










文章目录
Abstract
基于卷积神经网络(CNN)或长短期记忆(LSTM)的模型,输入谱图或波形,常用于基于深度学习的音源分离。本文针对音乐源分离任务,提出了一种基于谱图域的片状注意力神经网络(Sams-Net)。与LSTMs和CNNs相比,它分别实现了多头注意力机制下的谱图特征交互,实现了更容易的并行计算,并且具有更大的感受野。在MUSDB18数据集上的实验结果表明,所提出的方法在参数较少的情况下,性能优于大多数基于DNN的先进方法。
Introduction
"鸡尾酒会效应 "最早是由Cherry提出的[1]:人脑是如何将对话从周围的噪音中分离出来的。后来,Bregman[2]试图研究人脑如何分析复杂的听觉信号,并提出了一个框架。到了21世纪初,Roman[3]试图通过算法来模拟大脑的声源分离能力,作为现在声源分离的主要框架。当谈到音乐源分离时,第一个无监督的方法是[4]。最近,有监督的方法,特别是基于深度学习的方法[5,6],已经为这个任务取得了可喜的性能。
音乐是由多个单独的乐器组合成的声音产生的,称为 “茎”。音乐源分离的目标是从混合信号中恢复这些单独的音茎[7]。在SiSEC2018活动中[8],这些单独的曲种被归纳为四类:人声、鼓声、贝斯和其他。给定一首由这四种音源混合而成的歌曲,我们的目标是将其分离成与原始音源相对应的四个部分。与语音分离任务中每个单一音源之间相互独立不同,一首歌曲中同一音源和不同音源之间会重复出现许多相似的音乐作品。这一特点给音乐源分离带来了很大的挑战。
大多数音乐源分离模型可以分为两大类,即基于谱图的方法[5,6,9],和基于波形的方法。基于DNN的音乐源分离模型主要基于三种网络架构:全连接网络(FCN)[13]、卷积神经网络(CNN)[6,11]和长短期记忆网络(LSTM)。最近,CNN和LSTM已经结合起来,实现了最先进的音乐源分离性能[12,14]。然而,CNN和LSTM都有一定的局限性。对于CNN来说问题在于对源分离任务的要求是大的感受野[15]。虽然深度CNN能够获得更大的感受野,但参数的增加使训练变得困难。另一种扩大感受野的方法是应用池化层和聚合上下文,然而,这将导致光谱细节的损失。为了解决这个问题,提出了具有多尺度结构的CNN[11]。这种多尺度结构采用下采样(即最大池化层)得到低分辨率的特征图,从中采用上采样层来恢复原始分辨率。对于LSTM[9]来说,时间依赖性的特性阻碍了并行计算,使得推理耗时。此外,根据前人的研究[16],LSTMs中的长期依赖性问题没有得到很好的解决。
注意机制[17]是神经网络建模的最新进展。它可以在没有任何人类领域知识的情况下,自动从数据中学习特征交互。最近,Vaswani等人提出了一种新型的神经网络结构–Transformer[18],在英法翻译任务中只使用注意机制结构,获得了最先进的结果。利用注意力机制,Transformer是一个可以自动捕捉序列分布的结构。它允许网络学习输入序列中哪些部分是重要的,哪些是不重要的。实验结果表明,Transformer比LSTMs更适合处理序列,因为它能比LSTMs更好地解决长期依赖问题[18]。 同时,由于注意机制的计算没有时间上的限制,所以Transformer可以很容易地进行并行计算。此外,与相同层数的CNN相比,Transformer具有更大的感受野。不久之后,一个名为BERT[19]的著名框架被提出,以缩小前期训练词嵌入和下游具体自然语言处理(NLP)任务之间的差距。
在注意机制成功应用的激励下,我们尝试研究注意机制在音源分离任务中的能力,并提出了一种名为Sams-Net的音乐音源分离神经网络,将提出的Sliced Attention机制应用于谱图领域。此外,虽然很多时域模型取得了比谱域模型更好的信噪比(SDR)[20],但在时域建模并不能产生高质量的语音。所以我们更感兴趣像[9]一样在谱图域建立我们的模型,只把幅值谱图反馈到模型中。实验结果表明,我们的模型取得了一个最佳的结果。
本文其余部分安排如下。第2节介绍了音乐源分离任务的问题表述。第3节介绍了所提出的Sams-Net的核心模块,第4节报告了实验设置和结果,第5节得出结论。
Music Source Separation
音乐音源分离是从音乐混合物中提取音源信号。具体来说,立体声混合物x∈R2×Te可以表示为c个音源信号s∈R2×Te的线性组合。

为了在谱图域中进行音乐源分离,在训练过程中,计算每个源信号s的短时傅里叶变换(STFT)S∈R2×T×F,得到混合谱图X∈R2×T×F。

然后,分离网络将幅值谱图|X|作为输入,估计每个源的掩码M∈R2×T×F。时域源bs的重建是通过计算估计频谱图的反STFT(ISTFT)来完成的,即:

为此,学习目标是最小化原始源和估计源之间基于音频的平方l2-norm[11]

图1为谱图域上典型的音乐源分离系统流程图。

Model Description
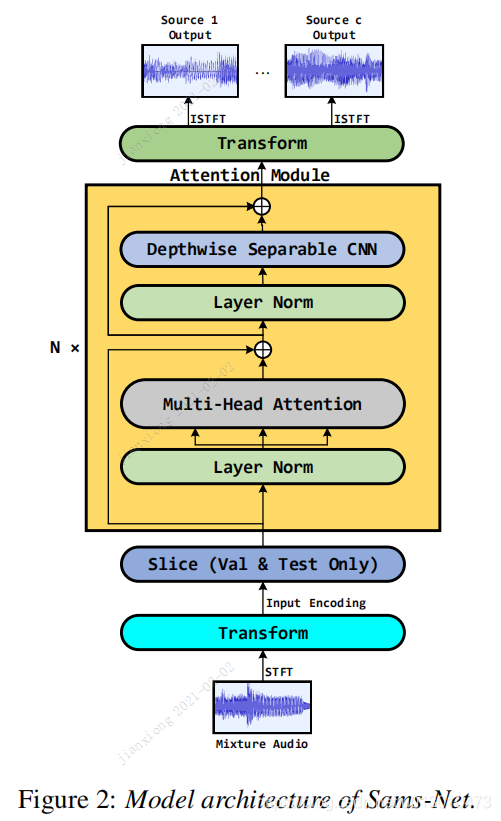
本节介绍我们提出的用于音乐源分离的Sams-Net,如图2所示。它包括两个变换模块、一个分片模块和N个关注模块。第一个变换模块是CNN层,以幅度谱图为输入,将特征图的通道扩展为C,第二个是转置CNN层,将特征图的通道维度由C聚合为2,生成估计掩码。分片模块(3.3节)只适用于验证和测试阶段,而不是训练阶段。注意力块由一个多头缩放的点积注意力层(3.1-3.3节)、一个深度可分离的CNN层(3.4节)和若干层归一化层(3.5节)组成。
Scaled Dot-Product Attention
常见的注意方法有点积法[18]、联结法[22]、感知器[23]等。在本研究中,我们对特征的每一个通道都应用了缩放点积注意法 图。具体来说,对于特征空间中给定的特征图 的RC×T×F ,三个核大小为1×1的CNN层为 分别用于将该特征图转化为查询 Q,键K,值V∈RC×T×F。. 然后,对于每个特征通道c,点积的t 查询时间 Qc,t∈RF 且所有键Kc∈RT×F 是以注意力计算的 权重。在聚合值Vc之前,对注意力权重应用Softmax。在实践中,我们计算出的注意力 同时对Qc进行查询的函数

Multi-Head Attention
为了进一步发挥注意力机制的建模能力,我们在缩放点产品注意力的基础上应用多头注意力[18]。在本研究中,首先将变换块的输出特征图F送入三个卷积层,产生第h个头的查询Qh、键Kh和值Vh∈RC×T×F。然后,对h个头分别进行缩放点积关注,并沿通道轴进行连通输出。

最后,采用内核大小为3×3的附加CNN层来恢复H×C到C的多头衰减输出的信道维度。
Sliced Attention
由于在实际应用中,一首歌曲的持续时间通常较长,我们在注意操作之前,对幅度谱图进行分片操作。
具体来说,幅度谱图被切成I块,没有重叠,产生T /I帧每块.多头注意分别应用于这些I块.产生的I注意值沿时间轴连接作为最终的输出SA。

在切片操作中,注意力的范围被缩小到了块内特征。我们将多头缩放点产品注意力的切片操作定义为切片注意力。图3是切片注意力的流程图。切片关注后,输出的特征维度不变。

我们应用分片操作的原因在于歌曲固有的数据模式。歌曲中存在反复出现的元素[24],如音符、音高、音色和和弦。另外,音乐风格或模式总是在变化。例如,主要的乐器可能会突然从鼓声变成贝斯,然后是纯人声。在这种情况下,切片注意力为网络提供了一种机制,使网络能够将歌曲中具有相同音乐风格的一小段内容集中起来,而不带走与当前部分无关的其他部分。
分片操作在验证和测试阶段应用于整首歌曲。在训练过程中,在每一个训练步骤中,在一首歌曲中随机地切出一小块。
Depthwise Separable CNN
考虑到我们的模型规模较大,我们选择轻量级的深度可分离CNN[25],而不是传统的CNN。具体来说,它有两种操作:深度卷积和点卷积。
对于深度卷积来说,每个通道的特征映射独立应用于卷积层,核大小为 3×3。与传统的CNN不同。 深度卷积层的一个卷积核。负责一个通道。对于点向卷积, 深度卷积操作的输出被送入卷积层,卷积层的核大小为1×1,其目的是为了实现 进一步汇总不同渠道的信息特征图。
Layer Norm
在提出的Sams-Net中,层归一化[26]是在切片注意力层、可深度分离CNN层等子层之后进行的.如图2所示,两个归一化层之间也应用了残差连接,即在上一个归一化层和当前归一化层的输入之间插入快捷连接。计算公式如下

Experimental Results


Conclusions
在本文中,我们提出了一种用于音乐源分离的基于切片注意力的神经网络,命名为Sams-Net。它通过区分不同特征交互的重要性来提高音乐源分离的性能。我们还 提出片断注意机制,以学习重要性 的每个特征交互作用从幅度谱图的每一段。由实验结果可知,在 提出的Sams-Net,在参数较少的情况下,在SDR方面取得了比其他方法更好的性能。
在今后的工作中,我们打算在时间域中建立数据模型,以纳入相位信息。此外,由于 音乐风格变化的点并不是均匀分布的,我们 不能只是简单地将每首歌曲一视同仁。我们希望能够自动识别一首歌内音乐风格的变化点,这样一来 片状关注可以在一个块内进行,并具有以下特点。风格相同的音乐。帧级的分类器可能是一个可能的解决方案,以找到每个帧的音乐风格的模式,使 可以确定一个变化点。

















 1621
1621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









