






转载自:http://blog.csdn.net/sunyiyou9/article/details/52434541
主要是参考各家博客以及知乎凭记忆提取的自己的宏观理解,不一定对,以后会不断更新
RCNN:采用传统的SS方法,提取输入图片中可能是物体的bound,大概提取2000个左右,非常多,存在大量的冗余,将提取之后的特征经过CNN网络处理,处理之后的特征加入SVM进行分类,最后通过regression进行回归修正
Fast RCNN:对于RCNN存在的缺点(先提取再加入CNN网络)
对于某个卷积层,无论输入图像有多少个通道,输出图像通道数总是等于卷积核数量
anchors中的坐标是矩形的左上角和右下角点坐标,9个矩形,三种形状,三种比例,引入检测中的多尺度方法
其实结合源码里接起来效果更加显著了
有个博主的博客写的不错(分析RPN这块的网络结构):
这部分主要介绍了通过Alternating Optimization是如何训练RPN网络的,它是怎么样的一个过程。算法过程如下图所示,M4模型是最终的输出。

在该训练过程中,主要分为两大主要的Stage——stage1和stage2。可以看到他的Prototxt文件命名也是通过划分这样两个stage来命名的。stage1包括步骤1-4,stage2包括步骤5-8。
本文主要展现了步骤2与步骤5是如何进行的,即训练RPN网络的过程。RPN网络是Faster R-CNN中最有魅力的部分,所以理解RPN网络的工作原理是十分有意义的。
本人根据stage1_rpn_train.pt文件中的定义,画了网络结构图如下:
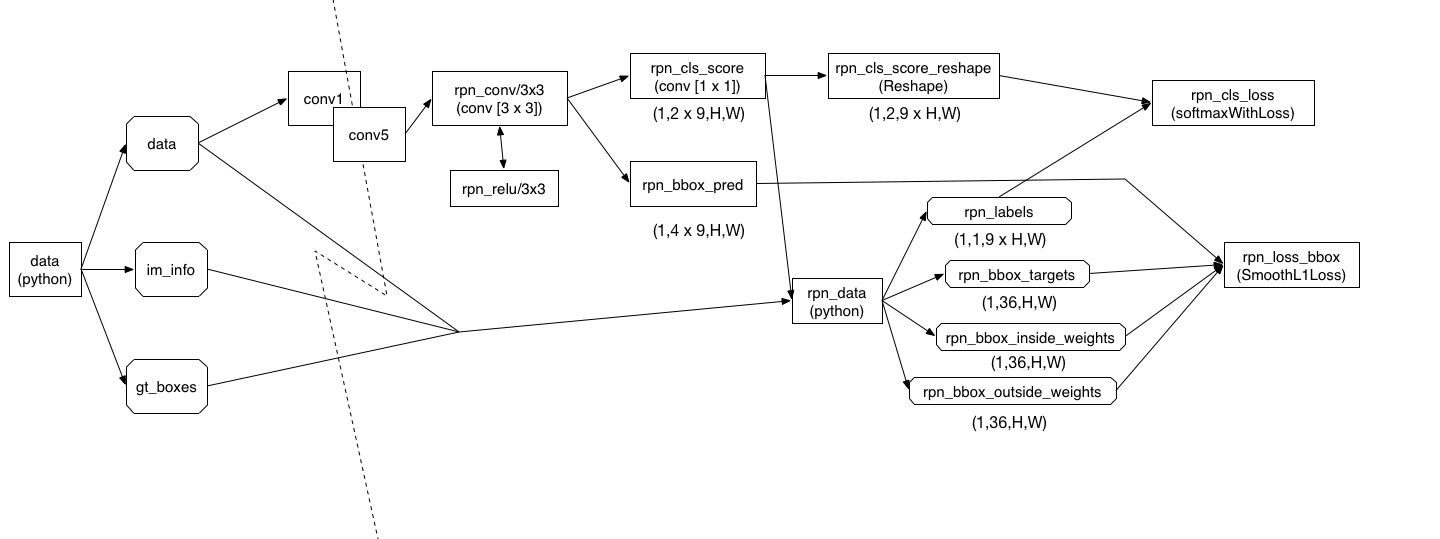
首先是由RoIDataLayer生成的各个blob——data、imfo、gt_boxes,该层由python定义。在这里未对该函数进行详细解释的原因,读者只需记住,该函数输出的是什么就可以了。
data就是原始图像,在这里被缩放成了一个某一边长为600的图像。(我这里原始图像是320 x 240,被放大成600 x 800,这里将小边放大成600.如果有一边超过1000,那么就采取其他措施……细节不多说了)
im_info包括图像原始大小与缩放的比例
gt_boxes包括标注数据集的各个box的(xmin,ymin,xmax,ymax)
data被送入卷积网络,这个网络可以是ZF、VGG_16、VGG_CNN_M_1024等,如果全都画出来,网络结构将太过庞大,在此省略。
conv5输出的blob将被送入一个核为3x3的卷积层rpn_conv3x3,经过Relu层以后,分别被送入两个核为1x1的卷积层(这里之所以用两个卷积层而不用全连接层就是为了减小计算量)。rpn_cls_score有18个output,分别代表9个anchor点的前景与背景的可能值(anchor的概念可以参考http://blog.csdn.net/sunyiyou9/article/details/52264338),在320x240图像输入时,这里的H是36,w是61.也就是说它这里要对于每一个(H,W)位置点,都产生九个不同形状的anchor,在config中定义了一个feat_stride大小为16,你会发现这里的H x feat_stride以及W x feat_stride正好约等于rescale以后的每张图的大小。
那么小小的总结一下,rpn_cls_score就是不断地被训练成一个能够产生在H x W这样一个feature map上每一个位置点的9个anchor的每一个的(前景/背景)概率值,也就是一共9 x H x W个评分。后面被Reshape了一下,是为了blob维度格式的对齐。然后通过rpn_data产生的label进行训练,你可以简单的这么理解:计算每个anchor与ground-truth box的重合度,如果够大,就认为是前景(label=1),如果足够小,就认为是背景(label=0),不大不小就忽略。
接下来轮到rpn_bbox_pred。这个小伙儿呢就是不断地被训练成能生成9 x H x W个anchor上分别离最近的ground-truth box的四个偏移值——中心点x偏移了多少、中心点y偏移了多少、宽度(比例)差了多少、高度(比例)差了多少。它的训练过程需要理解AnchorTargetLayer是怎么提供参数的,在上一篇中http://blog.csdn.net/sunyiyou9/article/details/52264338已有介绍。这个rpn_bbox_target就是每个anchor与最近的ground-truth box的四个真实偏移值,inside_weight和outside_weight貌似都是1.
最后总结下,可以看到rpn主要工作机理是生成anchor,然后通过rpn_cls_score对其评估它到底是前景还是背景,再对anchor的具体位置再通过rpn_bbox_pred来细化精度估计。那么这里就能看出,rpn网络其实已经能够有效地对于物体的位置做一个大致的判断,只不过说不出这是哪个类,只能知道是背景还是前景,然后将其提交给fast rcnn网络进行细化判断。
===================分割线===================
Q1:zf五层卷积后又加了一个3*3的卷积,我之前一直的理解 其实它就是又加了一层卷积层而已。 在意义上有什么特别的地方嘛?
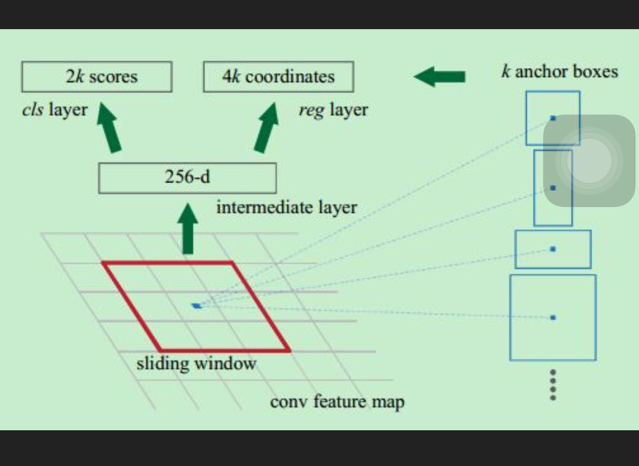
A1:这张图把anchor的生成与卷积的过程,都描述进来了。事实上,卷积的过程与anchor的生成是独立进行的。作者是为了绘画方便,同时强调一个位置点(那个小蓝点)的概念,所以这样画。
仅仅理解成3x3卷积是没问题的,因为核的大小,其实代表着它考虑了多少范围内的特征带来的影响。如果设置成1,那么会相对于只考虑自身的位置的特征点,计算速度上快,毕竟参数小,所以在后面两层是1x1用于取代全连接层。如果卷积核设大了,则会影响运算速度,甚至过拟合,作者取3x3的核是经过严格的理论分析与实验的。
上面分析的很好,结合他博客中的Frcnn源码分析的系列文章使用效果更佳!
py-faster-rcnn源码解读系列(一)——train_faster_rcnn_alt_opt.py
http://blog.csdn.net/sunyiyou9/article/details/52207486
http://blog.csdn.net/sunyiyou9/article/details/52226195
http://blog.csdn.net/sunyiyou9/article/details/52246116
py-faster-rcnn源码解读系列(四)——anchor_target_layer.py
http://blog.csdn.net/sunyiyou9/article/details/52264338















 5805
5805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









