







Abstract
在这项工作中,提出了一种用于成对和非成对图像增强的新颖方法。首先,我们开发了全局增强网络 (GEN) 和局部增强网络 (LEN),它们可以忠实地增强图像。建议的GEN执行信道强度变换,该变换比像素预测更容易训练。所提出的LEN基于空间滤波来细化GEN结果。其次,我们针对成对学习和不成对学习提出了不同的训练方案,以训练GEN和LEN。特别是,我们提出了一种基于生成对抗网络的两阶段训练方案,用于不成对学习。实验结果表明,该算法在成对和非成对图像增强方面优于现有技术。值得注意的是,所提出的未配对图像增强算法比最新的最先进的配对图像增强算法提供了更好的结果。源代码和经过训练的模型可在https://github.com/hukim1124/GleNet上获得。
1 Introduction
如今,许多人拍照以记录日常生活以及重要事件。但是,不受控制的环境通常会使照片具有较低的动态范围或失真的色调。因此,图像增强变得越来越流行,可以编辑照片以提高其美学质量。图像增强方法可以分为全局方法和局部方法。前者导出将输入颜色映射到输出颜色的变换函数。另一方面,后者执行空间滤波以根据局部邻域信息确定像素颜色。Photoshop等专业软件应用程序提供各种全局和局部增强工具,以支持手动图像增强。然而,手动过程很耗时。此外,其结果在很大程度上取决于用户的技能和经验。
对于自动图像增强,已经提出了许多研究。大多数早期研究都集中在全局方法上,因为它比局部方法更稳定并且需要更少的计算复杂性。但是,仅使用单个变换函数可能不足以产生令人满意的增强图像。相比之下,基于深度学习的最新研究 [8,25,30,444] 主要采用局部方法。这些方法从许多配对数据 (包括输入和地面真相增强图像) 中学习了强大的像素映射,并提供了有希望的增强图像。然而,如图1(a) 所示,它们需要许多低质量和高质量图像的图像对。为了克服这个问题,不需要图像对的不成对图像增强已经引起了许多研究的关注 [4,5,12,19,26,34]。特别地,使用生成对抗网络 (GANs) [4,5,19] 或强化学习 [12,26,34] 来使用图1(b) 中的未配对数据实现未配对图像增强。然而,尽管现有研究取得了一些进展,但与现有的成对图像增强方法相比,它们的结果并不令人满意。
在本文中,我们提出了两种网络,即全局增强网络 (GEN) 和局部增强网络 (LEN),以实现成对和非成对图像增强。GEN执行信道强度变换,这比基于U-Net架构的像素预测更容易训练 [27]。LEN进行空间过滤以完善GEN结果。然后,我们开发了两种用于配对学习和不配对学习的训练计划。特别是,我们提出了一种基于生成对抗网络的非配对学习的两阶段训练方案。在MIT-Adobe 5k数据集 [2] 上的实验表明,所提出的方法在成对和未成对图像增强方面均优于现有技术。此外,表明所提出的非配对方法比传统配对方法产生更好的增强结果。
总而言之,这项工作有三个主要贡献:
-我们提出GEN和LEN用于配对和非配对图像增强。
-我们提出了非配对图像增强的两阶段训练方案。
-所提出的方法在MIT-Adobe 5k数据集上显示出出色的性能。
2 Related Work
早期对图像增强的研究主要集中在提高输入图像的全局对比度上 [16,24]。他们经常推导出将输入像素值映射到输出像素值的变换函数。全局对比度技术对整个图像中的所有像素使用单个映射函数。例如,幂律 (gamma) 和对数变换 [9] 是众所周知的全局方法。直方图均衡化 [9] 及其变体 [1,17,21-23,29,32] 修改图像的直方图以拉伸其有限的动态范围。Retinex方法 [3,6、7、11、13、14、31、35] 将图像分解为反射率和照明 [20],并修改照明以增强亮度差的图像。但是,这些方法可能无法模拟图像与其专业增强版本之间的复杂映射功能。
最近关于图像增强的研究采用了数据驱动的方法,这些方法使用大型数据集来学习输入图像和增强图像之间的映射。为此,Bychkovsky等人 [2] 介绍了MIT-Adobe 5k数据集,其中包含5,000个输入图像和5个不同摄影师修饰的增强图像。该数据集被广泛用于训练深度神经网络。Yan等人 [444] 使用来自深度神经网络的图像描述符预测像素方向的颜色映射。Lore等人 [25] 首先采用自动编码器的方法来增强弱光图像。Gharbi等人 [8] 通过发展深度双边学习实现了实时图像增强,该学习预测了局部a ffi ne变换。基于retinex理论,Wang等 [30] 提出了一种深度网络来估计图像到照明的映射函数。这些深度学习方法 [8,25,30,444] 产生了有希望的增强性能,但它们的局限性在于它们需要许多对输入和增强图像来训练其网络。
收集成对的输入图像和手动增强的图像是一项劳动密集型的任务。为了克服这个问题,已经提出了不需要配对数据的非配对学习方法 [4,5,12,19,26,34]。Park等人 [26] 采用了深度强化学习来模拟逐步的人类修饰过程。此外,他们提出了一种失真和恢复训练方案,该方案使高质量图像失真以生成伪输入,并训练网络以将生成的伪输入增强为与相应的高质量图像相似。邓等人[5] 采用了生成对抗网络 (GAN) 来开发一种美学驱动的图像增强方法。Chen等 [4] 提出了一种用于稳定训练双向gan的自适应加权方案。Hu等 [12] 将对抗性损失整合到强化学习中,以生成一系列增强操作。Yu等 [34] 用深度强化对抗性学习训练了局部曝光,将图像分成子图像,并用不同的策略增强它们。最近,Kosugi和Toshihiko [19] 结合强化学习和对抗性学习,在专业的图像编辑软件中控制工具。但是,这些未配对的学习方法比配对的学习方法提供相对较差的结果。
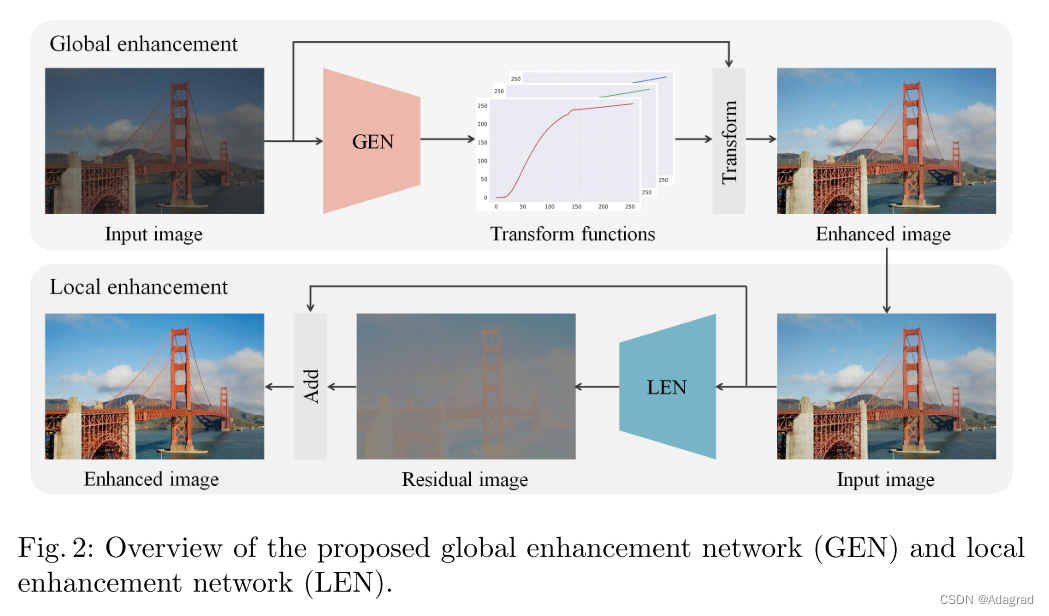
3 Proposed Algorithm
3.1 Model
图2显示了所提出的图像增强框架的概述。首先,我们开发了GEN,该GEN产生了逐通道的强度变换功能,以实现全局图像增强。其次,我们学习执行空间过滤的LEN,以完善全局增强图像。让我们随后描述每个网络。
Global Enhancement Network

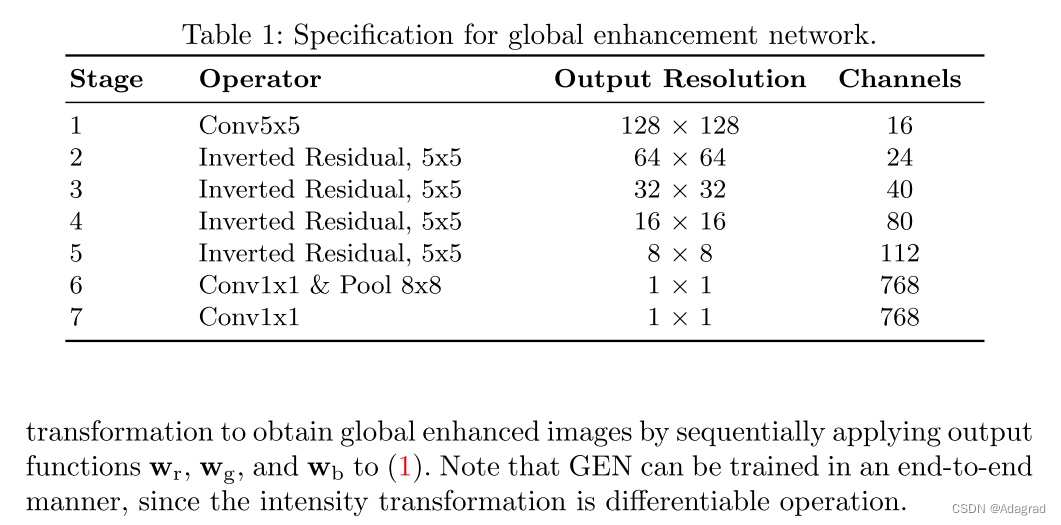
注释:RGB 256x256输入,生成768维度向量,该向量是R、G、B的Global转换函数。
与 [4] 中的常规图像增强网络相比,所提出的GEN具有优势,该网络包含一个解码器以产生像素颜色预测。首先,GEN可以通过执行与像素方向的颜色预测不同的通道强度变换来增强图像,而不管其分辨率如何 [4]。换句话说,通道方向的强度变换可以在没有任何图像调整大小过程的情况下产生增强的图像,而像素方向的颜色预测通常需要根据输入图像的空间大小进行调整大小过程。其次,GEN可以保存网络参数的内存,因为它不需要解码器部分来恢复增强图像的空间分辨率。第三,训练GEN比具有编码器-解码器体系结构的网络要容易得多。在第4.1节中,我们将阐明GEN需要比编码器-解码器体系结构更少的收敛训练步骤。
与早期的全局增强方法不同,我们不认为三个颜色强度变换函数应该是单调函数。大多数现有的全局方法都专注于增强灰度强度而不是颜色强度,并假设单调约束以防止由于保留灰度强度排序而引起的烦人的伪像。但是,单调约束在逐通道强度变换中不起作用。图3显示了输入和修饰图像对及其通道强度变换函数的示例。在这些示例中,我们看到低质量和高质量图像之间存在许多非单调函数。
Local Enhancement Network
尽管GEN具有许多优势,但GEN仅考虑一对一映射是有限的。然而,如图3所示,在低质量和高质量图像之间存在许多一对多映射,这些映射通过在通道变换函数中的着色来描绘。此外,GEN在通过逐通道强度变换去除输入图像中的噪声和模糊方面可能会遇到困难。因此,我们开发了LEN,该LEN执行空间滤波以进行局部增强,以克服GEN的这些限制。

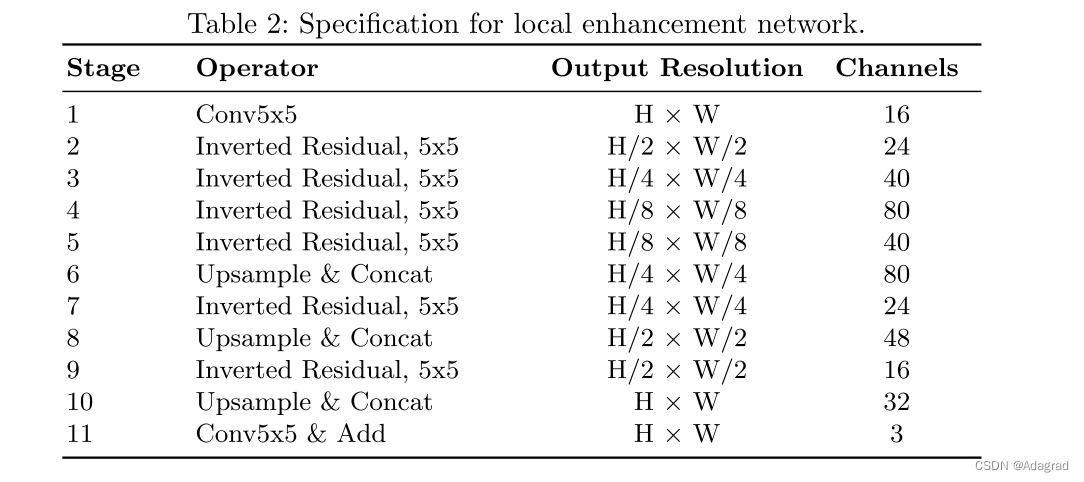
注释:LEN是编码器-解码器结构,输出是去噪残差。
3.2 Learning
我们描述了非配对学习和配对学习的训练方案。首先,我们使用成对的低质量和高质量图像来训练GEN和LEN进行配对学习。其次,我们提出了在不成对学习中学习GEN和LEN的两阶段训练方案。让我们随后解释每个训练方案。


注释:color loss+perceptual loss,感知loss是预测及目标对应的使用VGG-16预训练的第2、4、6层特征之间loss,鼓励在预先训练的嵌入空间有相似特征。

我们使用带有梯度惩罚的Wasserstein GAN (WGAN-GP) [10] 来定义生成器和判别器的目标函数。
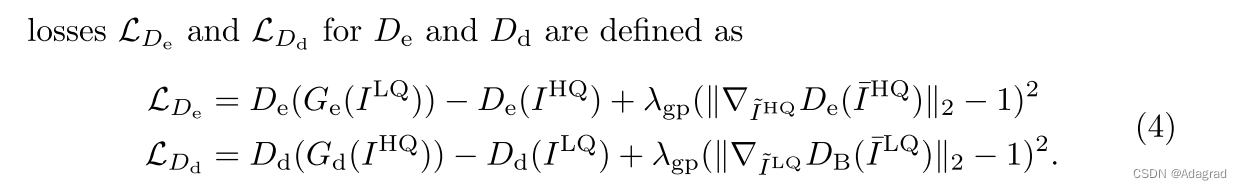


注释:
GEN基于未匹配图像训练,生成器和鉴别器结构相似,训练过程采用两个GAN模式,增强及退化,目标函数为WGAN-GAN。生成器loss是WGAN-GAN的adversarial loss,鉴别器loss是adversarial loss+identity loss+cyclic loss。

注释:LEN训练更加困难,对HQ进行GEN里面退化模型再增强模型得到假的配对数据,用(3)最小化loss进行训练。
4 Experiments
实验组织如下。在第4.1节中,我们验证了当成对的低质量和高质量图像可用时GEN和LEN的有效性。我们将提出的GEN和LEN的性能与基于配对学习的最新算法进行了比较。在第4.2节中,我们使用建议的未配对学习来训练GEN和LEN,并与未配对图像增强中的最新方法进行比较。
对于所有实验,我们使用MIT-Adobe 5k数据集 [2],其中包含5,000个输入图像,每个图像都由五个不同的摄影师 (A/B/C/D/E) 手动修饰。因此,有五组5,000对输入和修饰图像,每个摄影师一组。在这些集合中,我们仅使用由摄影师C修饰的高质量图像进行训练和测试一下,就像大多数现有图像增强算法中所做的那样。我们将5,000图像分成500和4,500图像,分别用于训练集和测试一下集。我们使用训练集中的所有4,500图像对进行配对学习。相反,对于未配对学习,4,500图像对分为两组,每组具有2,250图像对。然后,第一组中的2,250输入图像被包括在低质量图像集中,而第二组中的2,250修饰图像被用于高质量图像集中。请注意,低质量集和高质量集中的图像没有重叠。
为了进行定量评估,我们使用PSNR和SSIM,分别测量预测图像和地面真相高质量图像之间的颜色和结构相似性。
4.1 Paired Learning
对于配对学习,我们使用4,500训练图像对来训练GEN和LEN。我们使用1.0 × 10 − 4的学习率的Adam优化器 [18] 将 (3) 中的损失最小化。对25,000迷你批进行迭代训练。小批量尺寸为16。为了增加数据,我们将图像随机旋转90度的倍数。(3) 中的参数 λ p固定为0.04。
首先,我们通过将GEN中的通道强度变换与像素颜色预测进行比较来验证所提出的GEN的有效性。为了进行此比较,我们设计了一个基线网络,该网络可产生逐像素增强的结果。更具体地说,基线网络具有编码器-解码器架构,其中编码器具有与GEN中的编码器相同的结构,并且解码器由6个上采样块组成,以随后执行双线性插值,级联和卷积滤波。基线网络的详细架构可以在补充材料中找到。图5显示了根据训练步骤的GEN和基线网络的PSNR和SSIM得分。我们观察到GEN通过通道强度转换实现了比基线更快的训练。这是因为强度变换的可能函数的空间比像素方向颜色变换的空间小得多。值得注意的是,所提出的GEN在两个指标的5,000迭代中都超过了基线网络的最佳性能。
接下来,我们将提出的GEN和LEN与最新的最新算法 [4,8,30] 进行比较。为了进行比较,我们使用各自作者提供的源代码和设置获得了常规算法的结果。表3报告了PSNR和SSIM得分。所提出的GEN显著优于所有传统算法。例如,就PSNR和SSIM而言,它说服了1.86dB和0.030的保证金反对DUPE [30]。此外,LEN通过利用局部邻居信息克服了GEN的一对多映射问题。请注意,LEN进一步改善了GEN的结果,因此联合GEN和LEN (GEN & LEN) 在这两个指标中均获得了最佳性能。
图6说明了建议的LEN的e ffi cacy。在图6(b) 中,与图6(d) 中摄影师C的修饰图像相比,GEN在天空,水和拖拉机中产生的色调略有不同。这是因为GEN未能处理一对多的转换。例如,由于图6(a) 中的第一行中的天空和地面区域在蓝色通道中具有相似的强度。然后,GEN在天空和地面区域之间产生相似的蓝色强度。因此,如图6(b) 所示,由于GEN被定制以增强地面区域,所以天空区域中的蓝色强度没有得到明显增强。LEN通过有效的空间滤波克服了这个问题,如图6(c) 所示。与GEN相比,GEN & LEN产生更多视觉上令人愉悦的结果,其具有与图6(d) 中的手动修饰的图像相似的色调。
图7定性地将所提出的算法与DUPE [30] 进行了比较。在图7(b) 中,DUPE [30] 未能表达与图7(d) 中摄影师C的修饰图像相似的色调和亮度。此外,DUPE的结果对比有限。另一方面,所提出的算法成功地产生了具有鲜艳色调的高质量图像,这些图像类似于摄影师C的修饰图像。
4.2 Unpaired Learning
我们对未配对的图像增强进行两阶段训练。具体来说,我们分别针对5,000和25,000个小批量训练GEN和LEN,其中小批量的大小固定为8。再次使用Adam优化器 [18]。我们将初始学习率设置为1.0 × 10-4,并将其每10,000个小批量降低0.5倍。超参数 λ gp、 λ i、 λ c和 λ p分别设置为10、5、50和0.04。为了增加数据,我们将图像随机旋转90度的倍数。
在表4中,我们将所提出的算法与使用MIT-Adobe 5k数据集的常规未配对图像增强算法 [4,19,26] 进行了比较。所提出的GEN优于所有常规算法,因为它可以使用未配对的数据进行轻松训练。这表明GEN中的通道强度变换适用于未配对学习。此外,我们看到,与GEN相比,GEN & LEN提高了PSNR和SSIM得分,并在所有指标中产生了最佳结果。值得指出的是,GEN & LEN优于表3中的所有常规配对图像增强算法,尽管仅使用未配对数据进行训练。
图8定性地将所提出的算法与FRL [19] 进行了比较。拟议的GEN & LEN模型提供了比FRL更忠实的图像。例如,FRL不能有效地增加亮度,如图8(b) 中的图像。相比之下,所提出的算法成功地将低质量图像增强为与摄影师C修饰的高质量图像相似。
非配对学习中提出的训练方案会生成伪配对数据来训练LEN。对于伪配对数据的生成,首先将每个高质量图像降级 (IHQ → Gd(IHQ)),然后将降级图像增强以模仿全局图像增强 (Gd(IHQ) → Ge(Gd(IHQ)。我们定性分析了伪对生成的准确性。图9(a) 和 (b) 分别显示了降级图像和真实的低质量图像。我们观察到退化图像Gd(IHQ) 与真实图像ILQ很好地模仿。此外,值得指出的是,来自退化图像的全局增强图像和低质量图像彼此相似,如图 (c) 和 (d) 所示。
在表5中,我们分析了拟议培训方案的效率。“WGANGP” 表示仅采用 (4) 和 (5) 中的对抗性损失的训练方案。换句话说,它不利用降解GAN。请注意,没有降解GAN就无法获得伪配对数据。因此,“WGAN-GP” 训练方案中的联合GEN和LEN (GEN & LEN *) 仅使用对抗损失来学习。GEN & LEN * 中的PSNR和SSIM分数较低,表明伪配对数据对于训练LEN至关重要。另一方面,与GEN & LEN * 相比,“WGAN-GP” 中的GEN产生了合理的性能。因为基于强度变换的GEN比LEN更适合不成对学习。“CWGAN-GP” 训练方案用 [36] 中的循环一致性损失代替了 (5) 中的循环颜色损失。我们可以看到循环颜色损失比 [36] 中的循环一致性损失更有效。
5 Conclusions
在本文中,我们提出了一种新颖的算法来实现成对和不成对的图像增强。拟议的GEN执行逐通道强度转换,LEN改进了GEN的全局增强图像。为了训练GEN和LEN,我们开发了配对学习和不配对学习方法。对于未配对学习,我们提出了基于GANs的两阶段训练方案,以利用可以轻松训练的GEN优势。实验结果表明,该算法优于MIT-Adobe 5k数据集上的最新算法。值得注意的是,通过建议的未配对学习训练的GEN和LEN优于传统的配对图像增强算法。















 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









