







部分预备知识可以先看博文,统一了一些专业名词。
原文摘自,在此文中对原文增加了一些注释和修改,统一了与之前博文的专业名词说法,有助于理解。
!!!如果读者发现一些数学符号后面有一些奇怪的竖线,那是CSDN的Latex除了问题,大家自行过滤。
在经典的模式识别中,一般是事先提取特征。提取诸多特征后,要对这些特征进行相关性分析,找到最能代表字符的特征,去掉对分类无关和自相关的特征。然而,这些特征的提取太过依赖人的经验和主观意识,提取到的特征的不同对分类性能影响很大,甚至提取的特征的顺序也会影响最后的分类性能。同时,图像预处理的好坏也会影响到提取的特征。那么,如何把特征提取这一过程作为一个自适应、自学习的过程,通过机器学习找到分类性能最优的特征呢?那就是采用卷积神经网络。
卷积神经元每一个隐层的单元提取上一层图像的局部特征,将其映射成一个平面,特征映射函数采用 sigmoid 函数作为卷积网络的激活函数,使得特征映射具有位移不变性。每个神经元与前一层的局部感受野相连。注意前面我们说了,不是局部连接的神经元权值相同,而是同一平面层的神经元权值共享,有相同程度的位移、旋转不变性。每个特征提取后都紧跟着一个用来求局部平均与二次提取的亚取样层(或下采样层,subsampling layers的翻译很多种多样)。这种特有的两次特征提取结构使得网络对输入样本有较高的畸变容忍能力。也就是说,卷积神经网络通过局部感受野、共享权值和亚取样来保证图像对位移、缩放、扭曲的鲁棒性。
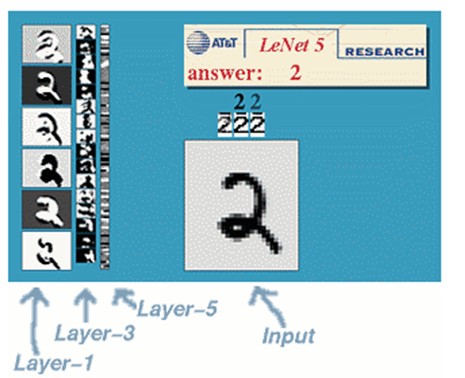
文字识别系统LeNet-5
一种典型的用来识别数字的卷积网络是LeNet-5(paper和效果)。当年美国大多数银行就是用它来识别支票上面的手写数字的。能够达到这种商用的地步,它的准确性可想而知。毕竟目前学术界和工业界的结合是最受争议的。
卷积网络结构说明
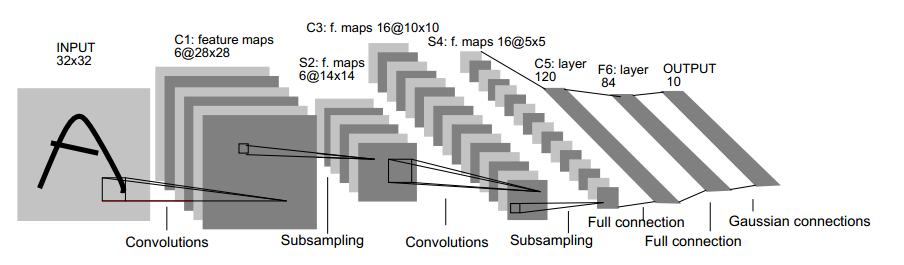
LeNet-5共有7层,不包含输入,每层都包含可训练参数(连接权重)。输入图像为 32×32 大小。这要比Mnist数据库(一个公认的手写数据库,大小应该是 28×28 )中最大的字母还大。这样做的原因是希望潜在的明显特征如笔画断电或角点能够出现在最高层特征监测子感受野的中心。
首先,简要解释下上面这个用于文字识别的LeNet-5深层卷积网络:
输入图像是 32×32 的大小,过滤器的大小是 5×5 的,由于不考虑对图像的边界进行拓展(narrow CNN),则过滤器将有 28×28 (32 - 5 + 1 = 28,其中1是步长)个不同的位置,也就是C1面的大小是28x28。这里设定C1层中有6个不同的C1面,每一个C1面内的权值是共享的。
S2层是一个下采样层(subsampling layer)。简单的说,由4个点下采样为1个点,也就是4个数的加权平均。但在LeNet-5系统,下采样层比较复杂,因为这4个加权系数也需要学习得到,这显然增加了模型的复杂度。在斯坦福关于深度学习的教程中,这个过程叫做Pool。S2面的大小是 14×14 ,其中 14=282
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









