







当时使用sigmoid时,如果确定分类的阈值呢?
(使用sigmoid的多分类或者softmax的2分类,其实2分类的softmax就是sigmoid没区别)
一般我们喜欢使用0.5这个默认的值。但是如果有更好的阈值使得结果更好,那该如何处理呢。。。
可以使用ROC,如下例子所示,排好序的阈值以对应的10个阈值进行划分,得到对应的统计值。
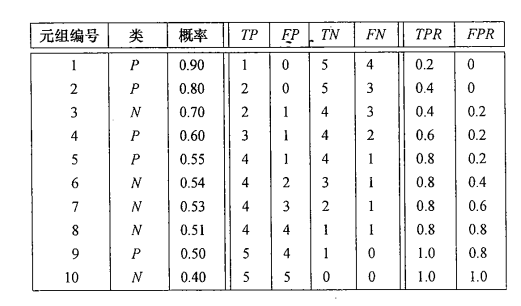
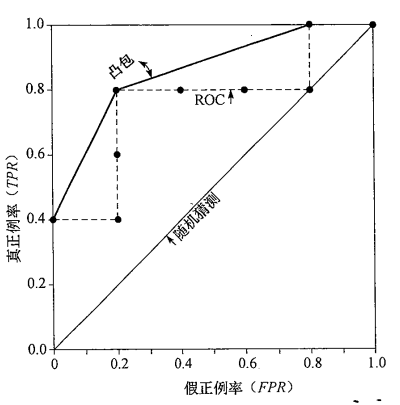
根据你能接受的假阳性率FPR和召回率TPR来确定对应的点位,再根据点位来查找该点位对应的阈值。
有时候不清楚是召回更重要还是精确率更重要,此时该怎么选择分类模型呢?
可以使用F-score。
什么是F1-score
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
![]()
此外还有F2分数和F0.5分数。F1分数认为召回率和精确率同等重要,F2分数认为召回率的重要程度是精确率的2倍即beta取2,而F0.5分数认为召回率的重要程度是精确率的一半即beta取0.5。计算公式为:
![]()
G分数是另一种统一精确率和的召回率系统性能评估标准,G分数被定义为召回率和精确率的几何平均数。
![]()
计算过程
1. 首先定义以下几个概念:
TP(True Positive):预测答案正确
FP(False Positive):错将其他类预测为本类
FN(False Negative):本类标签预测为其他类标
2. 通过第一步的统计值计算每个类别下的precision和recall
精准度 / 查准率(precision):指被分类器判定正例中的正样本的比重
召回率 / 查全率 (recall):指的是被预测为正例的占总的正例的比重
另外,介绍一下常用的准确率(accuracy)的概念,代表分类器对整个样本判断正确的比重。
3. 通过第二步计算结果计算每个类别下的f1-score,计算方式如下:
4. 通过对第三步求得的各个类别下的F1-score求均值,得到最后的评测结果,计算方式如下:
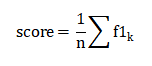
参考
机器学习中的F1-score_Yucen的博客-CSDN博客_f1 score















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









