







 本文详细介绍了数理统计中的区间估计概念,包括置信区间的含义和构造步骤。具体讨论了正态总体均值与方差的区间估计情况,如单个总体和两个正态总体的均值差、方差的置信区间,通过实例解析了不同条件下的区间估计方法。
本文详细介绍了数理统计中的区间估计概念,包括置信区间的含义和构造步骤。具体讨论了正态总体均值与方差的区间估计情况,如单个总体和两个正态总体的均值差、方差的置信区间,通过实例解析了不同条件下的区间估计方法。
区间估计
用点估计 θ^(X1,X2,…,Xn) 来估计总体的未知参数 θ ,一旦我们获得了样本观察值 (x1,x2,…,xn) ,将它代入 θ^(X1,X2,…,Xn) ,即可得到 θ 的一个估计值。这很直观,也很便于使用。但是,点估计值只提供了 θ 的一个近似值,并没有反映这种近似的精确度。同时,由于 θ 本身是未知的,我们也无从知道这种估计的误差大小。因此,我们希望估计出一个真实参数所在的范围,并希望知道这个范围以多大的概率包含参数真值,这就是参数的区间估计问题。
定义
设 θ 为总体 ξ 的未知参数, ξ1,ξ2,…,ξn 为 ξ 的一个子样, T1(ξ1,ξ2,…,ξn),T2(ξ1,ξ2,…,ξn) 为两个统计量。对于任意给定的 α(0<α<1) ,若 T1,T2 满足
P{
T1≤θ≤T2}=1−α
——(4)
则称随机区间 [T1,T2] 为 θ 的置信水平为 1−α 的区间估计, α 为显著性水平, T1,T2 分别称为置信下限和置信上限.
注意:也称 T2−T1 为该区间估计的精度。
值得注意的是,置信区间 (θ^1,θ^2) 是一个随机区间,对于给定的样本 (X1,X2,…,Xn) , 可能包含未知参数 (θ^1,θ^2) ,也可能不包含 θ 。但(4)表明,在重复取样下,将得到许多不同的区间 θ^1(x1,x2,…,xn)、θ^2(x1,x2,…,xn) ,根据贝努利大数定律,这些区间中大约有 100(1−α) 的区间包含未知参数 θ 。
置信度表示区间估计的可靠度,置信度 1−α 越接近于1越好。区间长度则表示估计的范围,即估计的精度,区间长度越短越好。当然,置信度和区间长度是相互矛盾的。在实际问题中,我们总是在保证可靠度的前提下,尽可能地提高精度。因此区间估计的问题,就是在给定 α 值的情况下,利用样本 (X1,X2,…,Xn) 去求两个估计量 θ^1 和 θ^2 的问题。
置信区间的含义
以 α=0.01 为例,此时置信度为 99 。假设反复抽取样本1000次,则得到1000个随机区间 [T1,T2] ,在这1000个区间中,包含值的大约有990个,而不包含 θ 值的大约有10个。
构造区间估计的步骤
1.构造一个与 θ 有关的函数
{ U不含其它未知参数已知U的分布
2.对给定的 α(0<α<1) ,求 a,b 使得
P{ a≤U≤b}=1−α
3.解不等式 a≤U≤b⇔T1≤θ≤T2 ,得到区间 [T1,T2]
正态总体均值与方差的区间估计
设 ξ~N(a,σ2),ξ1,…,ξn 为 ξ 的一子样
单个总体 ξ~N(a,σ2) 的情形
σ2=σ20 已知时,求 a 的区间估计
因为
ξ~N(a,σ20)⇒ξ¯~N(a,σ20n)
令 U=ξ¯−aσ0/n√ ,则 U~N(0,1)
对给定的 α(0<α<1) ,求 uα ,使得
P{
|U|≤uα}=1−α——(∗)
临界值 uα 可由 P{ U≤uα}=1−α2 ,查 N(0,1) 分布表得到
(*)式变为
P{
|ξ¯−aσ/n√|≤uα}=1−α
亦是
P{
ξ¯−uασ0n√≤a≤ξ¯+uασ0n√}=1−α
因此 a 的置信水平为
[ξ¯−uασ0n√,ξ¯+uασ0n√]
不同置信水平 1−α 下, a 的区间估计为
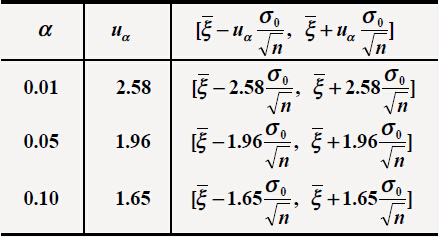
例题
设某种清漆的9个样品,其干燥时间(以小时计)分别为
设干燥时间总体服从正态分布 N(a,0.62) ,求a的置信
水平为 0.95 的置信区间。
解:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5376
5376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









