 4字节 | 支持科学计数法 |
| DOUBLE | 12字节 | 支持科学计数法 |
| DECIMAL[(precision, scale)] | 16字节 | 保证精度的小数类型。默认是 DECIMAL(10, 0) precision: 1 ~ 27 scale: 0 ~ 9 其中整数部分为 1 ~ 18 不支持科学计数法 |
| DATE | 3字节 | 范围:0000-01-01 ~ 9999-12-31 |
| DATETIME | 8字节 | 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| CHAR[(length)] | 定长字符串。长度范围:1 ~ 255。默认为1 | |
| VARCHAR[(length)] | 变长字符串。长度范围:1 ~ 65533 | |
| BOOLEAN | 与TINYINT一样,0代表false,1代表true | |
| HLL | 1~16385个字节 | hll列类型,不需要指定长度和默认值、长度根据数据的聚合 程度系统内控制,并且HLL列只能通过配套的hll_union_agg、Hll_cardinality、hll_hash进行查询或使用 |
| BITMAP | bitmap列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到2^64 - 1 | |
| STRING | 变长字符串,0.15版本支持,最大支持2147483643 字节(2GB-4),长度还受be 配置`string_type_soft_limit`, 实际能存储的最大长度取两者最小值。只能用在value 列,不能用在 key 列和分区、分桶列 |
建表示例
Range Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);List Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











