








 NPKit是一个专为MicrosoftMSCCL、NVIDIANCCL和AMDRCCL等集体通信库设计的性能分析框架,它允许用户在GPU内核中插入自定义事件,并将它们整合到统一的GoogleTraceEventFormat中,便于理解和优化CCL的工作流程和性能。本文详细介绍了如何在NCCL中应用NPKit以及解析dump数据的方法。
NPKit是一个专为MicrosoftMSCCL、NVIDIANCCL和AMDRCCL等集体通信库设计的性能分析框架,它允许用户在GPU内核中插入自定义事件,并将它们整合到统一的GoogleTraceEventFormat中,便于理解和优化CCL的工作流程和性能。本文详细介绍了如何在NCCL中应用NPKit以及解析dump数据的方法。
NPKit介绍
NPKit (Networking Profiling Kit) is a profiling framework designed for popular collective communication libraries (CCLs), including Microsoft MSCCL, NVIDIA NCCL and AMD RCCL.
It enables users to insert customized profiling events into different CCL components, especially into giant GPU kernels.
These events are then automatically placed onto a unified timeline in Google Trace Event Format, which users can then leverage trace viewer to understand CCLs’ workflow and performance.
以NCCL为例,如何使用?
Usage
-
NCCL 2.17.1-1版本,将文件夹下的
npkit-for-nccl-2.17.1-1.diff添加到你的nccl源文件中。
实测nccl2.17和2.18都可以用。使用方法:
git apply ../NPKit/nccl_sample/npkit-for-nccl-2.17.1-1.diff
如果是对应的RCCL和MSCCL版本,方法类似。但如果是自己维护的其他分支,最好还是自己看看。 -
NPKit只有在CPU和GPU没以后overlap的时候使用,所以
NPKIT_FLAGS也要遵从这个规则。同时npkit_launcher.sh里面的参数也要对应正确。
我发现这个仓库提供的bash脚本有一点问题,编译的时候容易失败。所以我把bash脚本中的编译部分注释掉了,在外面编译。编译时记得检查对应的NPKIT_FLAGS。
这个仓库通过编译宏来控制profiling监控的对象,所以如果你这次做了all_reduce,下次想测alltoall,就得换一个NPKIT_FLAGS重新编译。 -
nccl_test和npkit_runner.sh对应参数正确. 仅支持每个线程有1个GPU, 因此nccl_test运行参数记得是-g 1 -
运行
bash npkit_launcher.sh. 这个脚本会调用npkit_runner. -
生成文件
npkit_event_trace.json,可以用谷歌浏览器打开看。在浏览器那一栏输入chrome://tracing, 然后打开对应文件即可。
以下是nccl_sample中解析dump为trace的代码。
import argparse
import os
import json
from queue import Queue
def parse_npkit_event_header(npkit_event_header_path):
npkit_event_def = {'id_to_type': {}, 'type_to_id': {}}
with open(npkit_event_header_path, 'r') as f:
lines = [x.strip() for x in f.readlines() if len(x.strip()) != 0]
line_idx = 0
while line_idx < len(lines):
if lines[line_idx].startswith('#define NPKIT_EVENT_'):
fields = lines[line_idx].split()
if len(fields) == 3:
event_type = fields[1]
event_id = int(fields[2], 0)
npkit_event_def['type_to_id'][event_type] = event_id
npkit_event_def['id_to_type'][event_id] = event_type
line_idx += 1
return npkit_event_def
def parse_gpu_clock_scale(gpu_clock_file_path):
with open(gpu_clock_file_path, 'r') as f:
freq_in_khz = f.read()
return float(freq_in_khz) * 1e3 / 1e6
def parse_cpu_clock_scale(cpu_clock_den_file_path, cpu_clock_num_file_path):
with open(cpu_clock_num_file_path, 'r') as f:
num = float(f.read())
with open(cpu_clock_den_file_path, 'r') as f:
den = float(f.read())
return den / num / 1e6
def parse_gpu_event(event_bytes):
return {
'id': int.from_bytes(event_bytes[0:1], byteorder='little', signed=False),
'size': int.from_bytes(event_bytes[1:5], byteorder='little', signed=False),
'rsvd': int.from_bytes(event_bytes[5:8], byteorder='little', signed=False),
'timestamp': int.from_bytes(event_bytes[8:16], byteorder='little', signed=False)
}
def parse_cpu_event(event_bytes):
return {
'id': int.from_bytes(event_bytes[0:1], byteorder='little', signed=False),
'size': int.from_bytes(event_bytes[1:5], byteorder='little', signed=False),
'slot': int.from_bytes(event_bytes[5:8], byteorder='little', signed=False),
'timestamp': int.from_bytes(event_bytes[8:16], byteorder='little', signed=False)
}
def parse_gpu_event_file(npkit_dump_dir, npkit_event_def, rank, buf_idx, gpu_clock_scale, cpu_clock_scale):
gpu_event_file_path = os.path.join(npkit_dump_dir, 'gpu_events_rank_%d_buf_%d' % (rank, buf_idx))
raw_event_size = 16
curr_cpu_base_time = None
curr_gpu_base_time = None
gpu_events = []
event_type_to_seq = {}
with open(gpu_event_file_path, 'rb') as f:
raw_content = f.read()
raw_content_size = len(raw_content)
raw_content_idx = 0
while raw_content_idx < raw_content_size:
parsed_gpu_event = parse_gpu_event(raw_content[raw_content_idx : raw_content_idx + raw_event_size])
if npkit_event_def['id_to_type'][parsed_gpu_event['id']] == 'NPKIT_EVENT_TIME_SYNC_CPU':
curr_cpu_base_time = parsed_gpu_event['timestamp'] / cpu_clock_scale
curr_gpu_base_time = None
elif npkit_event_def['id_to_type'][parsed_gpu_event['id']] == 'NPKIT_EVENT_TIME_SYNC_GPU':
if curr_gpu_base_time is None:
curr_gpu_base_time = parsed_gpu_event['timestamp'] / gpu_clock_scale
else:
if curr_gpu_base_time is None:
curr_gpu_base_time = parsed_gpu_event['timestamp'] / gpu_clock_scale
event_type = npkit_event_def['id_to_type'][parsed_gpu_event['id']]
phase = 'B' if event_type.endswith('_ENTRY') else 'E'
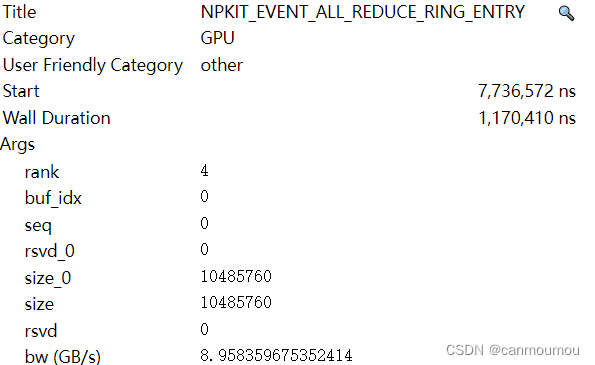
gpu_events.append({
'ph': phase,
'ts': curr_cpu_base_time + parsed_gpu_event['timestamp'] / gpu_clock_scale - curr_gpu_base_time,
'pid': rank,
'tid': buf_idx + 1
})
if phase == 'B':
if event_type not in event_type_to_seq:
event_type_to_seq[event_type] = 0
gpu_events[-1].update({
'name': event_type,
'cat': 'GPU',
'args': {
'rank': rank,
'buf_idx': buf_idx,
'seq': event_type_to_seq[event_type],
'rsvd_0': parsed_gpu_event['rsvd'],
'size_0': parsed_gpu_event['size']
}
})
event_type_to_seq[event_type] += 1
else:
gpu_events[-1]['args'] = {'size': parsed_gpu_event['size'], 'rsvd': parsed_gpu_event['rsvd']}
delta_time = gpu_events[-1]['ts'] - gpu_events[-2]['ts']
gpu_events[-1]['args']['bw (GB/s)'] = 0. if delta_time == 0. else gpu_events[-1]['args']['size'] / delta_time / 1e3
raw_content_idx += raw_event_size
return gpu_events
def parse_cpu_event_file(npkit_dump_dir, npkit_event_def, rank, channel, cpu_clock_scale):
cpu_event_file_path = os.path.join(npkit_dump_dir, 'cpu_events_rank_%d_channel_%d' % (rank, channel))
raw_event_size = 16
cpu_events = []
event_type_to_seq = {}
fiber_is_usable = []
fiber_open_ts = []
slot_to_fiber_id = {}
channel_shift = 1000
with open(cpu_event_file_path, 'rb') as f:
raw_content = f.read()
raw_content_size = len(raw_content)
raw_content_idx = 0
while raw_content_idx < raw_content_size:
parsed_cpu_event = parse_cpu_event(raw_content[raw_content_idx : raw_content_idx + raw_event_size])
event_type = npkit_event_def['id_to_type'][parsed_cpu_event['id']]
phase = 'B' if event_type.endswith('_ENTRY') else 'E'
cpu_events.append({
'ph': phase,
'ts': parsed_cpu_event['timestamp'] / cpu_clock_scale,
'pid': rank
})
slot = parsed_cpu_event['slot']
if phase == 'B':
# Open fiber event
fiber_id = 0
while fiber_id < len(fiber_is_usable):
if fiber_is_usable[fiber_id]:
break
fiber_id += 1
if fiber_id == len(fiber_is_usable):
fiber_is_usable.append(True)
fiber_open_ts.append(0.0)
slot_to_fiber_id[slot] = fiber_id
fiber_open_ts[fiber_id] = cpu_events[-1]['ts']
fiber_is_usable[fiber_id] = False
if event_type not in event_type_to_seq:
event_type_to_seq[event_type] = 0
cpu_events[-1].update({
'name': event_type,
'cat': 'CPU',
'args': {
'rank': rank,
'channel': channel,
'slot': parsed_cpu_event['slot'],
'seq': event_type_to_seq[event_type],
'size_0': parsed_cpu_event['size']
}
})
event_type_to_seq[event_type] += 1
else:
# Close fiber event
fiber_id = slot_to_fiber_id[slot]
slot_to_fiber_id.pop(slot)
last_ts = fiber_open_ts[fiber_id]
fiber_is_usable[fiber_id] = True
delta_time = max(0.001, cpu_events[-1]['ts'] - last_ts)
cpu_events[-1]['args'] = {'size': parsed_cpu_event['size']}
cpu_events[-1]['args']['bw (GB/s)'] = 0. if delta_time == 0. else cpu_events[-1]['args']['size'] / delta_time / 1e3
cpu_events[-1]['tid'] = fiber_id + (channel + 1) * channel_shift
raw_content_idx += raw_event_size
return cpu_events
def convert_npkit_dump_to_trace(npkit_dump_dir, output_dir, npkit_event_def):
files_in_dump_dir = next(os.walk(npkit_dump_dir))[2]
gpu_event_files = [x for x in files_in_dump_dir if x.startswith('gpu_events_rank_')]
cpu_event_files = [x for x in files_in_dump_dir if x.startswith('cpu_events_rank_')]
ranks = list(set([int(x.split('_rank_')[1].split('_')[0]) for x in gpu_event_files]))
buf_indices = list(set([int(x.split('_buf_')[1].split('_')[0]) for x in gpu_event_files]))
channels = list(set([int(x.split('_channel_')[1].split('_')[0]) for x in cpu_event_files]))
trace = {'traceEvents': []}
for rank in ranks:
cpu_clock_den_file_path = os.path.join(npkit_dump_dir, 'cpu_clock_period_den_rank_%d' % rank)
cpu_clock_num_file_path = os.path.join(npkit_dump_dir, 'cpu_clock_period_num_rank_%d' % rank)
cpu_clock_scale = parse_cpu_clock_scale(cpu_clock_den_file_path, cpu_clock_num_file_path)
gpu_clock_file_path = os.path.join(npkit_dump_dir, 'gpu_clock_rate_rank_%d' % rank)
gpu_clock_scale = parse_gpu_clock_scale(gpu_clock_file_path)
for buf_idx in buf_indices:
gpu_events = parse_gpu_event_file(npkit_dump_dir, npkit_event_def, rank, buf_idx, gpu_clock_scale, cpu_clock_scale)
trace['traceEvents'].extend(gpu_events)
for channel in channels:
cpu_events = parse_cpu_event_file(npkit_dump_dir, npkit_event_def, rank, channel, cpu_clock_scale)
trace['traceEvents'].extend(cpu_events)
trace['traceEvents'].sort(key=lambda x : x['ts'])
trace['displayTimeUnit'] = 'ns'
os.makedirs(output_dir, exist_ok=True)
with open(os.path.join(output_dir, 'npkit_event_trace.json'), 'w') as f:
json.dump(trace, f)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--npkit_dump_dir', type=str, required=True, help='NPKit dump directory.')
parser.add_argument('--npkit_event_header_path', type=str, required=True, help='Path to npkit_event.h.')
parser.add_argument('--output_dir', type=str, required=True, help='Path to output directory.')
args = parser.parse_args()
npkit_event_def = parse_npkit_event_header(args.npkit_event_header_path)
convert_npkit_dump_to_trace(args.npkit_dump_dir, args.output_dir, npkit_event_def)
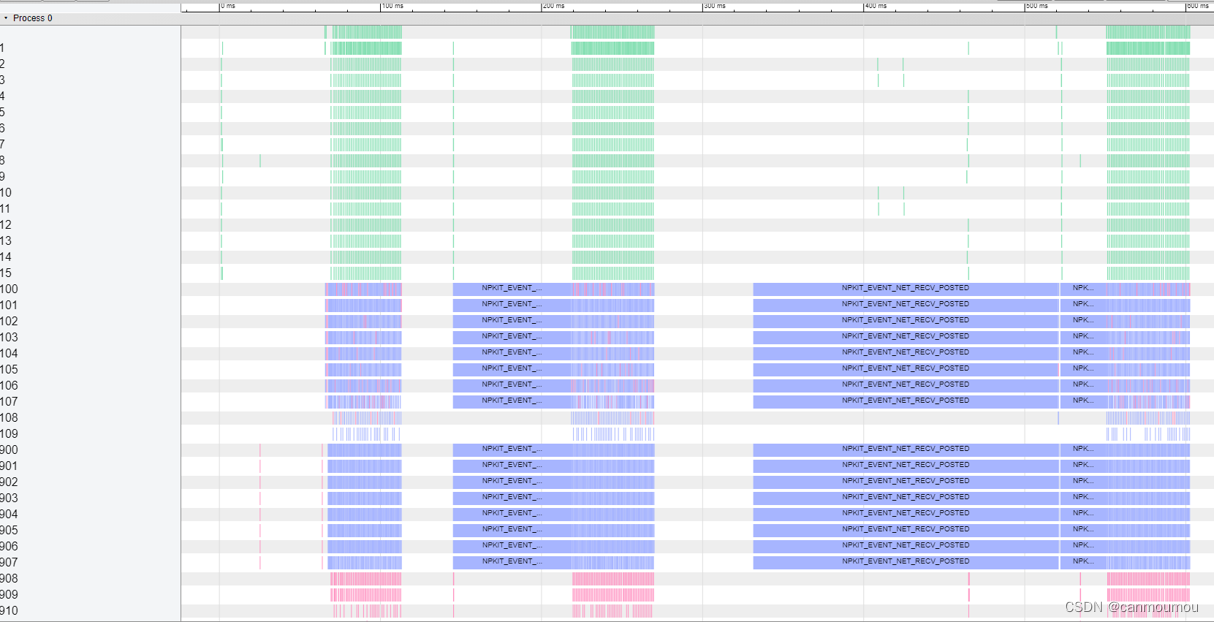
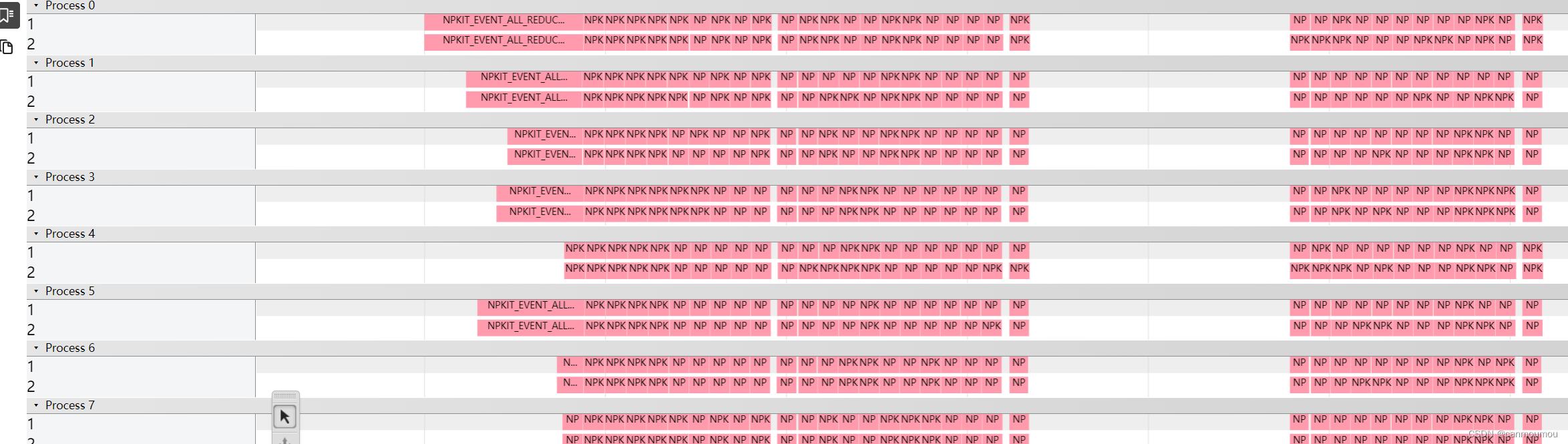
测试效果
我在8卡A100上跑了一下ring。
也不知道对不对。



















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











