







从大到小的话我们看它有这么5个层次,最简单的storm是个集群,cluster是个层次,第二个层次就是有比较明确的意义了,就是supervisor,supervisor对应的层级就是一个个的host,就是一个个的node,就是一个机器这个级别的,然后一个机器它又有很多的worker,worker其实就是对应process级别的,就是进程级别的,机器上跑几个进程,规定4个worker,就4个进程,每个worker里面跑着一个个executor,对应着的一个个线程,那接下来一个线程运行着一个或很多个task,一般很多情况下就一个task,当然了,有时候对应多个task,task就是最低级别的object,就是线程操作的就是一个个对象。
并发模型
–整个storm就有这么几个层次,从集群的角度看就是一个机器里面有多少个节点,每个节点上面有多少个进程。
–从topology的角度讲,就是一个topology要运行几个worker,一个worker会运行多少个executor,一个executor上面又会运行一
个或多个task,task就是对应spout或者bolt的对象。

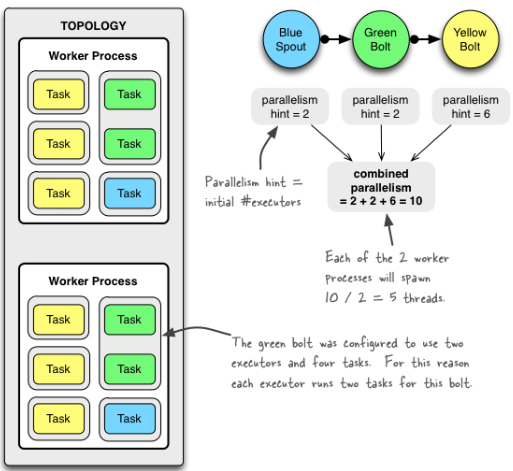
并发度就是executor的数量,这里worker数定了,executor数定了,那task数怎么来定呢?
默认的task数就是并发的数量,当然你可以通过setNumTasks()来设置不同的task数,当然只能是多,不能是少,比如上图这个GreenBolt就是。
总结一下很简单,就是worker一开始设置多少个就是topology里面有多少个,executor并行度那里设置多少个就是多少个,task如果没有设置那就是一个executor对应一个task,如果有写那就是task数就是task设定的数除以executor数来决定。
worker间数据传输
1.executor执行spout.nextTuple()/bolt.execute(),emit tuple放入executor transfer queue
2.executor transfer thread把自己transfer queue里面的tuple放到worker transfer queue
3.worker transfer thread把transfer queue里面的tuple序列化发送到远程的worker
4.worker receiver thread分别从网络收数据,反序列化成tuple放到对应的executor的receive queue
5.executor receive thread从自己的receive queue取出tuple,调用bolt.execute()
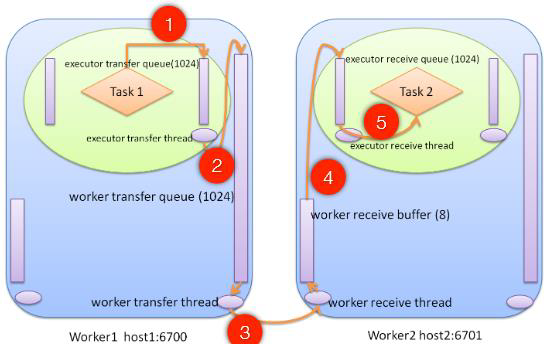
为什么数据传输那么重要,因为topology的spout到bolt,bolt到bolt之间的数据Tuple传输是通过worker来干的!
上面的第三步,worker transfer thread从worker transfer queue里面拿出数据来,然后做简单的判断,然后做序列化,然后通过网络发送到目标task所在的worker里面,它怎么知道这个目标task所在哪个worker呢,答案就是zk,因为我每个worker都会往ZK上写状态信息,状态信息里面就有worker有哪些个executor,有哪些个task,然后通过grouping,那通过grouping算出要发哪个task,那我找出这个task在哪个worker上面,然后worker对应着哪个机器哪个port,那这个时候我就知道往哪个上面发数据了,那发送tuple到Worker了
上面的第四步,它怎么知道数据应该发到worker里面的哪个Task呢,因为一个worker可能会有多个executor和多个task,这个就是在序列化数据里面了,之前序列化有两个东西,一个东西就是task-id,一个东西就是tuple本身的数据。
如果worker内部不同task之间通信,就不需要走网络这个流程了,这里实际上是一个优化,worker transfer thread发现目标task本地的另外一个task,那这个时候我就之间把数据放到executor的receive queue里面去,这个时候就完成了,避免了不必要的网络传输,所以极端的情况下,如果你topology只有一个worker的情况呢,那它就没有什么网络传输,全部是在内存的队列里面干来干去的。
无状态
无状态的,nimbus/supervisor/worker状态都存在ZK里面,少数worker信息存在本地文件系统里面,还有nimbus把程序的JAR包也存在本地系统里面,它的好处是甚至nimbus挂掉之后,都可以快速的恢复,恢复就是知道重新起一个然后去ZK里面读取相应的数据,因为这样所以storm非常的稳定,非常的健壮,其实通过zk做了一个很好的解耦,任何模块挂了之后呢都还可以进行很好的工作,也就是譬如说supervisor挂了,worker一样可以照常工作,因为supervisor和worker之间没有直接的关系,都是通过zookeeper或本地文件进行状态的传输的
单中心
storm也是master/slave的架构,master是nimbus,slave是supervisor,单中心的好处是,使得整个topology的调度变得非常的简单,因为只有一个中心的话,就是决定都有一个人来决定,不会出现仲裁的情况
master这种也会有单中心的问题,就是单点失效的问题,当然这个问题也不是很大,当没有新的topology发送上来的时候,运行在集群里面的topology不会有什么影响,当然极端的情况就是,这时候某个supervisor机器挂掉了,没有nimbus了就不会做重新的调度,这样还是会有一定的影响。
另外一个单点的问题,就是单点性能的问题,因为现在topology的jar包呢还是通过nimbus来分发的,客户端提交还是先提交到nimbus,然后各个supervisor去nimbus上面去下载,当文件比较大的时候,supervisor机器比较多的时候呢,nimbus还是会成为瓶颈,网卡很快会被打满,当然为了解决这个问题呢,storm也有一些办法,比如说把文件的分发变成P2P的。
隔离性好
因为真正干活的是executor和worker,nimbus/supervisor就起到一个控制topology流程的作用,数据流程都在executor和worker里面来做,所有的数据传输都是在worker之间完成的,不需要借助于nimbus和supervisor,特别是不需要借助于supervisor,这点设计上就是非常成功的,在hadoop中,TaskTracker存在,所有的shuffle都经过TaskTracker,所以,所有的TaskTracker进程一旦挂了,它上面的map是要重新去执行的,因为没有人做数据传输的服务,Storm就不一样,所有的数据传输都在worker间,即使supervisor挂了,数据传输在worker之间,supervisor挂了之后,一点不会受影响,更不可思议的是,nimbus/supervisor全部挂掉了话,worker还能正常工作,这个在hadoop中是不可想象的,所有的master/slave都挂了,task还能正常运行吗???
Storm的ack机制
–Tuple树
–在Storm的一个Topology中,Spout通过SpoutOutputCollector的emit()方法发射一个tuple(源)即消息。而后经过在该Topology中定义的多个Bolt处理时,可能会产生一个或多个新的Tuple。源Tuple和新产生的Tuple便构成了一个Tuple树。当整棵树被处理完成,才算一个Tuple被完全处理,其中任何一个节点的Tuple处理失败或超时,则整棵树失败。
–关于消息在storm中的超时默认为30秒,具体参看defaults.yaml中的topology.message.timeout.secs: 30的配置。同时,也可以在定义topology时,通过conf.setMessageTimeoutSecs方法指定超时时间。
–storm所谓的消息可靠性指的是storm保证每个tuple都能被toplology完全处理。而且处理的结果要么成功要么失败。出现失败的原因可能有两种即节点处理失败或者处理超时。
–Storm的Bolt有BasicBolt和RichBolt,在BasicBolt中,BasicOutputCollector在emit数据的时候,会自动和输入的tuple相关联,而在execute方法结束的时候那个输入tuple会被自动ack(有一定的条件)。
–在使用RichBolt时要实现ack,则需要在emit数据的时候,显示指定该数据的源tuple,即collector.emit(oldTuple, newTuple);并且需要在execute执行成功后调用源tuple的ack进行ack。(手动ACKthis._collector.ack(input))
–如果可靠性对你来说不是那么重要—你不太在意在一些失败的情况下损失一些数据,那么你可以通过不跟踪这些tuple树来获取更好的性能
有三种方法可以去掉可靠性:
–第一是把配置中Config.TOPOLOGY_ACKERS
conf.put(Config.TOPOLOGY_ACKER_EXECUTORS, 0);设置成0. 在这种情况下,storm会在spout发射一个tuple之后马上调用spout的ack方法。也就是说这个tuple树不会被跟踪。
–第二个方法是在tuple层面去掉可靠性。你可以在发射tuple的时候不指定 messageid来达到不跟踪某个特定的spout tuple的目的。
–最后一个方法是如果你对于一个tuple树里面的某一部分到底成不成功不是很关心,那么可以在发射这些tuple的时候unanchor它们。这样这些tuple就不在tuple树里面,也就不会被跟踪了。
Acker的跟踪算法是Storm的主要突破之一,对任意大的一个Tuple树,它只需要恒定的20字节就可以进行跟踪。
–Acker跟踪算法的原理:acker对于每个spout-tuple保存一个ack-val的校验值,它的初始值是0,然后每发射一个Tuple或Ack一个Tuple时,这个Tuple的id就要跟这个校验值异或一下,并且把得到的值更新为ack-val的新值。那么假设每个发射出去的Tuple都被ack了,那么最后ack-val的值就一定是0。Acker就根据ack-val是否为0来判断是否完全处理,如果为0则认为已完全处理。















 4725
4725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









