







ABSTRACT
目前发布的色调映射操作符(TMO)通常是在非常有限的高动态范围(HDR)图像测试集上进行评估的。因此,所产生的性能指标高度受制于广泛的超参数调整,并且当在更广泛的HDR图像上进行测试时,许多TMO表现出次优性能。这表明在这些技术的普遍适用性方面存在不足。最后,由于大规模HDR数据集的缺乏,使用需要数据的高级深度学习方法开发无参数色调映射算子是一个挑战。本文从以下几个方面对这些问题进行了研究:a)创建了一个具有多种场景和光照条件变化的大规模HDR图像基准数据集(LVZ-HDR DataSet),以实现对不同条件和场景的TMO的性能评估,这也将有助于使用最先进的深度学习方法开发更健壮的TMO;b)提出了一种基于深度学习的色调映射算子(TMO-Net),它提供了一种能够在更广泛的HDR内容范围内有效推广的高效且无参数的方法;C)最后,在新的LVZ-HDR数据集上对19个最先进的TMO进行了比较分析和性能基准测试。使用色调映射质量指数(TMQI)、色调映射图像特征相似性指数(FSITM)和自然图像质量评价器(NIQE)等标准度量来定性地评估基准TMO的性能指标。实验结果表明,所提出的TMONet在定性和定量上都优于目前最先进的TMOS。
I. INTRODUCTION
尽管经过20年的研究和几十种算法的提出,高动态范围图像的色调映射仍然是一个难题。基本的挑战很简单:真实的世界包含许多具有巨大动态范围的场景,但大多数图像格式仅使用8位存储亮度,大多数显示器也同样受到限制。即使是具有扩展动态范围的显示器也无法再现世界上可见的亮度范围。因此,几乎总是需要降低HDR图像的整体对比度,使得图像可以被传输并显示在低动态范围(LDR)显示器上。
已经提出了过多的色调映射算子来压缩HDR图像的动态范围,同时保持令人愉悦和自然的外观。每种方法都致力于提供对以前方法的改进,以实现高质量的渲染[1]-[6]。然而,由于缺乏标准化数据集,这些方法通常只在少数图像上进行测试,而不考虑各种场景和照明[7]。
克服超参数调优的挑战以实现良好的结果往往被低估。此外,当超参数被赋予非描述性名称(如“alpha”和“beta”)时,很难评估超参数的信息背景,并且没有关于如何直观地选择其最佳值的明确指导或分析。因此,色调映射算子在与这些超参数未知的其他HDR图像一起呈现时受到严重挑战。
例如,通常会发现一些运算符在白天图像上工作得很好,但在夜间图像上效率低得多,反之亦然。手动导航超参数空间以产生最令人满意的结果的过程是低效的,并且阻碍了TMO的更广泛采用。由于这些挑战,一些流行的商业应用[8]已经放弃色调映射作为可行的解决方案。相反,使用多次曝光来创建HDR图像,并由此合成两个LDR图像,然后进行曝光融合[9],[10]。仍然需要一个更强大的和可推广的色调映射算子的超参数。
最近的色调映射算子使用了深度神经网络方法(特别是生成对抗网络)来解决上述的一些限制[7],[11]。然而,由于缺乏标准的大规模HDR数据集,很难开发和比较用于色调映射的深度学习算法。标准数据集的缺乏也使得传统TMO的定量基准和评估该领域的进展变得更加困难。
这项工作通过以下贡献解决了这些问题:
1)首先,创建了一个场景和光照条件高度可变的大规模HDR图像基准数据集(LVZ-HDR数据集),以促进对TMO的性能评估,并使用最先进的深度学习方法来促进开发更健壮、更可推广的TMO。
2)其次,提出一种基于深度学习的色调映射算子(TMO-Net)。该算子具有高效、无参数的特点,在广泛的HDR场景中表现良好。
3)最后,利用TMQI、FSITM和其他相关评估指标,对19个最新的TMO在大规模LVZ-HDR数据集上进行了性能对比分析和性能基准测试。
4)最后,进行了一个主观实验,验证了所提出的TMO-Net的定性性能和优点。
本文的其余部分组织如下:第2节详细介绍了各种类型的传统TMO,以及最新的神经网络方法。第3节详细介绍了拟议的TMONet的网络架构、目标功能和工作原理。第4节详细介绍了LVZ-HDR数据集的创建方式,并描述了所选的评价指标。第5节评估和分析了所选色调映射算法在所提出的数据集上的性能,并提供了基准测试结果。最后,第6节总结了研究结果,提出了局限性并建议了未来工作的方向。
II. RELATED WORK
鉴于色调映射在图像处理流水线中的持续相关性,已经提出了许多色调映射算子。传统的TMO可以分为全局[2],[12]-[16],局部[13],[15],[17],分割[1],[18]和基于梯度的运算符[4],[12],[19]- [21],这取决于这些运算符如何应用于HDR图像。
全局算子试图保留图像中的全局对比度,因此该算子会立即应用于所有像素。 塔布林等人。 [12]提出了一种受人类视觉系统启发的操作员来显示高对比度图像。 通过压缩 HDR 图像,该 TMO 可以保留全局亮度,但需要校准的亮度值才能产生良好的结果。 全局算子的另一个例子是 Pattanaik 等人提出的时间相关视觉适应。 [14]。 操作员考虑动画或交互式实时模拟中的外观变化,并尝试将用户的视觉响应与用户在现实世界场景中体验到的视觉响应相匹配。 色调映射算子基于全局直方图调整,再现图像的高动态范围,然后使用双边加权方案去除分割后经常引入的边界和光晕伪影。 德拉戈等人。 [13] 提出使用自适应对数映射来实现更鲁棒的渲染,而 Durand 和 Dorsey [17] 和 Schlick [2] 分别提出了基于直方图调整的色调映射和基于量化的技术,以在输出色调映射中更好地增强全局对比度 图像。 不幸的是,色调映射图像的输出可能会在色调映射过程中丢失其局部细节。
另一方面,与全局算子相反,局部算子[13]、[15]-[17]将映射算子相对于其相邻像素应用于每个像素。 分解每个感兴趣像素周围的相邻像素的局部统计数据可以指导操作员再现原始场景的局部和全局对比度。 莱因哈德等人。 [16]提出了一种使用邻域像素的局部统计来再现摄影色调的方法,该统计模拟了摄影师应用的燃烧(添加更多光)和闪避(从打印的一部分中抑制光)效果。 首先,应用与相机曝光相关的缩放,然后应用自动减淡和加深以在需要时完成动态范围压缩。 自动闪避和加深充当本地操作员,以提高结果质量并避免光晕伪影。 金等人。 [15]提出了一种基于retinex模型的局部算子,通过引入k因子决策来增强HDR图像的外观和自然度,并消除设置参数的负担。 k 是 retinex 算法的参数,根据图像的动态范围进行选择。 莱达等人。 [18]使用局部眼睛适应模型来确保适当的局部和全局一致性。
基于分割的算子[1]、[18]、[20]将图像划分为不同的统一区域,并在合并之前对每个区域应用全局算子。 这有助于最大限度地减少对原始色域的修改。 Yee 和 Pattanaik [20] 提出使用图像分割,其中涉及使用基于直方图的技术将图像划分为多个区域,并使用洪水填充方法对相邻像素进行分组。 克劳西克等人。 [21]还提出在色调再现中使用亮度感知; 和利辛斯基等人。 [1]建议使用交互式局部调整色调值。
基于频率/梯度的算子[4]、[12]、[14]、[19]-[21]尝试分离图像的低频和高频分量,目的是保留图像中的高频分量。 人类视觉系统对较低频率更加敏感并将操作员应用到较低频率。 Tumblin 和 Turk [4] 受各向异性扩散的启发,使用偏微分方程提出了一种低曲率图像简化器 (LCIS) 滤波器。 此滤镜保留局部对比度,而不会丢失原始图像中的精细细节和纹理。 法塔尔等人。 [22]通过抑制大梯度的幅度并保持小梯度来保留精细细节来操纵亮度图像的梯度场。 通过求解修改后的梯度场上的泊松方程,可以生成低动态范围图像。
上述传统色调映射算子的主要缺点是参数敏感性高,这使得这些方法无法很好地推广到更广泛的 HDR 成像内容。 最新的方法倾向于利用深度神经网络的巨大成功,开发无参数算子来解决参数敏感性的挑战和传统色调映射算子的泛化问题[7],[11]。
特别是,生成对抗网络(GAN)[23]的革命性概念在图像到图像转换任务上取得了巨大成功,例如图像超分辨率[24]、[25]、图像修复[26]–[29]、 图像风格转移[30]-[33]和像素级图像分割[34]、[35]。
受这些概念的启发,最近的方法探索了通过自动学习映射函数将图像从高动态范围转换为对应的低动态范围或反之亦然的生成模型。
特别是,拉纳等人。 [7] 通过探索 pix2pixHD [32] 架构的生成器和鉴别器网络的单尺度和多尺度变体,提出了 DeepTMO 网络。 尽管 DeepTMO 是无参数的并且比大多数传统方法取得了更好的结果,但色调映射图像通常表现出较差的对比度以及某些场景的模糊斑块。我们认为这些伪影可能是由于 a) 生成器架构的结构造成的 模型,以及 b) 训练模型的数据规模有限。 李等人。 [36]还提出使用深度递归GAN模型来执行从LDR到HDR域的逆映射。
所提出的 TMO-Net 通过引入注意力引导生成器架构来生成视觉上令人愉悦的色调映射图像,从而解决了 DeepTMO 的缺点。 生成器损失函数中还引入了梯度分布损失,以改善色调映射图像的视觉感知。 第 3 节提供了模型架构和损失的更详细解释。
对大规模 LVZ-HDR 进行性能基准测试和比较分析,以正确评估所提出的 TMO-Net 与传统和最新神经网络 TMO 的泛化能力和视觉输出。
III. PROPOSED APPROACH
该方法的主旨是将 HDR 色调映射视为低光图像增强问题。 将 16 位 HDR 图像视为曝光不足且噪声极低的图像。 利用深度卷积神经网络的巨大成功,我们可以设计一个具有适当目标函数的适当神经网络,并训练它学习复杂的动态数学映射函数,以从曝光不足的图像生成具有全局和局部对比度一致性的曝光良好的图像 图像输入。 这样的训练模型可以用作动态色调映射算子。
所提出的 TMO-Net 使用生成对抗网络方法,尝试自动学习两个不同域中图像之间的映射函数。
输入是一个 8 位 RGB 图像,通过将 2.2 的 gamma 应用于 HDR 图像并对结果进行归一化以利用完整的 0-255 范围而创建。 由于 HDR 图像通常具有少量非常明亮的像素,因此这会导致图像在屏幕上显示时显得曝光不足。 TMO-Net 尝试将此图像映射为曝光良好的图像,该图像也以 8 位和标准 sRGB gamma 编码保存。
学习到的复杂映射函数是无参数的,并且可以很好且一致地泛化。 TMO-Net 还试图解决无参数和基于 GAN 的模型 DeepTMO 的挑战,该模型表现出模糊的补丁、全局对比度不一致、光晕伪影和颜色拖尾,这主要是由于其生成器网络架构和目标函数的性质造成的。 与 DeepTMO 采用 Pix2PixHD 模型的多尺度生成器和多尺度鉴别器网络架构不同,TMO-Net 仅由相互对立的单个生成器网络 G 和单个鉴别器网络 D 组成。 图 4 显示了所提出的 TMO-Net 的模型架构。 判别器 D 基于 PatchGAN,这是 Isola 等人提出的马尔可夫判别器模型。 [37]。 通过在我们的生成器架构中引入注意力模块和级联块,并将梯度分布损失纳入目标函数,TMO-Net 能够克服 DeepTMO 的上述局限性。
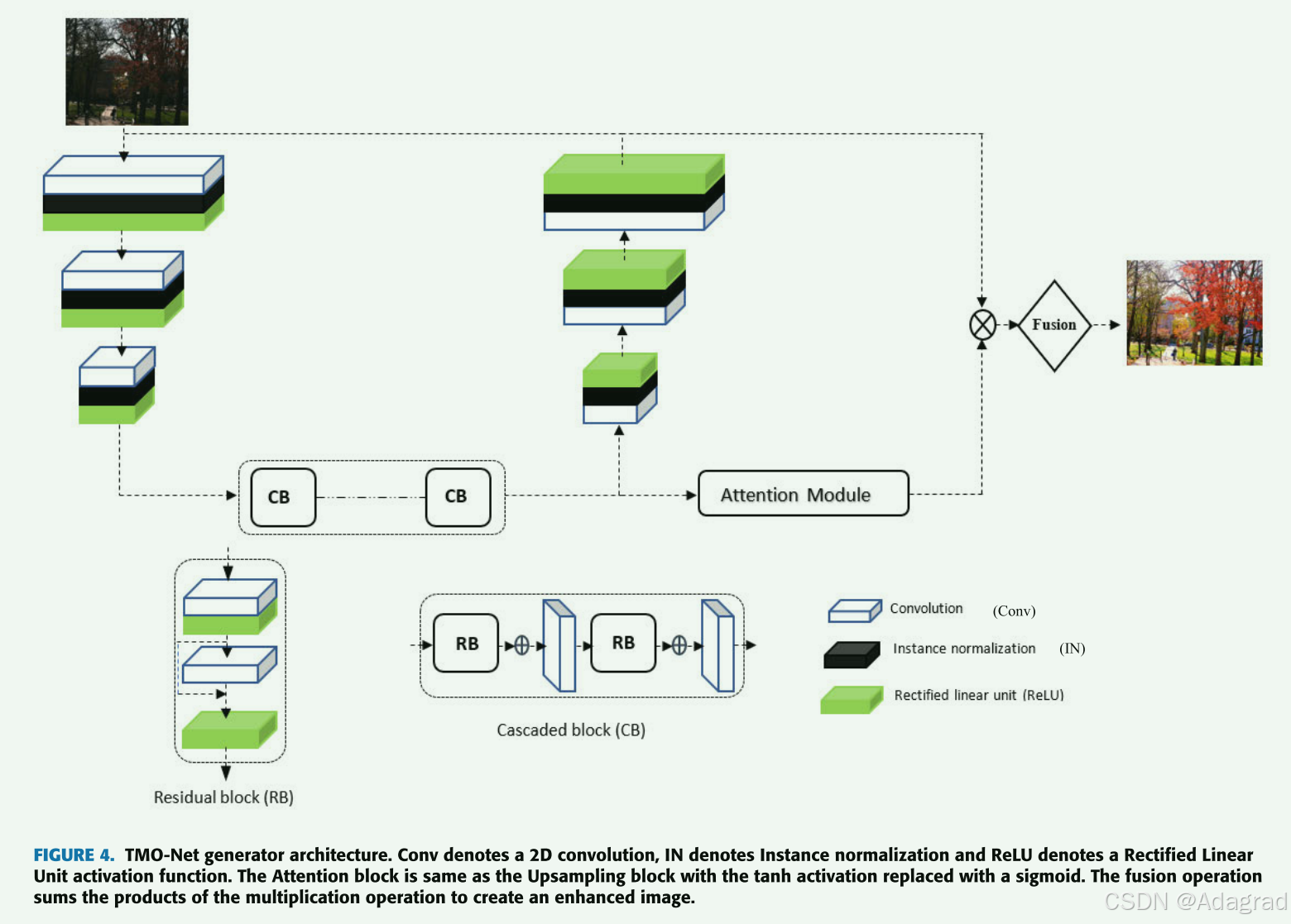
A. NETWORK ARCHITECTURE
TMO-Net 的灵感来自 pix2pixHD [33],我们从中导出了基本生成器架构模型; 我们采用了 PatchGAN [37] 的判别器网络; FFA-Net [38] 启发了我们生成器架构中的注意力引导模块; 和级联残差密集网络[39]、[40],其中我们得出了生成器架构中使用的残差密集块的直觉。 如图4所示,端到端的TMO-Net是一个类似U-Net[41]的架构,其中一组下采样块作为编码器网络,后面是一系列级联的密集块,一组上采样块 块,最后是融合层。 网络的输入大小设置为 256 × 256。每个级联密集块(CB)由一系列具有跳跃连接和串联层的残差块构成。 最后级联密集块的输出同时馈送到解码器网络(上采样块)和注意力引导模块,其输出在最后一层融合以生成色调映射输出图像。 注意力模块被分解为通道注意力和像素注意力块。 其目的是协助生成器调节光源,防止颜色拖尾,同时确保生成图像的全局和局部对比度以及颜色一致性。 引导注意力模块还有助于消除图像合成过程中曝光不足和曝光过度的问题。
下采样和上采样块彼此镜像,但以相反的方向增长。 生成器网络由 3 个下采样块和 3 个上采样块组成,每个块由一个 2D 卷积层与一个实例归一化层以及一个修正线性单元 (ReLU) 激活层组成。
每个级联密集块(CB)由 2 个残差块和 2 个输出卷积层组成。 残差块又由 2 个滤波器大小为 3 × 3 的卷积层组成,每个卷积层后面都有带有跳跃连接的 ReLU 激活层。 级联密集块旨在确保生成器映射函数学习图像中最精细的纹理和结构细节,然后将它们传输到上采样块,同时还允许正确传输在早期层中学习的更多全局特征。 解码器网络中使用双线性采样,结合实例归一化和 ReLU 激活,以确保消除潜在的棋盘伪影 [31]。
采用的判别器是 PatchGAN 网络,在最近的文献中被广泛采用,因为它能够基于 NxN 个补丁而不是整个图像进行判别。 这种判别器网络架构可以正确识别图像中的局部纹理和结构信息,并迫使判别器学习如何生成更加全局和局部一致的图像。 它由 5 个卷积层组成,用于将 6×256×256 输入(包括真实图像和生成图像对)转换为 1×35×35 输出,表示鉴别器的平均有效性响应。
B. TMO-NETGENERATOR OBJECTIVE FUNCTION
所提出的TMO-Net的目标函数是由四个独立损失的累积得出的,即:对抗性损失、感知损失、特征匹配损失和梯度剖面损失; 每个解决具体问题并共同指导学习映射功能的效率。
a) The Adversarial loss
被表述为生成器和鉴别器之间相互对抗的最小最大游戏,其中生成器试图最小化损失,而鉴别器试图最大化损失。 生成器 G 尝试学习前向映射函数 G : X → Y 以将高动态范围域 X 中的图像转换为低动态范围域 Y,并且必须成功欺骗学习区分生成的 LDR 图像和原始 LDR 图像的鉴别器 图像。 LGAN 损失由 (1) [37] 定义:
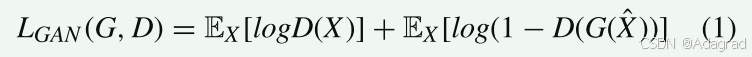
其中 X 和 X^ 表示输入 HDR 图像和相应的 LDR 地面实况,而 G(^X) 表示生成器 G 的输出。
b) The perceptual loss
已被发现有助于指导生成器正确评估生成的图像与目标域中的图像之间的感知特征差异[42]。 因此,将 VGG 损失合并到生成器的目标函数中将有助于生成器在训练期间使用两个图像之间的像素距离来评估合成的 LDR 图像和相应的地面实况 LDR 图像之间的高级感知和语义差异。 为了获得最佳性能并有效影响训练,重新使用了 VGG19 网络的预训练特征。 感知损失定义为[42]:
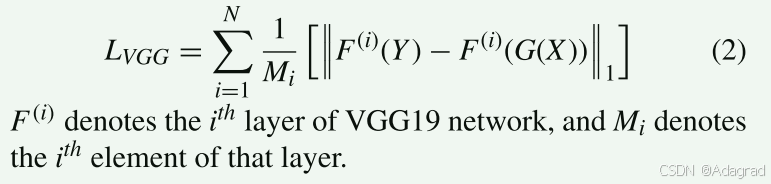
c) The Feature matching loss
对于稳定训练至关重要,同时指导生成器在多个尺度上生成自然合理的统计信息。 这种损失与鉴别器结合在一起,有助于匹配真实图像和合成图像之间的中间特征图。 特征匹配损失定义为[43]:
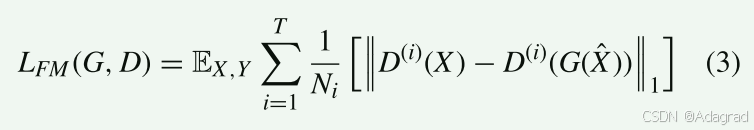
其中T为总层数,Ni为每层元素的数量,D(i)为鉴别器的第i层特征提取器。
d) Gradient profile loss
进一步引入来帮助测量合成LDR图像和地面真实LDR图像之间的边缘信息之间的差异[44],并给出为:

因此,TMO-Net 的总体目标函数由以下等式定义:
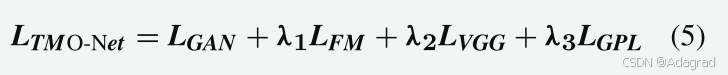
其中,独特权重 λ1 = 10.0、λ2 = 1.0 和 λ3 = 0.8 用于控制个体损失对总体目标的相对重要性或贡献。 Adam 优化器的初始学习率为 0.0002,用于优化生成器和判别器。
深度神经网络解决问题的方法的缺点是它们是数据密集型方法,需要数千个图像样本和等效的地面实况。 这意味着,要正确训练基于 GAN 的模型以对输入图像执行自动色调映射操作(正如我们在本文中试图实现的那样),需要收集包含数千张 HDR 图像的数据集以及相应的地面真实色调 映射的图像。 此类数据归一化配对 HDR/LDR 数据集目前不可用。 为了缓解这一挑战,所提出的 TMO-Net 在低光图像数据集上进行直观的端到端训练。 这里的见解是,此类低光数据集包含曝光不足的图像,其特征模拟了在 LDR 设备上查看时被视为曝光不足的 HDR 图像的分布。 这里的优点是有几个这样的数据集,其中包含数千张图像以及相应的曝光良好的图像对,以及各种各样的曝光、场景和照明。 本质上,我们结合了低光数据集1,该数据集包含多达 2274 个低光图像和相应的 2274 个增强图像对; 来自 Dark Face 数据集的 789 张图像 [45]; 来自 LOL 数据集的 485 张图像; 和 1000 张图像分别来自[46]。 这使得我们的训练集非常多样化。
我们最终训练目标的制定来自于广泛的计算实验和超参数搜索。我们在对所提出的网络架构进行多次更改的过程中尝试了损失函数中组件的几种组合,发现最终的目标函数产生了最理想的输出。
由于整体训练目标函数明显复杂,因此进行了消融研究以验证各个组成部分的重要性。 图 5 显示了样本图像输入和来自使用所提出的目标函数的变化进行训练的同一网络的相应输出。 从图像中提取局部斑块并放大以进行进一步的比较分析。 我们放大每个输出图像上相应位置的三个样本块,并进行颜色编码。 从图块 (d)、(e)、(f) 上可以看出,去除 SPL 损失分量会导致输出缺乏清晰度和全局对比度一致性。 消除 VGG 损失会进一步加剧这个问题,因为模糊斑块变得更加明显和不自然。 这些伪影可以在图像块 (g)、(h)、(i) 中可视化。 通过将图像块 (j)、(k) 和 (l) 与图像块 (a)、(b) 和 (c) 进行比较,可以更好地可视化特征匹配损失的重要性。 特征匹配损失有助于在重建过程中保留原始场景的内在和更精细的细节,从而产生更好的色调。 将 TMO-Net 输出图像的补丁 (a)、(b) 和 (c) 与具有不同损失函数组件的同一网络输出的相应补丁进行比较,显示每个组件在最终训练目标中的相关性。
IV. LVZ-HDR BENCHMARK DATASET AND EVALUATION METRICS
A. LVZ-HDR BENCHMARK DATASET
创建了一个名为 LVZ-HDR 数据集的新数据集。 所提出的数据集中的每个 HDR 图像都是通过使用 Photoshop HDR 工具融合在多个曝光支架(−2EV、−1EV、0EV、+1EV、+2EV)下拍摄的同一场景的 5 张 LDR 图像而形成的。 该软件还提供方便的功能,帮助消除成像融合问题,例如未对准、噪声和重影。 这些图像是使用奥林巴斯 E-P1 相机拍摄的。 LVZ-HDR 基准数据集由 456 张高动态范围图像组成,这些图像取自不同的州、城市、一天中的不同时间,最重要的是涵盖了广泛的场景。 LVZ 数据集中的图像分为四大场景类别:室内(71 张图像)、自然(173 张图像)、夜间(80 张图像)和河边日落(133 张图像)。 该数据集可在 Kaggle 上下载,2 应提供用于教育和研究目的的免费许可证。 用于创建每个 HDR 图像的原始多重曝光 LDR 图像也可根据要求提供。 图 6 显示了来自所提出的大规模 LVZ-HDR 数据集的多样化样本 HDR 图像。
所提出的数据集致力于解决缺乏大规模 HDR 测试集的问题,以正确评估色调映射算子的优点和性能。 迄今为止,已发表的色调映射研究工作仅限于对少量图像进行评估,且场景和视觉内容有限。 传统色调映射出版物中呈现的结果通常是选择最佳输出图像或由过度的超参数调整产生的。 因此,很难确定算子在更广泛的场景中的普遍性。 我们在 LVZ-HDR 数据集上对 19 个色调映射算子的性能进行了基准测试,包括 17 个传统的最先进的 TMO,以及 2 个基于深度学习和无参数的 TMO,其中提出的 TMO-Net 和 DeepTMO 对方。
B. EVALUATION METRICS
人们提出了两种广泛接受的评估指标TMQI [47]和FSITM [48]来定量评估色调映射算子的性能。 这些指标用于对 19 个色调映射算子(包括拟议的 TMO-Net)的性能进行基准测试。
TMQI算法结合多尺度结构相似度指数和强度统计来衡量三个主要分数,包括:a)结构保真度分数(S-score),b)统计自然度分数(N-score),最后c) TMQI 分数(Q 分数)。
局部 HDR 和 LDR 块 x 和 y 之间的结构保真度测量分别定义为:
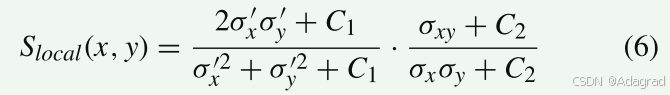
其中 σx 和 σy 表示局部标准差,σxy 表示任何相应 x 和 y 块之间的局部互相关,C1 和 C2 表示稳定常数。 结合不同尺度的局部斑块的结构保真度,得到整体结构保真度如下:


请注意,所有 S、N 和 Q 分数均在 0 到 1 的范围内,分数越高,视觉图像质量越好。 (6)、(7)、(8) 和 (9) 中数学方程的更多细节和证明可以在原始 TMQI 论文 [17] 中找到。 TMQI 的 MATLAB 代码可在此处找到3
另一方面,色调映射图像的特征相似性指数 (FSITM) 指标利用图像中嵌入的局部相位信息,通过比较原始 HDR 和输出 LDR 色调之间的局部加权平均相位角图来计算 Q 分数 映射图像[48]。 可在此处找到可用于 FSITM 的 MATLAB 代码。4
V. EXPERIMENTAL RESULTS AND BENCHMARKING
在本节中,讨论了所选的最先进的色调映射算子在所提出的 LVZ-HDR 数据集上的性能,并比较了它们的视觉输出。 还对各个场景类别进行性能评估,并根据总体基准测试结果对 TMO 进行排名。
对第 2 节中讨论的所有色调映射类别中选择的 19 个 TMO 的性能进行了评估,包括全局、局部、基于分段、基于梯度/频率和基于深度学习的算子。
基准TMO包括:Drago TMO [13]、Durand TMO [17]、Exponential TMO、5 Kim Kautz Consistant TMO [15]、Krawczyk TMO [21]、Lischinski TMO [1]、Logarithmic TMO、Mertens TMO [9]、 归一化 TMO7、Pattanaik TMO [14]、Raman TMO [6]、Reinhard Devlin TMO [3]、Reinhard TMO [16]、Schlick TMO [2]、Tumblin TMO [4]、Ward Global TMO 和 WardHistAdj TMO、DeepTMO、 和 TMO 网络。 所有传统 TMO 的 MATLAB 代码均可从 HDR 工具箱 GitHub 存储库中获取。6
图 7 显示了每个选定的 TMO 在来自 LVZ-HDR 基准数据集中不同类别的一些测试图像上的输出。 所有 19 个 TMO 的 LVZ-HDR 基准数据集中所有 456 张图像的结果均可在 Kaggle 上进行可视化和下载7。
图 7 显示,所提出的 TMO-Net 在质量上优于所有其他方法。 TMO-Net 生成更具视觉吸引力、更自然的图像,具有高清演色性、高对比度和清晰度。
TMO-Net不仅消除了传统方法的参数敏感性,而且还解决了诸如颜色拖尾、低对比度、模糊、光晕伪影、颜色错误表示和缺乏清晰度等关键问题,其中一些问题即使在 DeepTMO 中也很明显,参数 - 免费和深度学习对应。 这些定性结果通过专用评估指标(例如 TMQI、FSTIM、NIQE 和 UIQM [49])进一步得到定量证实,如表 1 所示。
A. BENCHMARKING WITH TMQI
如前所述,TMQI 测量 3 个有用的分数:a) 测量结构保真度指数的 S 分数,b) 测量图像自然真实度的 N 分数,以及 c) 线性的 Q 分数 S 和 N 分数的组合,代表 TMQI 指数。 TMQI 也是色调映射算法最常用的评估指标。 算子的性能根据 LVZ-HDR 数据集上的平均 TMQI 得分进行排名。
图 8 中的基准图显示了所提出的 TMO-Net 排名以及基于 TMQI 平均分数的最佳性能色调映射运算符。 该排名表明,排名前 2 的算法是无参数算子 TMO-Net 和 DeepTMO,这证实了这 2 个基于深度学习的算子能够很好地自动适应不同的场景和更广泛的 HDR 内容。 观察平均自然度分数与相应的 TMQI-Q 分数之间的差异同样重要。所提出的 TMO-Net 的相应 Q 分数和自然度分数非常高,并且在数值上非常接近,这表明 TMO-Net 能够在所有场景中保持高色调映射一致性。
请注意,为了进行充分的比较,DeepTMO 模型也在与 TMO-Net 相同的训练集上进行了重新训练,并进行了相同数量的 epoch。
这也表明 TMO-Net 不仅生成最具视觉吸引力的图像,而且还生成最自然的图像渲染,几乎没有伪影。
图 9 还表明,与在某些场景类别上表现优于其他场景的传统色调映射算子相反,TMO-Net 在基准数据集的不同类别中保持一致的性能,这意味着所提出的模型可以很好地推广到更广泛的范围 HDR 视觉内容和场景。
B. TMO-NET VS DeepTMO
在本节中,TMO-Net 的性能与另一个基于深度学习的无参数色调映射运算符 DeepTMO 进行了比较。
图 10 比较了 TMO-Net 和 DeepTMO 算子输出的样本图像。 放大摘录显示了 DeepTMO 渲染中存在的几个伪影。 TMO-Net 渲染的图像具有更高的清晰度、一致的全局和局部颜色和对比度以及更好的清晰度。 另一方面,DeepTMO 表现出局部模糊、局部色彩拖尾,并且缺乏清晰度。
C. USER SURVEY
为了进一步评估和验证所提出的 TMO-Net 与现有最先进的 TMO 的定性性能,进行了在线用户调查。 为了使调查最有效且不那么拥挤,我们选择了本文中介绍的 12 张 HDR 图像,每个场景类别各 3 张。 根据图 8 中的 TMQI 排名,选择了前 7 个运营商相应的色调映射输出进行调查。 因此,调查分为 12 组呈现给用户,每组显示单独的输入 HDR 图像,以及所选 7 个 TMO 中每一个的相应色调映射输出。 我们要求用户根据他们的感受为每组选择 2 张图像:i) 最具视觉吸引力的图像,ii) 基于输入 HDR 图像增强程度最高的输出图像,以及 iii) 其中最自然的图像 7 提供了 TMO 输出。
共有 91 人参与了调查,10 其中绝大多数是没有图像处理背景的大学生,其余的是图像处理专家或研究生。
表 2 中的调查结果显示,对于向 91 位用户呈现的 12 张测试图像中的每一张,平均至少有 61 位用户根据上述选择标准选择 TMO-Net 输出图像作为最佳色调映射算子。 这证实了 TMO-Net 在质量上优于现有 TMO 的说法。 该调查同样支持图 8 中基于各种 TMO 定量表现的基准测试结果。 根据平均调查指数得分对 TMO 进行的初步排名也显示 TMO-Net 是表现最佳的运营商。 请注意,Durand 和 DeepTMO 运营商在调查排名中分别排名第二和第三,而在 TMQI 排名中排名第三和第二。 然而,可以肯定地说,鉴于 DeepTMO、Durand 和 KimKautz 的平均 TMQI 分数彼此非常接近,调查排名仍在图 8 所示的 TMQI 基准测试的误差范围内。因此,这 3 个算子的输出非常相似,并且在选择 TMO-Net 作为最佳输出后,同样有可能(33% 的机会)被选为每组的第二最佳图像。
VI. CONCLUSION
在本文中,引入了大规模 HDR 数据集(LVZ-HDR)作为标准基准数据集,用于评估当前和未来色调映射算子的性能。 此外,提出了一种基于深度学习的高效无参数色调映射算子 TMO-Net,可以从输入的高动态范围图像中有效地合成色彩丰富且视觉上令人愉悦的低动态范围图像。 TMO-Net 可以很好地泛化并在更广泛的 HDR 视觉内容上产生一致的结果。 第 5 节中提出的定性结果表明,所提出的 TMO-Net 渲染的图像更具视觉吸引力、更自然、具有一致的全局和局部色彩和对比度以及更高的清晰度。 与 DeepTMO 的仔细比较表明,TMO-Net 在质量和数量上都优于 DeepTMO。
实验结果还表明,所提出的 TMONet 在所有场景类别上都优于当前所有最先进的色调映射算子。 TMO-Net 解决了现有色调映射算子的缺点,例如模糊斑块、颜色拖尾、光晕伪影、清晰度不足和色彩渲染不当。 为了进一步证实和验证这种性能排名,使用其他广泛使用的盲评估指标(例如 NIQE 以及 UIQM 的色彩度和清晰度组件)重新评估所选算法的性能。
VII. LIMITATIONS
尽管 TMO-Net 解决了 DeepTMO 和其他传统色调映射算子的大部分挑战和限制,但仍有几个方面需要改进。 最重要的是,TMO-Net 本身并不使用 HDR 图像,因此由于输入的 8 位量化,一些图像质量会丢失,特别是在较暗的区域。 虽然生成器能够对此进行部分补偿,但通过使用 HDR 输入的完整位深度可以获得更好的结果。
生成器架构模型中的注意力模块有时会过度增强图像中的特定区域,这可能会导致某些颜色主导图像的其余部分。 此外,在少数情况下,原始 HDR 图像包含未对准和重影等伪影,而这些伪影在场景曝光融合过程中没有得到正确解决,TMO-Net 似乎会使输出色调映射图像中的此类伪影变得更糟。 其中一些故障模式如图 11 所示。
缓解这些问题的一种方法是充分惩罚生成器架构中的注意力引导模块。 确保融合曝光期间输出 hdr 中的正确对准和去重影同样重要。
基准测试的另一个重要限制是我们使用 TMQI 分数。 TMQI 指标不遵循人类视觉系统,因此表现出一些局限性。 TMQI 有时会给视觉质量较高的图像分配较低的分数,这表明迫切需要开发一种更强大且受人类视觉系统启发的色调映射评估指标。 由于 TMQI 和 FSTIM 指标的局限性,我们还通过使用其他评估指标(包括 NIQE 和受人类视觉系统启发的 UIQM)来验证 TMO-Net 的优点。 这些限制将构成我们未来工作和新研究方向的基础。
颜色过度强调/饱和度也是所提出的 TMO-Net 模型观察到的局限性之一。 尽管 TMO-Net 经过训练可以生成高质量的色调映射图像,这些图像在感知上更令人愉悦,并且在最细微的细节上看起来更自然,但在一些输出图像中可以看出,某些颜色显得饱和。 解决此问题的一种简单方法是应用颜色校正算法,例如 Mantiuk 等人提出的算法。 [50]和[7]建议的,甚至是Schlick [2]提出的更古老的色彩校正算法,对输出图像进行校正。 Mantiuk提出的色彩校正定义为Cout = (Cin/Lin − 1) .s + 1)Lout,其中s控制色彩饱和度。
图 12 显示了在多个颜色饱和度控制值下进行颜色校正之前和之后的示例图像输出。
然而,为了公平和公正的比较分析,我们仅使用所提出模型的原始输出,而没有进一步的颜色校正。 改进 TMO-Net 的一个空间是将这种颜色调整合并到目标函数中,但这可能会导致输出图像中出现新的伪影。

















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









