







Abstract
在本文中,我们重新思考低光图像增强任务,并提出了一种用于低光图像增强的物理可解释的生成扩散模型,称为 Diff-Retinex。 我们的目标是整合物理模型和生成网络的优点。 此外,我们希望通过生成网络来补充甚至推导弱光图像中缺失的信息。 因此,Diff-Retinex将弱光图像增强问题转化为Retinex分解和条件图像生成。 在Retinex分解中,我们融合了Transformer中注意力的优越性,精心设计了Retinex Transformer分解网络(TDN),将图像分解为光照图和反射图。 然后,我们设计多路径生成扩散网络来重建法线光 Retinex 概率分布,并分别解决这些组件中的各种退化,包括暗照明、噪声、颜色偏差、场景内容丢失等。由于生成扩散模型 ,Diff-Retinex将弱光细微细节的还原付诸实践。 在现实世界的低光数据集上进行的大量实验定性和定量地证明了所提出方法的有效性、优越性和泛化性。
1. Introduction
在低光场景中拍摄的图像通常会受到各种退化的影响,例如不确定的噪声、低对比度、可变的颜色偏差等。在这些退化中,场景结构的丢失是最棘手的。 如图1所示,场景结构的损失不仅限于影响视觉效果,还会减少信息量。 图像增强是减少退化对人类感知和后续视觉任务的干扰,最终呈现高质量图像的有效方法。
为了处理这些退化问题,人们提出了许多低光图像增强(LLIE)方法[20, 26]。 此外,还开展了对比度增强、噪声去除和纹理保留等一系列研究。 主流的LLIE方法大致可以分为传统的[35, 3]和基于学习的方法[22,15,25,23,18]。 传统算法通常基于图像先验或简单的物理模型。 例如,灰度变换[35, 14]和直方图均衡[5, 34]通过线性或非线性方式调整强度分布。 Retinex模型[12,16,24]将图像分解为光照图像和反射图像,并用传统的优化方法解决该问题。 然而,这些方法也受到手动设计和优化驱动的效率的影响。 它们通常泛化性和鲁棒性较差,限制了这些方法的应用范围。
为了解决这些缺点,利用深度学习来构建从低光到正常光图像的复杂映射[22, 38]。 一些方法完全将微光图像增强视为通过整体拟合的恢复任务,缺乏理论支持和物理模型的可解释性。 与基于物理模型的方法相比,它们通常表现出针对性较差的增强性能,表现为光照不均匀、对噪声不鲁棒等。主要原因是缺乏对某些退化的具体定义和针对性的处理。 基于物理模型的方法将图像分解为具有物理意义的组件。 然后对组件进行针对性的处理,进行更有针对性的增强。
然而,现有的方法很难逃脱拟合的本质。 更具体地说,现有方法中通过去噪可以更好地渲染扭曲的场景,但无法修复丢失的场景内容。 以图1为例,最先进的方法(URetinex [40])无法恢复弱和丢失的细节,甚至在一定程度上加剧了信息失真。 为了解决这个缺点,并考虑到LLIE是在低光图像的引导下恢复正常光图像的过程,我们用生成扩散模型重新思考LLIE。 我们的目标是恢复甚至推理出原始低光图像中的弱信息,甚至丢失的信息。 因此,LLIE不仅被视为恢复拟合函数,而且被视为具有条件的图像生成任务。 至于生成模型,生成对抗网络(GAN)[36, 46]以对抗机制训练生成器和判别器。 然而,它们存在训练不稳定的问题,导致模式崩溃、不收敛、梯度爆炸或消失等问题。 此外,基于GAN的LLIE方法还存在通过整体拟合直接生成正常光图像的问题,缺乏前面提到的物理可解释性。
为此,我们提出了一种用于低光图像增强的物理可解释和生成模型,称为 Diff-Retinex。 我们的目标是整合物理模型和生成网络的优势。 因此,DiffRetinex 将低光图像增强问题表述为 Retinex 分解和条件图像生成。 在Retinex分解中,我们融合了Transformer[21, 41]的特点,精心设计了Retinex Transformer分解网络(TDN),以提高分解的适用性。 TDN 将图像分解为照明图和反射图。 然后,我们设计基于生成扩散的网络来分别解决这些组件中的各种退化,包括暗照明、噪声、颜色偏差、场景内容丢失等。主要贡献总结为:
- 我们从条件图像生成的角度重新思考低光图像增强。 我们提出了一种生成式 Retinex 框架,以进一步补偿低光引起的内容损失和颜色偏差,而不是局限于增强原始的低质量信息。
- 考虑到 Retinex 模型中的分解问题,我们提出了一种新颖的 Transformer 分解网络。 它可以充分利用注意力和层依赖性来有效地分解图像,即使是高分辨率的图像。
- 据我们所知,这是第一个将扩散模型与 Retinex 模型应用于低光图像增强的研究。 应用扩散模型来指导照明和反射图的多路径调整,以获得更好的性能。
2. Related Work
2.1. Retinex-based LLIE Methods
视网膜皮质(Retinex)理论基于颜色不变性模型和人类视觉系统(HVS)对颜色的主观感知[13]。 它将图像分解为照明图和反射图。 它已广泛应用于弱光图像增强,并被证明是有效和可靠的。
Traditional Approaches.
在一些方法中,照明和反射图案的分辨率是通过高斯滤波器或一组滤波器组来实现的,例如SSR [10]和MSR [9]。 LIME [4] 通过初始化三个通道的最大值并应用结构先验细化来形成最终的照明图来估计照明图。 JED[32]通过结合序列分解和伽玛变换来增强图像并抑制噪声。 传统方法主要表现出泛化性差和鲁棒性差,限制了其应用。
Deep Learning-based Approaches.
Retinex-Net [39] 将 Retinex 分解的范式与深度学习相结合。 它采用分阶段分解和调整结构,并使用BM3D [2]进行图像去噪。 类似地,KinD[44]和KinD++[43]采用分解和调整范式,并使用卷积神经网络(CNN)来学习分解和调整中的映射。 Robust Retinex [45]将图像分解为三个组成部分,即照明、反射率和噪声。 然后,在损失的指导下,通过迭代来估计噪声并恢复光照,从而达到去噪和增强的目的。 尽管这些方法表现出优异的性能,但由于卷积的限制,基于CNN的分解无法充分利用全局信息。 此外,它们还面临一些棘手的问题,例如设计损失函数的难度以及完成一些缺失的场景内容的挑战。
2.2. Generative LLIE Methods
随着变分自动编码器(VAE)[11]、GAN [36, 46]等生成模型的发展,图像生成可以取得优异的效果。 从一个新的角度来看,生成模型可以以弱光图像为条件,生成相应的正常光图像,客观地实现弱光图像增强的目标。 EnlightenGAN [8] 设计了一个单一的生成器来直接将低光图像映射到正常光图像。 它与全局和局部判别器相结合来实现该功能。 CIGAN[28]使用循环交互式GAN来完成正常光和弱光图像之间光的循环生成和信息传递。 这些方法都取得了成果。 然而GAN的训练过程比较困难,损失函数收敛不稳定。 最近,扩散模型[7,29,31]已经成为一个强大的生成模型家族,在许多领域都具有破纪录的性能,包括图像生成、修复等。它克服了GAN的一些缺点,打破了长期的统治地位 GAN 在图像生成中的应用 在本文中,我们首次探索了一种将 Retinex 模型与扩散模型相结合的新方法。
3. Methodology
Diff-Retinex的总体框架如图2所示。通用的基于Retinex的增强框架应该能够灵活地分解图像并自适应地消除各种退化。 因此,Transformer分解网络首先根据Retinex理论将图像分解为光照图和反射图。 然后,通过多路径扩散生成调整网络对光照和反射率图进行调整(包括反射率扩散调整和光照扩散调整)。 增强的结果是调整后的组件的生产。
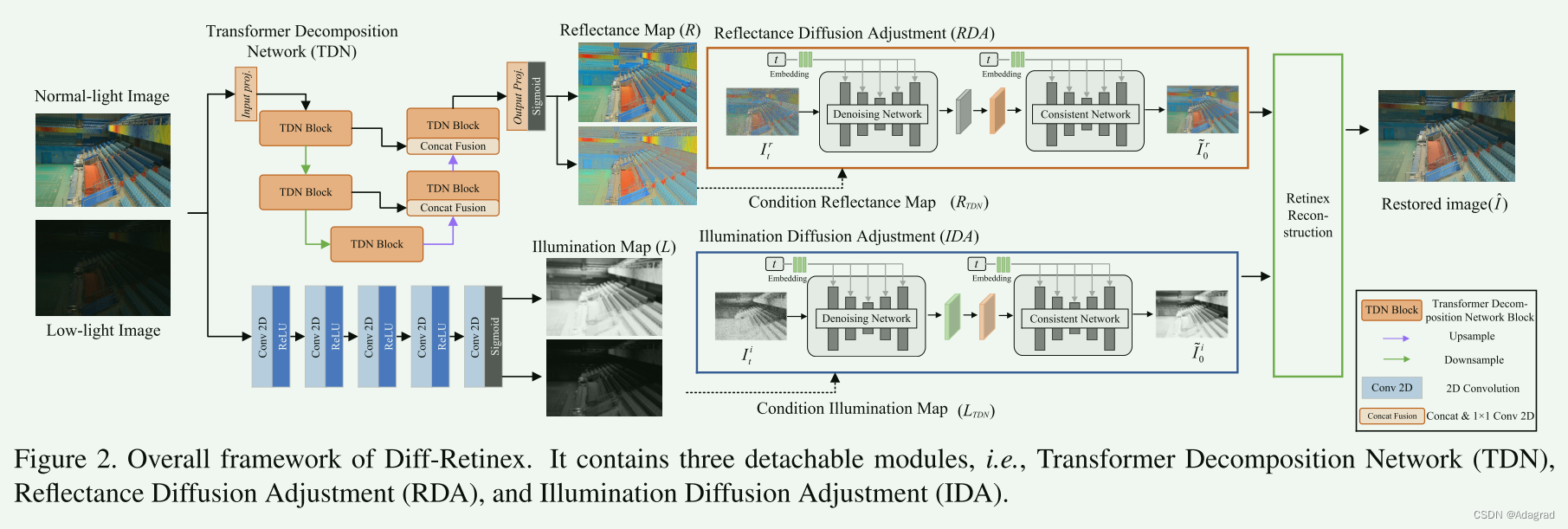
3.1. Transformer Decomposition Network
经典的 Retinex 理论假设图像可以分解为反射图和照明图,如下所示:

其中 I 是输入图像。 R 和 L 分别表示反射率和照明图。 这本质上是一个不适的问题。 反射率贴图反映了场景内容,因此在不同的光照条件下它趋于恒定。 光照贴图与光照条件相关,应呈现局部平滑度。
特别是,一些降级图像还可能带有不同程度污染的复杂噪声。 在这种情况下,我们倾向于遵循照明图局部平滑的分解性质。 因此,噪声被分解为反射率图。 在我们的方法中实现 Retinex 分解的优化目标通常由等式(2)表示:

3.1.1 Loss Functions
基于等式 (2),我们设计了以下损失函数,包括重建损失、反射一致性损失和照明平滑度损失,以优化变压器分解网络。 考虑到不同光照条件下的反射率一致性,我们使用配对的低光和正常光图像进行训练,分别表示为 Il 和 In。 由它们分解的反射率图分别表示为 Rl 和 Rn。 相应的照明图由Ll和Ln表示。
Reconstruction Loss τ(R · L).
它保证了分解后的R和L可以重建原始图像。 因此,这种损失是通过考虑图像保真度来表示的:

Reflectance Consistency Loss ϕ(R).
考虑到物体的反射率在各种光照条件下是不变的,我们限制了不同光照条件下反射率图的一致性。 具体来说,可以描述为:
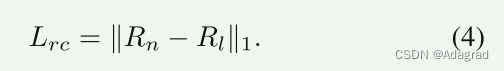
Illumination Smoothness Loss ψ(L).
考虑到照明应该是分段平滑的,我们通过以下方式约束它:

最终,总体分解损失表示为:
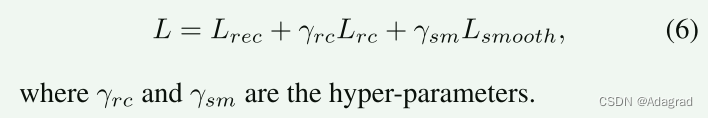
3.1.2 Network Architecture
如图2所示,变压器分解网络(TDN)由两个分支组成,即反射率分解分支和光照分解分支。
给定待分解图像 I ∈ RH×W×3,TDN 首先通过卷积投影得到其嵌入特征 。 在光照分解分支中,由多个卷积层组成,在保证分解效果的前提下减少计算量。 为了保证光照和反射率图的内在特征,并提高反射率图中的恢复性能和信息保留,反射率分解分支由多级Transformer编码器和解码器组成。 具体来说,Transformer编码器和解码器由注意力(Atten)模块和前馈网络(FFN)模块组成。 一般来说,我们将 TDN 块中的计算表示为:
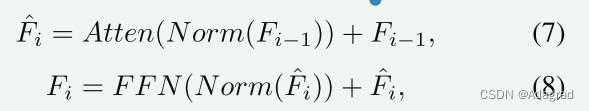
其中 Norm 表示标准化。 Fi−1 表示当前 TDN 块的输入特征图。
考虑到 Transformer 中的高注意力计算开销,时间复杂度与图像的二次大小成正比。 因此,它不适合高分辨率图像分解。 为了解决这个问题,我们设计了一种新颖的多头深度卷积层注意力(MDLA)用于计算TDN中的注意力形式,如图3所示。在保持分解性能的前提下,降低了注意力计算复杂度 在很大程度上。
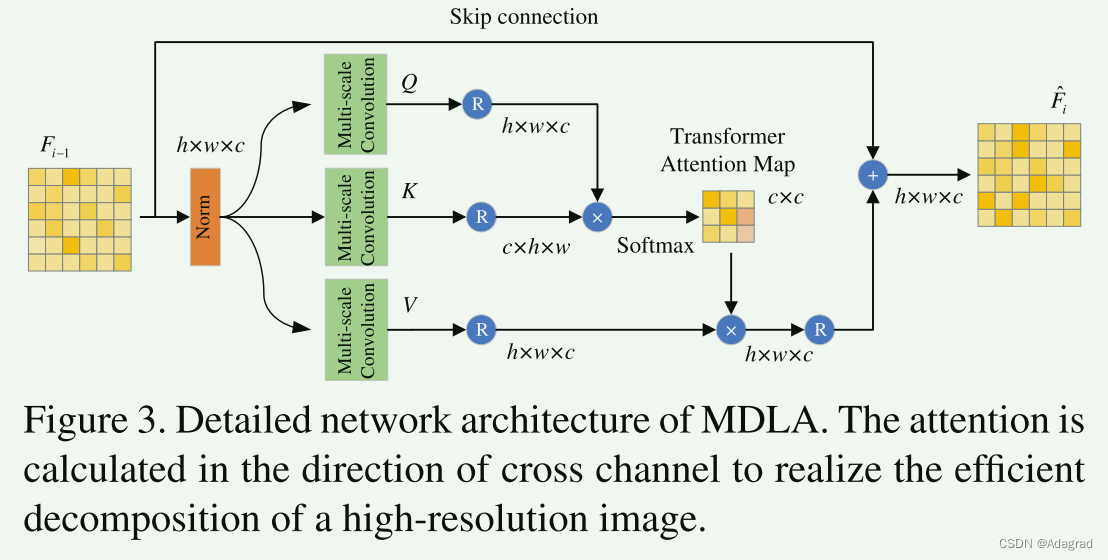

其中Wpc和Wdc是逐点和深度的卷积。 是激活函数。
3.2. Diffusion Generation Adjustment
扩散生成调整旨在构建恢复多个通道的Retinex模型的原始数据分布。 一般可分为两条路径,即反射扩散调整(RDA)和照明扩散调整(IDA)。
普通光图像分量表示为(RDA 中 C = 3,IDA 中 C = 1)用于扩散。 条件图像分别与噪声图像连接以形成引导。 我们采用去噪扩散概率模型(DDPM)[7]中提出的扩散过程来构建每个通道的 Retinex 数据的分布。 更具体地说,可以描述为正向扩散过程和反向扩散过程,如图4所示。

Forward Diffusion Process.
前向扩散过程可以看作是逐步向数据添加高斯噪声的马尔可夫链。 步骤 t 的数据仅依赖于步骤 t − 1 的数据。因此,在任意 t ∈ [0, T] 处,我们可以得到噪声图像 It 的数据分布为:
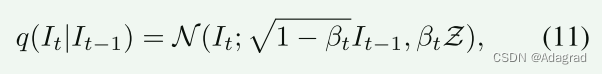
其中 βt 是控制添加到数据的噪声方差的变量。 当βt足够小时,It−1到It是一个添加少量噪声的恒定过程,即第t步的分布等于上一步添加高斯噪声的分布。 通过引入一个新变量 αt = 1 − βt,这个过程可以描述为:
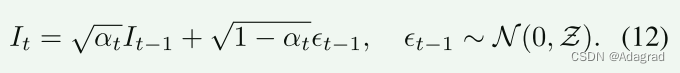
通过参数重整化,多个高斯分布被合并和简化。 我们可以得到第t步的分布q(It|I0)。 更具体地说,可以表示为:
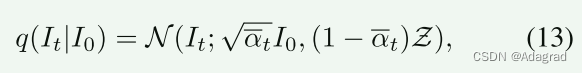

Reverse Diffusion Process.
反向扩散过程是由纯噪声的高斯分布恢复原始分布的过程。 与前向扩散过程类似,去噪扩散过程也是分步进行的。 在步骤t,在条件图像Ic的指导下对数据It进行去噪操作以获得It-1的概率分布。 因此,给定 It,我们可以将条件概率分布 It−1 表示为:

在反向扩散过程 t ∈ [0, T] 的每一步中,我们针对网络估计的噪声和实际添加的噪声 ϵ 优化目标函数。 因此,反向扩散过程的损失函数为:
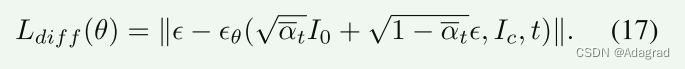
反向扩散过程中的去噪网络通常结合了UNet和attention的特点。 在RDA和IDA中,我们采用SR3[33]的主干,并遵循扩散去噪网络的设计,由多个堆叠残差块与注意力相结合组成。 根据网络预测的噪声,我们可以估计近似的 eI0。 保持接近的 eI0 和正常光图像具有一致的内容信息是有意义的。 我们采用一致的网络来实现这个过程:

总的来说,整个漫射生成调整过程就是从低光Retinex分解分布中恢复出原始的Retinex分解分布。 我们可以将整个扩散过程表述为:

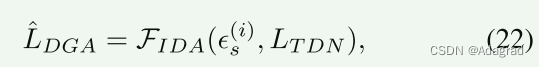

4. Experiment
4.3. Ablation Study
Transformer Decomposition Network.
为了验证 Transformer 分解网络(TDN)的有效性,我们将分解可视化。 Retinex 分解是一个不适定问题,没有精确的最优解。 一个核心点是不同光照水平下的反射率信息应该严格一致。 典型有效的表示方法采用CNN进行分解,如RetinexNet和KinD++。 反射率分解结果如图8所示。
Generative Diffusion Model.
为了验证扩散模型的有效性,一方面,我们可视化了RDA和IDA的生成过程,如图9所示。另一方面,我们通过扩散模型比较了反射率图的恢复结果 以及其他一些基于 Retinex 的一步 LLIE 方法。 我们使用反射率图来进行比较,因为它包含大量的颜色和纹理信息,对视觉感知更加敏感。 典型的基于 Retinex 的 LLIE 方法包括 RetinexNet 和 KinD++。 对于反射率恢复,RetinexNet采用BM3D,KinD++采用CNN。 结果如图10所示。由于各方法的Retinex分解结果差异很大,我们展示了他们自己从正常光图像中分解的反射率图作为地面实况进行比较。 可以看出,我们的方法可以更好地处理颜色偏差,并且在纹理恢复方面表现出更好的性能。 我们还计算了恢复的反射率图与相应的地面实况之间的 FID、LPIPS 和 BIQI,以进行定量评估。 结果报告在表3中。
4.4. Discussion
虽然 Diff-Retinex 作为低光图像增强的生成模型,表现出值得称赞的视觉效果,但它并没有在像素级误差指标(例如 PNSR)上占据主导地位,如表 2 所示。 通过更严格的约束可以得到更高的PSNR,但发电效果会有所减弱。 在本文中,我们鼓励采用生成扩散来探索低光增强任务生成效果的可能性。 当然,通过扩散模型在像素级误差上获得更好的性能也是可行和可取的。
5. Conclusion
在本文中,我们重新思考低光图像增强任务,并提出了一种生成式 Diff-Retinex 模型。 Diff-Retinex 将低光增强任务制定为分解和图像生成的范例。 它可以自适应地将图像分解为光照和反射率图,并通过生成扩散模型来解决各种退化问题。 实验结果表明,Diff-Retinex具有优异的性能,使微光图像增强的细微细节补全和推理恢复成为现实。

















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









