







PyTorch 数据加载实用程序的核心是 torch.utils.data.DataLoader 类。它代表一个可在数据集上迭代的 Python,支持
这些选项由具有签名的 DataLoader 的构造函数参数配置:
DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=None,pin_memory=False,drop_last=False,timeout=0,worker_init_fn=None,*,prefetch_factor=2,persistent_workers=False)
以下部分详细描述了这些选项的作用和用法。
Dataset Types
DataLoader 构造函数最重要的参数是数据集,它指示要从中加载数据的数据集对象。 PyTorch 支持两种不同类型的数据集:
Map-style datasets
地图样式数据集是实现 __getitem__() 和 __len__() 协议的数据集,表示从(可能是非整数的)索引/键到数据样本的映射。
例如,这样的数据集,当使用数据集 [idx] 访问时,可以从磁盘上的文件夹中读取第 idx 个图像及其对应的标签。
有关详细信息,请参阅数据集。
Iterable-style datasets
可迭代风格的数据集是 IterableDataset 子类的一个实例,它实现了 __iter__() 协议,并表示可迭代的数据样本。这种类型的数据集特别适用于随机读取代价高昂甚至不可能的情况,以及批量大小取决于获取的数据的情况。
例如,当调用 iter(dataset) 时,这样的数据集可以返回从数据库、远程服务器甚至实时生成的日志读取的数据流。
有关详细信息,请参阅 IterableDataset。
NOTE
使用具有多进程数据加载的 IterableDataset 时。在每个工作进程上复制相同的数据集对象,因此必须对副本进行不同的配置以避免重复数据。有关如何实现此目的,请参阅 IterableDataset 文档。
Data Loading Order and Sampler
对于可迭代风格的数据集,数据加载顺序完全由用户定义的可迭代对象控制。这允许更容易地实现块读取和动态批量大小(例如,通过每次产生一个批量样本)。
本节的其余部分涉及地图样式数据集的情况。 torch.utils.data.Sampler 类用于指定数据加载中使用的索引/键的顺序。它们表示数据集索引上的可迭代对象。例如,在随机梯度下降 (SGD) 的常见情况下,采样器可以随机排列索引列表并一次生成每个索引,或者为小批量 SGD 生成少量索引。
顺序或混洗采样器将根据 DataLoader 的混洗参数自动构造。或者,用户可以使用 sampler 参数来指定一个自定义 Sampler 对象,该对象每次都会产生下一个要获取的索引/键。
一次生成批量索引列表的自定义采样器可以作为 batch_sampler 参数传递。也可以通过 batch_size 和 drop_last 参数启用自动批处理。有关这方面的更多详细信息,请参阅下一节。
NOTE
sampler 和 batch_sampler 都不兼容可迭代样式的数据集,因为此类数据集没有键或索引的概念。
Loading Batched and Non-Batched Data
DataLoader 支持通过参数 batch_size、drop_last 和 batch_sampler 自动将单个获取的数据样本整理成批次。
Automatic batching (default)
这是最常见的情况,对应于获取一个小批量数据并将它们整理成批量样本,即包含一个维度为批量维度(通常是第一个)的张量。
当 batch_size(默认为 1)不是 None 时,数据加载器会生成批量样本而不是单个样本。 batch_size 和 drop_last 参数用于指定数据加载器如何获取批量数据集键。对于地图样式的数据集,用户可以选择指定 batch_sampler,一次生成一个键列表。
NOTE
batch_size 和 drop_last 参数本质上用于从采样器构造 batch_sampler。对于地图样式数据集,采样器由用户提供或基于 shuffle 参数构建。对于可迭代风格的数据集,采样器是一个虚拟的无限采样器。有关采样器的更多详细信息,请参阅本节。
NOTE
当从具有多处理的可迭代样式数据集中获取时,drop_last 参数会删除每个工作人员的数据集副本的最后一个非完整批次。
在使用采样器的索引获取样本列表后,作为 collate_fn 参数传递的函数用于将样本列表整理成批次。
在这种情况下,从地图样式数据集加载大致相当于:
for indices in batch_sampler:
yield collate_fn([dataset[i] for i in indices])从可迭代风格的数据集加载大致相当于:
dataset_iter = iter(dataset)
for indices in batch_sampler:
yield collate_fn([next(dataset_iter) for _ in indices])自定义 collate_fn 可用于自定义排序规则,例如,将顺序数据填充到批处理的最大长度。有关 collate_fn 的更多信息,请参阅本节。
Disable automatic batching
在某些情况下,用户可能希望在数据集代码中手动处理批处理,或者只是加载单个样本。例如,直接加载批处理数据(例如,从数据库批量读取或读取连续的内存块)可能更便宜,或者批处理大小取决于数据,或者程序设计用于处理单个样本。在这些情况下,最好不要使用自动批处理(其中使用 collate_fn 来整理样本),而是让数据加载器直接返回数据集对象的每个成员。
当 batch_size 和 batch_sampler 都为 None 时(batch_sampler 的默认值已经为 None),自动批处理被禁用。从数据集中获得的每个样本都使用作为 collate_fn 参数传递的函数进行处理。
当禁用自动批处理时,默认的 collate_fn 只是将 NumPy 数组转换为 PyTorch 张量,并保持其他一切不变。
在这种情况下,从地图样式数据集加载大致相当于:
for index in sampler:
yield collate_fn(dataset[index])从可迭代风格的数据集加载大致相当于:
for data in iter(dataset):
yield collate_fn(data)有关 collate_fn 的更多信息,请参阅本节。
Working with collate_fn
启用或禁用自动批处理时,collate_fn 的使用略有不同。
禁用自动批处理时,将对每个单独的数据样本调用 collate_fn,并从数据加载器迭代器产生输出。在这种情况下,默认的 collate_fn 只是将 NumPy 数组转换为 PyTorch 张量。
启用自动批处理后,每次都会使用数据样本列表调用 collate_fn。预计将输入样本整理成批次,以便从数据加载器迭代器中产生。本节的其余部分描述了这种情况下默认 collate_fn 的行为。
例如,如果每个数据样本由一个 3 通道图像和一个完整的类标签组成,即数据集的每个元素返回一个元组 (image, class_index),则默认的 collate_fn 将此类元组的列表整理成单个元组一个批处理的图像张量和一个批处理的类标签张量。特别是,默认的 collate_fn 具有以下属性:
它总是在前面加上一个新维度作为批次维度。
它自动将 NumPy 数组和 Python 数值转换为 PyTorch 张量。
它保留了数据结构,例如,如果每个样本都是一个字典,它会输出一个具有相同键集但批处理张量作为值的字典(如果值不能转换为张量,则输出列表)。对于 list s、tuple s、namedtuple s 等也是如此。
用户可以使用自定义的 collate_fn 来实现自定义批处理,例如,沿着除第一个维度之外的维度进行整理,各种长度的填充序列,或添加对自定义数据类型的支持。
Single- and Multi-process Data Loading
DataLoader 默认使用单进程数据加载。
在 Python 进程中,全局解释器锁 (GIL) 会阻止跨线程真正完全并行化 Python 代码。为了避免数据加载阻塞计算代码,PyTorch 提供了一个简单的开关来执行多进程数据加载,只需将参数 num_workers 设置为正整数即可。
Single-process data loading (default)
在这种模式下,数据获取是在初始化 DataLoader 的同一进程中完成的。因此,数据加载可能会阻塞计算。但是,当用于在进程之间共享数据的资源(例如,共享内存、文件描述符)有限,或者当整个数据集很小并且可以完全加载到内存中时,这种模式可能是首选。此外,单进程加载通常显示更易读的错误跟踪,因此对调试很有用。
Multi-process data loading
将参数 num_workers 设置为正整数将打开具有指定数量的加载程序工作进程的多进程数据加载。
在这种模式下,每次创建 DataLoader 的迭代器时(例如,当您调用 enumerate(dataloader) 时),都会创建 num_workers 个工作进程。此时,数据集、collate_fn 和 worker_init_fn 被传递给每个 worker,用于初始化和获取数据。这意味着数据集访问及其内部 IO、转换(包括 collate_fn)在工作进程中运行。
torch.utils.data.get_worker_info() 在worker进程中返回各种有用的信息(包括worker id、dataset replica、initial seed等),在main进程中返回None。用户可以在数据集代码和/或 worker_init_fn 中使用此函数来单独配置每个数据集副本,并确定代码是否在工作进程中运行。例如,这在分片数据集时特别有用。
对于地图样式的数据集,主进程使用采样器生成索引并将它们发送给工作人员。因此,任何洗牌随机化都是在主要过程中完成的,该过程通过分配索引来引导加载。
对于可迭代样式的数据集,由于每个工作进程都会获得数据集对象的副本,因此简单的多进程加载通常会导致重复数据。使用 torch.utils.data.get_worker_info() 和/或 worker_init_fn,用户可以独立配置每个副本。 (有关如何实现此目的,请参阅 IterableDataset 文档。)出于类似的原因,在多进程加载中,drop_last 参数会删除每个 worker 的可迭代样式数据集副本的最后一个非完整批次。
一旦达到迭代结束,或者当迭代器被垃圾收集时,worker 将被关闭。
警告
通常不建议在多进程加载中返回 CUDA 张量,因为在多进程中使用 CUDA 和共享 CUDA 张量有很多微妙之处(参见 CUDA in multiprocessing)。相反,我们建议使用自动内存固定(即设置 pin_memory=True),这样可以将数据快速传输到支持 CUDA 的 GPU。
特定于平台的行为
由于 worker 依赖 Python 多处理,因此与 Unix 相比,Windows 上的 worker 启动行为有所不同。
在 Unix 上,fork() 是默认的多进程启动方法。使用 fork(),子 worker 通常可以直接通过克隆的地址空间访问数据集和 Python 参数函数。
在 Windows 或 MacOS 上,spawn() 是默认的多进程启动方法。使用 spawn() 启动另一个解释器,它运行您的主脚本,然后是内部工作函数,该函数通过 pickle 序列化接收数据集、collate_fn 和其他参数。
这种单独的序列化意味着你应该采取两个步骤来确保你在使用多进程数据加载时与 Windows 兼容:
将大部分主脚本的代码包装在 if __name__ == '__main__': 块中,以确保在启动每个工作进程时它不会再次运行(很可能会产生错误)。您可以将数据集和 DataLoader 实例创建逻辑放在这里,因为它不需要在 workers 中重新执行。
确保在 __main__ 检查之外将任何自定义 collate_fn、worker_init_fn 或数据集代码声明为顶级定义。这确保它们在工作进程中可用。 (这是必需的,因为函数仅作为引用被腌制,而不是字节码。)
多进程数据加载的随机性
默认情况下,每个 worker 都将其 PyTorch 种子设置为 base_seed + worker_id,其中 base_seed 是由主进程使用其 RNG(因此,强制使用 RNG 状态)或指定生成器生成的 long。但是,其他库的种子可能会在初始化工作人员时重复,导致每个工作人员返回相同的随机数。 (请参阅常见问题解答中的此部分。)。
在 worker_init_fn 中,您可以使用 torch.utils.data.get_worker_info().seed 或 torch.initial_seed() 访问每个 worker 的 PyTorch 种子集,并在数据加载之前使用它为其他库播种。
Memory Pinning
当它们源自固定(页面锁定)内存时,主机到 GPU 的副本要快得多。有关通常何时以及如何使用固定内存的更多详细信息,请参阅使用固定内存缓冲区。
对于数据加载,将 pin_memory=True 传递给 DataLoader 会自动将获取的数据张量放入固定内存中,从而可以更快地将数据传输到支持 CUDA 的 GPU。
默认内存固定逻辑仅识别张量和包含张量的映射和可迭代对象。默认情况下,如果固定逻辑发现一个批次是自定义类型(如果您有一个返回自定义批次类型的 collate_fn 就会发生这种情况),或者如果您的批次中的每个元素都是自定义类型,则固定逻辑将无法识别它们,它将返回该批次(或那些元素)而不固定内存。要为自定义批处理或数据类型启用内存固定,请在您的自定义类型上定义一个 pin_memory() 方法。
请参见下面的示例。
例子:
class SimpleCustomBatch:
def __init__(self, data):
transposed_data = list(zip(*data))
self.inp = torch.stack(transposed_data[0], 0)
self.tgt = torch.stack(transposed_data[1], 0)
# custom memory pinning method on custom type
def pin_memory(self):
self.inp = self.inp.pin_memory()
self.tgt = self.tgt.pin_memory()
return self
def collate_wrapper(batch):
return SimpleCustomBatch(batch)
inps = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
tgts = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
dataset = TensorDataset(inps, tgts)
loader = DataLoader(dataset, batch_size=2, collate_fn=collate_wrapper,
pin_memory=True)
for batch_ndx, sample in enumerate(loader):
print(sample.inp.is_pinned())
print(sample.tgt.is_pinned())CLASStorch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
数据加载器。结合数据集和采样器,并提供对给定数据集的迭代。
DataLoader 支持具有单进程或多进程加载、自定义加载顺序和可选的自动批处理(整理)和内存固定的映射样式和可迭代样式数据集。
有关详细信息,请参阅 torch.utils.data 文档页面。
参数
数据集 (Dataset) – 从中加载数据的数据集。
batch_size (int, optional) – 每批加载多少个样本(默认值:1)。
shuffle (bool, optional) – 设置为 True 以在每个时期重新洗牌数据(默认值:False)。
采样器(Sampler 或 Iterable,可选)——定义从数据集中抽取样本的策略。可以是任何实现了 __len__ 的 Iterable。如果指定,则不得指定 shuffle。
batch_sampler (Sampler or Iterable, optional) – 像采样器,但一次返回一批索引。与 batch_size、shuffle、sampler 和 drop_last 互斥。
num_workers (int, optional) – 用于数据加载的子进程数。 0 表示数据将在主进程中加载。 (默认值:0)
collate_fn (callable, optional) – 合并样本列表以形成一个小批量的张量。在使用地图样式数据集的批量加载时使用。
pin_memory (bool, optional) – 如果为真,数据加载器将在返回张量之前将张量复制到 CUDA 固定内存中。如果您的数据元素是自定义类型,或者您的 collate_fn 返回自定义类型的批处理,请参见下面的示例。
drop_last (bool, optional) – 如果数据集大小不能被批次大小整除,则设置为 True 以删除最后一个不完整的批次。如果为 False 且数据集的大小不能被批量大小整除,则最后一批会更小。 (默认值:假)
timeout (numeric, optional) – 如果为正,则为从 worker 收集批次的超时值。应始终为非负数。 (默认值:0)
worker_init_fn (callable, optional) – 如果不是 None,这将在每个 worker 子进程上以 worker id([0, num_workers - 1] 中的一个 int)作为输入,在播种之后和数据加载之前调用。 (默认值:无)
generator (torch.Generator, optional) – 如果不是 None,这个 RNG 将被 RandomSampler 用来生成随机索引和 multiprocessing 来为 worker 生成 base_seed。 (默认值:无)
prefetch_factor (int, optional, keyword-only arg) – 每个工作人员预先加载的样本数。 2 意味着将有总共 2 * num_workers 个样本预取给所有的工人。 (默认值:2)
persistent_workers (bool, optional) – 如果为 True,数据加载器将不会在数据集被使用一次后关闭工作进程。这允许使工作人员数据集实例保持活动状态。 (默认值:假)
警告
如果使用 spawn start 方法,则 worker_init_fn 不能是 unpicklable 对象,例如 lambda 函数。有关 PyTorch 中多处理的更多详细信息,请参阅多处理最佳实践。
警告
len(dataloader) 启发式基于所用采样器的长度。当数据集是 IterableDataset 时,它会返回基于 len(dataset) / batch_size 的估计值,并根据 drop_last 进行适当的舍入,而不管多进程加载配置如何。这代表了 PyTorch 可以做出的最佳猜测,因为 PyTorch 相信用户数据集代码会正确处理多进程加载以避免重复数据。
然而,如果分片导致多个工人的最后一批不完整,这个估计仍然不准确,因为(1)一个完整的批可以分成多个,(2)当 drop_last 时可以丢弃超过一批的样本已设置。不幸的是,PyTorch 一般无法检测到此类情况。
有关这两种类型的数据集以及 IterableDataset 如何与多进程数据加载交互的更多详细信息,请参阅数据集类型。
警告
请参阅再现性和我的数据加载器工作人员返回相同的随机数,以及随机种子相关问题的多进程数据加载笔记中的随机性。
CLASStorch.utils.data.Dataset
表示数据集的抽象类。
所有表示从键到数据样本的映射的数据集都应该对其进行子类化。所有子类都应该覆盖 __getitem__(),支持获取给定键的数据样本。子类还可以选择性地覆盖 __len__(),许多 Sampler 实现和 DataLoader 的默认选项都希望它返回数据集的大小。
笔记
默认情况下,DataLoader 构造一个生成整数索引的索引采样器。要使其与具有非整数索引/键的地图样式数据集一起使用,必须提供自定义采样器。
CLASStorch.utils.data.IterableDataset
一个可迭代的数据集。
表示可迭代数据样本的所有数据集都应该对其进行子类化。当数据来自流时,这种形式的数据集特别有用。
所有子类都应覆盖 __iter__(),它将返回此数据集中样本的迭代器。
当子类与 DataLoader 一起使用时,数据集中的每个项目都将从 DataLoader 迭代器产生。当 num_workers > 0 时,每个工作进程将拥有数据集对象的不同副本,因此通常需要独立配置每个副本以避免从工作进程返回重复数据。 get_worker_info() 在工作进程中调用时,返回有关工作人员的信息。它可以用于数据集的 __iter__() 方法或 DataLoader 的 worker_init_fn 选项来修改每个副本的行为。
示例 1:在 __iter__() 中将工作负载分配给所有 worker:
>>> class MyIterableDataset(torch.utils.data.IterableDataset):
... def __init__(self, start, end):
... super(MyIterableDataset).__init__()
... assert end > start, "this example code only works with end >= start"
... self.start = start
... self.end = end
...
... def __iter__(self):
... worker_info = torch.utils.data.get_worker_info()
... if worker_info is None: # single-process data loading, return the full iterator
... iter_start = self.start
... iter_end = self.end
... else: # in a worker process
... # split workload
... per_worker = int(math.ceil((self.end - self.start) / float(worker_info.num_workers)))
... worker_id = worker_info.id
... iter_start = self.start + worker_id * per_worker
... iter_end = min(iter_start + per_worker, self.end)
... return iter(range(iter_start, iter_end))
...
>>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
>>> ds = MyIterableDataset(start=3, end=7)
>>> # Single-process loading
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[3, 4, 5, 6]
>>> # Mult-process loading with two worker processes
>>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[3, 5, 4, 6]
>>> # With even more workers
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=20)))
[3, 4, 5, 6]示例 2:使用 worker_init_fn 将工作负载分配给所有 worker:
>>> class MyIterableDataset(torch.utils.data.IterableDataset):
... def __init__(self, start, end):
... super(MyIterableDataset).__init__()
... assert end > start, "this example code only works with end >= start"
... self.start = start
... self.end = end
...
... def __iter__(self):
... return iter(range(self.start, self.end))
...
>>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
>>> ds = MyIterableDataset(start=3, end=7)
>>> # Single-process loading
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[3, 4, 5, 6]
>>>
>>> # Directly doing multi-process loading yields duplicate data
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[3, 3, 4, 4, 5, 5, 6, 6]
>>> # Define a `worker_init_fn` that configures each dataset copy differently
>>> def worker_init_fn(worker_id):
... worker_info = torch.utils.data.get_worker_info()
... dataset = worker_info.dataset # the dataset copy in this worker process
... overall_start = dataset.start
... overall_end = dataset.end
... # configure the dataset to only process the split workload
... per_worker = int(math.ceil((overall_end - overall_start) / float(worker_info.num_workers)))
... worker_id = worker_info.id
... dataset.start = overall_start + worker_id * per_worker
... dataset.end = min(dataset.start + per_worker, overall_end)
...
>>> # Mult-process loading with the custom `worker_init_fn`
>>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2, worker_init_fn=worker_init_fn)))
[3, 5, 4, 6]
>>> # With even more workers
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=20, worker_init_fn=worker_init_fn)))
[3, 4, 5, 6]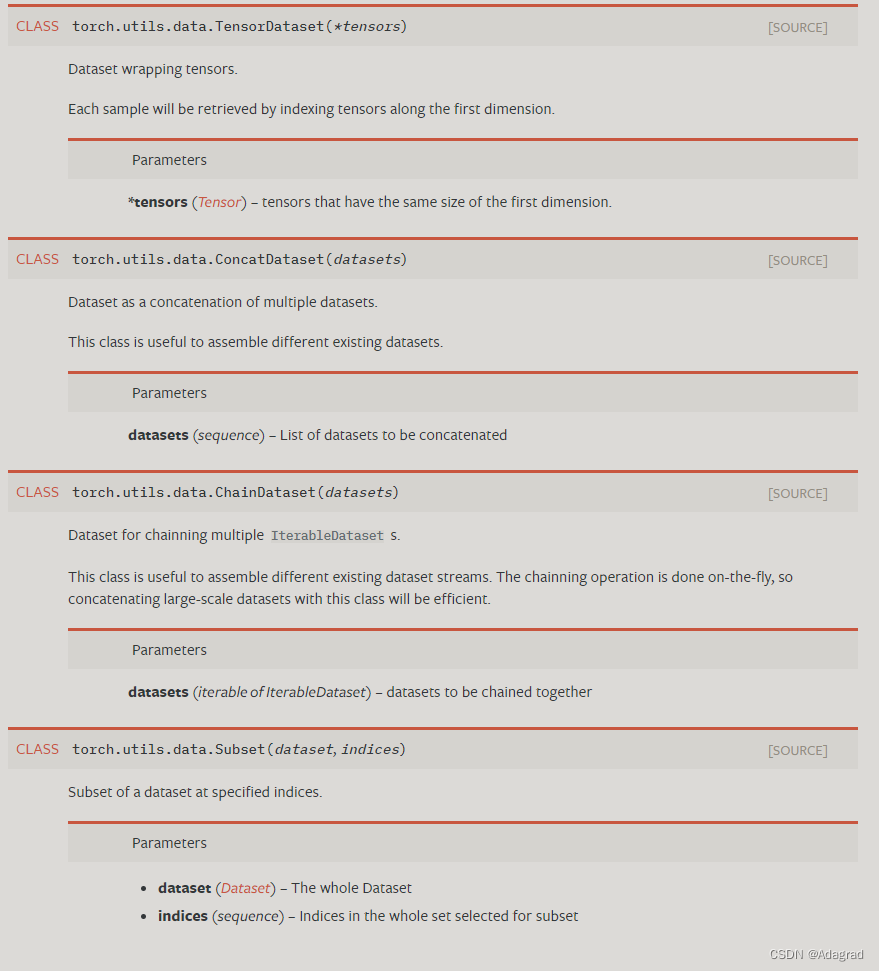



















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









