







Abstract
扩散模型在图像恢复任务中取得了很好的效果,但存在时间长、计算资源消耗大、恢复不稳定等问题。为了解决这些问题,我们提出了一种鲁棒和高效的基于扩散的微光图像增强方法,称为DiffLL。具体来说,我们提出了一个基于小波的条件扩散模型(WCDM),它利用扩散模型的生成能力来产生令人满意的感知保真度的结果。此外,该算法还利用小波变换的优势,在不牺牲信息的前提下大大加快推理速度,减少计算资源的使用。为了避免内容混乱和多样性,我们在wcdm的训练阶段同时进行正向扩散和反向去噪,使得模型在推理过程中能够实现稳定的去噪和减少随机性。此外,我们进一步设计了一个高频恢复模块(HFRM),利用图像的垂直和水平细节补充对角线信息,以更好地细粒度恢复。在公开的真实基准上进行的大量实验表明,我们的方法在定量和可视化上都优于现有的最先进的方法,并且与之前的基于扩散的方法相比,它在效率上取得了显著的提高。此外,我们的经验表明,应用于微光人脸检测也揭示了我们的方法潜在的实用价值。
1. Introduction
弱光照条件下获取的图像视觉质量较差,严重影响了下游视觉任务的执行和实用智能系统的性能,如图像分类[38]、物体检测[34]、自动驾驶[30]、视觉导航[13]等。在提高对比度和恢复细节方面已经取得了许多进展,可以将弱光图像转换成高质量的图像。传统的方法通常依赖于基于优化的规则,这些方法的有效性高度依赖于手工制作的先验的准确性。然而,弱光图像增强(LLIE)本质上是一个不适定问题,因为它呈现了在各种光照条件下适应这些先验的困难。
随着深度学习的兴起,这类问题得到了部分解决,基于学习的方法直接学习退化图像与对应的高质量锐化版本之间的映射,比传统方法更具鲁棒性。基于学习的方法可以分为两类:有监督的和无监督的。前者利用大规模数据集和强大的神经网络架构进行恢复,旨在优化失真指标,如PSNR和SSIM[64],但缺乏对人类感知的视觉保真度。无监督方法得益于其无标签特性,对不可见场景具有较好的泛化能力。然而,它们通常无法控制增强的程度,在某些情况下可能会产生视觉上不吸引人的结果,如过度增强或噪声放大,与监督的结果一样。如图1所示,无监督的SCI[44]和有监督的SNRNet[69]在背景区域都出现了不正确的过曝光。
因此,在感知驱动方法的基础上[22,31],生成式对抗网络(generative adversarial networks, GANs)[19,70]和变分自编码(variational autoencoders, VAEs)[79]等深层生成模型成为LLIE研究中很有前景的方法。这些方法旨在捕捉输入的多模态分布,以生成具有更好感知保真度的输出图像。最近,扩散模型(DMs)[58,61,60]因其在图像合成[17,59]和恢复任务[42,33]中的出色表现而受到关注。dm依赖于降噪自编码器的层次结构,使其能够迭代地逆转扩散过程,并实现从随机采样的高斯噪声到目标图像或潜在分布[53]的高质量映射,而不会出现以往生成模型中存在的不稳定性和模式崩溃。虽然标准dm已经足够强大,但对于某些图像恢复任务,特别是LLIE,仍然存在一些挑战。如图1所示,基于扩散的方法Palette[55]和WeatherDiff[49]生成的图像具有颜色失真或伪像,由于逆向过程是从随机采样的高斯噪声开始的,由于采样过程的多样性,最终的结果可能会有意想不到的混沌内容,尽管条件输入可以用来约束输出分布。此外,dm通常需要大量的计算资源和较长的推断时间才能实现有效的迭代去噪,如图2 (a)所示,基于扩散的方法恢复600×400大小的图像需要超过10秒的时间。

在本工作中,我们提出了一个基于扩散的框架,命名为DiffLL,用于鲁棒和高效的微光图像增强。具体来说,我们首先使用K次二维离散小波变换(2D- dwt)将微光图像转化为小波域,这样在避免信息丢失的同时显著降低了空间维数,得到表示输入图像全局信息的平均系数和表示图像垂直、水平和对角线稀疏细节的K组高频系数。因此,我们提出了一种基于小波的条件扩散模型(WCDM),该模型对平均系数进行扩散运算,而不是对原始图像空间或潜在空间进行扩散运算,以减少计算资源消耗和推理时间。如图2 (a)所示,我们的方法的速度比之前的基于扩散的方法DDIM[59]快了70倍以上。此外,在WCDM的训练阶段,我们同时进行了正向扩散和反向去噪处理。这使我们能够充分利用扩散模式的生成能力,同时教会模型在推理过程中进行稳定的去噪,防止即使是随机采样的噪声也存在内容多样性。如图1所示,我们的方法很好地提高了全局对比度,防止了对曝光良好区域的过度校正,没有任何的伪影和混乱的内容出现。此外,图2 (b)所示的感知得分也表明,我们的方法生成的图像具有更好的视觉质量。此外,通过精心设计的高频恢复模块(HFRM)重构高频系数中包含的局部细节,利用垂直和水平信息补充对角线细节,实现更好的细粒度细节恢复,从而提高整体质量。在公开数据集上的大量实验表明,我们的方法在失真和感知度量方面都优于现有的最先进的(SOTA)方法,并且与之前的基于扩散的方法相比,在效率上有显著的改进。该方法在微光人脸检测中的应用也揭示了其潜在的实用价值。我们的贡献可以总结如下:
- 我们提出了一种基于小波的条件扩散模型(WCDM),它利用扩散模型的生成能力和小波变换的优势来实现鲁棒和高效的微光图像增强。
- 我们提出了一种新的训练策略,通过在训练阶段执行正向扩散和反向去噪处理,使WCDM能够在推理过程中实现内容一致性。
- 我们进一步设计了一个高频恢复模块(HFRM),利用垂直和水平信息补充局部细节重建的对角线细节。
- 在公共现实基准上的大量实验结果表明,我们提出的方法在失真度量和感知质量方面都达到了最先进的性能,同时与之前的基于扩散的方法相比,提供了显著的速度加快。
2. Related Work
2.1. Low-light Image Enhancement
为了将弱光图像转化为视觉上令人满意的图像,人们在提高对比度和恢复细节方面做出了大量的努力。传统方法主要采用直方图均衡化(histogram equalization, HE)[2]和Retinex理论[25]来实现图像增强。基于he的方法[57,50,48]通过改变图像的直方图来提高对比度。基于Retinex的方法[36,9,21]将图像分解为光照图和反射率图,通过改变光照图中像素的动态范围,抑制反射率图中的噪声来提高图像的视觉质量。例如,LIME[11]利用基于先验假设的加权振动模型来调整估计的光照,然后使用BM3D[6]作为去除噪声的后处理步骤。
在开发基于学习的图像恢复方法[45,7,62]之后,LLNet [39]首次提出了一种用于对比度增强的深度编码器-解码器网络,并引入了数据集合成管道。RetinexNet [67]引入了在现实世界场景中捕获的第一个配对数据集,并将Retinex理论与CNN网络相结合,以估计和调整照明图。EnlightenGAN [19]通过使用生成逆向网络作为主要框架,首次采用未配对图像进行训练。Zero-DCE [10]提出将LLIE转化为曲线估计问题,并设计了一种零参考学习策略进行训练。RUAS [37]提出了一个受Retinex启发的架构搜索框架,以从紧凑的搜索空间中发现低光先验架构。SNRNet [69]利用信噪比感知变换器和CNN模型进行空间变化操作以进行恢复。更全面的调查可以在[28]中找到。
2.2. Diffusion-based Image Restoration
基于扩散的生成模型已经取得了令人鼓舞的结果,其中去噪扩散概率模型[17]得到了改进,这在图像恢复任务中变得更加有效,例如超分辨率[41,56],修复[40]和去模糊[52]。DDRM [23]使用预训练的扩散模型来解决任何线性逆问题,这在几个图像恢复任务上表现出上级最近无监督方法的结果。ShadowDiffusion [20]设计了一个展开扩散模型,通过逐步细化具有退化和生成先验的结果来实现强大的阴影去除。DR2 [66]首先使用预训练的扩散模型进行粗退化去除,然后使用增强模块进行更精细的盲脸恢复。WeatherDiff [49]提出了一种基于块的扩散模型来恢复在不利天气条件下捕获的图像,该模型在推理过程中跨重叠块采用了引导去噪过程。
虽然基于扩散的方法可以获得比基于GAN和基于VAE的生成方法更好的视觉质量的恢复图像[71,51],但由于整个网络的多次向前和向后传递,它们通常会遭受高计算资源消耗和推理时间。在本文中,我们提出了扩散模型与小波变换相结合,以显着降低在扩散过程中的输入的空间维数,实现更有效和强大的低光图像增强。
3. Method
我们提出的DiffLL的整体流水线如图3所示。我们的方法利用了扩散模型的生成能力和小波变换的优势,在不牺牲信息的情况下,每次变换后将空间维数减半,从而在提高扩散模型效率的同时实现了视觉上令人满意的图像恢复。因此,我们在小波域上进行扩散运算,而不是在图像空间上。在本节中,我们首先介绍二维离散小波变换(2D- dwt)和常规扩散模型的初步研究。然后,我们引入了基于小波的条件扩散模型(WCDM),它是我们方法的核心。最后,我们提出了高频恢复模块(HFRM),一个精心设计的组件,有助于局部细节重建和提高整体质量。
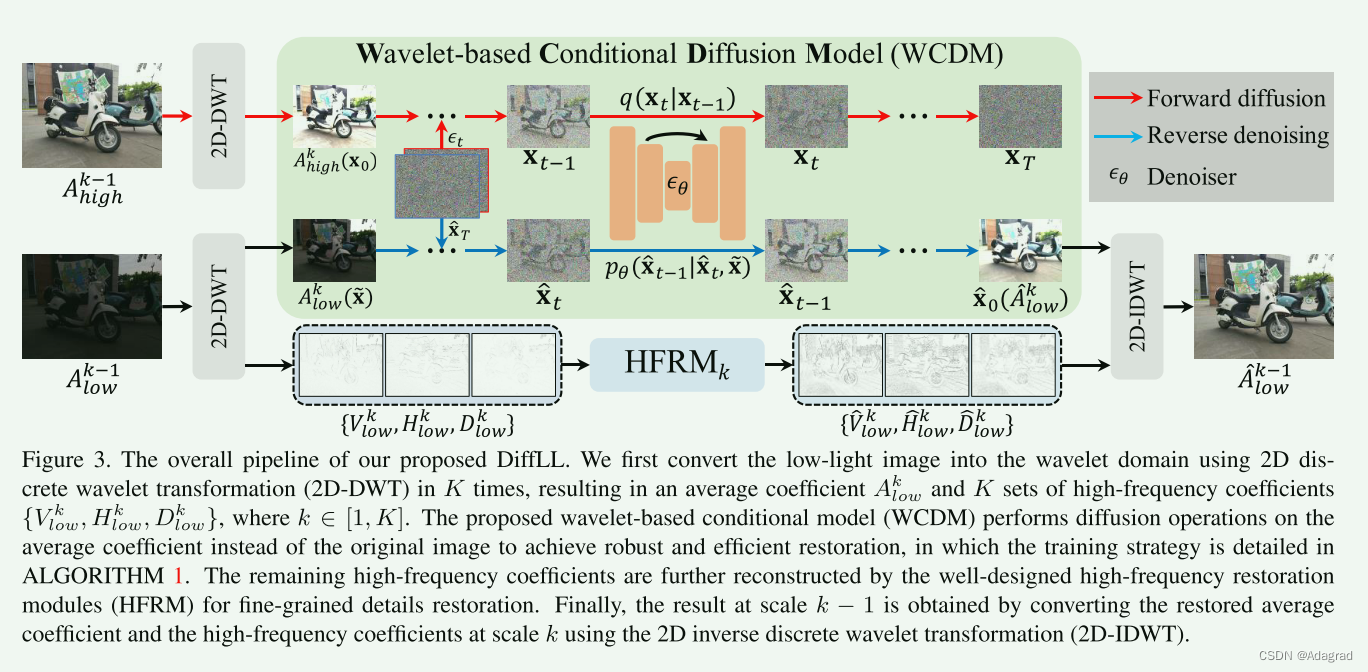
3.1. Discrete Wavelet Transformation

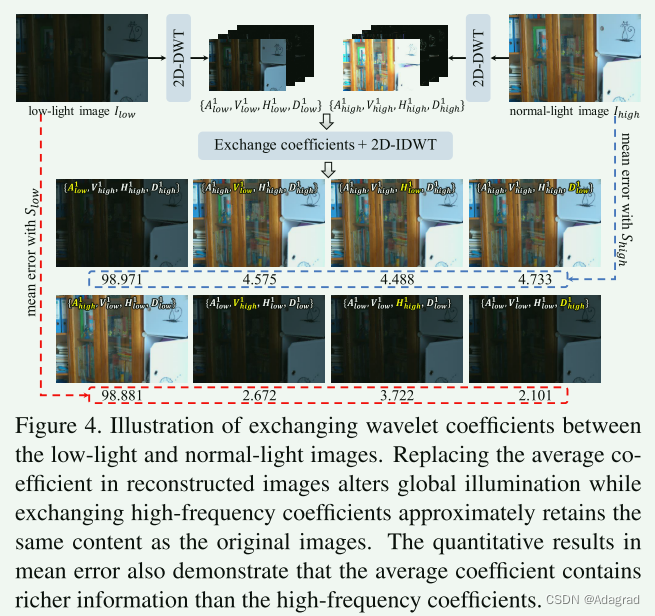
分别表示输入图像和高频信息在垂直、水平、对角线方向的平均值。其中,平均系数包含原始图像的全局信息,可以看作是图像的下采样版本,其他三个系数包含稀疏的局部细节。如图4所示,交换高频系数重构的图像仍然与原始图像内容大致相同,而替换平均系数重构的图像改变了全局信息,与原始图像误差最大。因此,在小波域中恢复弱光图像的主要重点是求得与正常光对应的自然照度一致的平均系数。为此,我们利用扩散模型的生成能力恢复平均系数,并通过HFRM重建剩余的三个高频系数,以便于局部细节恢复。
虽然经过一次小波变换后,扩散模型处理的小波分量的空间维数是原始图像的4倍,但我们进一步对平均系数进行K - 1次小波变换,即:

3.2. Conventional Conditional Diffusion Models


3.3. Wavelet-based Conditional Diffusion Models
然而,对于某些图像恢复任务,上述传统的扩散和反向过程存在两个挑战:1)大时间步长T的正向扩散,通常设置为T = 1000,小方差βt允许逆去噪过程接近高斯分布的假设,导致推理时间和计算资源消耗昂贵。2)由于逆向过程是从随机采样的高斯噪声开始的,尽管有条件的输入对采样结果的分布有强制约束,但采样过程的多样性可能导致恢复结果的内容不一致。
针对这些问题,我们提出了一种基于小波的条件扩散模型(WCDM),该模型将输入微光图像Ilow转换为小波域,并对平均系数进行扩散处理,从而大大降低了空间维数,实现了高效的恢复。此外,我们在训练阶段同时进行正向扩散和反向去噪处理,这有助于模型在推理过程中实现稳定的去噪,避免内容多样性。基于小波的条件扩散模型的训练方法在算法1中进行了总结。具体来说,我们首先进行正向扩散,通过Eq.8优化一个噪声估计器网络,然后采用带有条件输入的采样噪声ˆxT,即平均系数Ak low,进行反向去噪,导致恢复系数aˆk low。通过最小化恢复系数与参考系数Ak高之间的L2距离来实现内容一致性。因此,优化扩散模型的目标函数式(8)改写为:
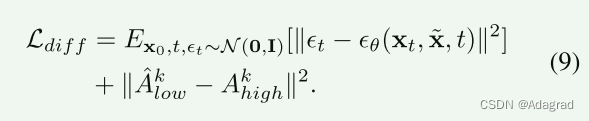
3.4. High-Frequency Restoration Module
对于微光图像的第k级小波子带,高频系数Vk low、Hk low、Dk low对图像的垂直、水平、对角线细节进行稀疏表示。为了恢复微光图像,以包含像正常光图像一样丰富的信息,我们提出了一个高频恢复模块(HFRM)来重建这些系数。如图5所示,为了提高效率,我们首先使用三个深度可分卷积[4]提取输入系数的特征,然后使用两个交叉注意层[18]利用V和H中的信息补充d中的细节。随后,受到[15]的启发,我们设计了一种利用扩张卷积进行局部恢复的渐进扩张Resblock,利用第一卷积和最后卷积提取局部信息,并利用中间扩张卷积改进接收域,以更好地利用远程信息。通过逐渐增大和减小膨胀率d,可以避免网格效应。最后,利用三种深度可分卷积对信道进行约简,得到重构Vˆk low、ˆHk low和ˆDk low。采用二维逆离散小波变换(2D- idwt)将k尺度下恢复的平均系数和高频系数相应转换为k−1尺度下的输出,即:
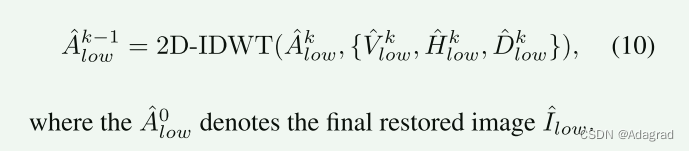
3.5. Network Training
除了使用目标函数Ldiff对扩散模型进行优化外,我们还使用类似于[37]的结合MSE损失和TV损失[3]的细节保留损失Ldetail来重建高频系数,即:

4. Experiment
4.5. Limitations
虽然我们的方法可以有效地恢复在弱光照条件下捕获的图像,但在极低光照环境下却不能很好地工作,因为在这种条件下捕获的图像会遭受更大的信息损失,恢复更具挑战性。此外,一些实时方法可以直接应用于微光视频增强任务,而我们的方法还不够有效,不能直接应用于该任务。我们的模型的另一个自然的局限性是它固有的有限的能力,只能泛化到训练时间观察到的LLIE任务,研究所提出的方法对其他图像恢复任务的有效性将是我们未来的工作。
5. Conclusions
我们提出了DiffLL,一个基于扩散的框架,用于鲁棒和高效的微光图像增强。在技术上,我们提出了一种基于小波的条件扩散模型,该模型利用扩散模型和小波变换的生成能力来产生视觉上满意的结果,同时减少推理时间和计算资源的消耗。此外,为了避免推理过程中的内容多样性,我们在训练阶段和推理阶段都进行了反向去噪处理,使模型能够学习稳定的去噪,并获得一致的恢复结果。此外,我们设计了一个高频恢复模块,以补充垂直和水平的信息,以更好的细粒度细节重建对角线细节。在公开的基准测试上的实验结果表明,我们的方法在计算效率方面,在定量和定性上都优于竞争对手。微光人脸检测的结果也表明了该方法的实用价值。代码将被发布,以促进未来的研究。

















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









