







摘要
已知的CNN网络需要固定的输入图像大小,本文提出SPP-Net (Spatial Pyramid Pooling)消除了上述需要。SPP-Net能够生成固定长度的表达,不依赖于输入图像的尺寸和方向率。
使用SPP-Net只需要对整个图像计算一次特征图。避免了(R-CNN)重复计算。
在测试的时候,运算速度是R-CNN的24~64倍。
CNN v.s. SPP net

当应用CNN到任意尺寸的图像的时候,通常对图像作crop或者warp,但是crop不能保证包含整个图像,warp会改变图像的外观。识别精度会受到影响。而且,通常的CNN方法需要固定的输入尺寸,这个尺寸对某些目标也不适合。
事实上,卷积层不需要固定尺度,只有全连接层需要固定的尺寸。
SPP net方法在卷积层之后 增加了一个SPP,不再需要固定的输入尺寸。
Deep Networks with Spatial Pyramid Pooling
1. The Spatial Pyramid Pooling Layer
卷积层接受任意尺寸的图像,因此输出的尺寸是变化的。但是,全连接层只接受固定尺寸的输入。为了解决这个问题,引入了Spatial Pyramid Pooling。
Spatial Pyramid Pooling在局部空间作pooling,保留了空间信息。具体一点,局部的空间被划分为固定的bin,在每个bin里面提取固定维的特征,从而保证 Spatial Pyramid Pooling对每个局部片都产生同样维度的特征。
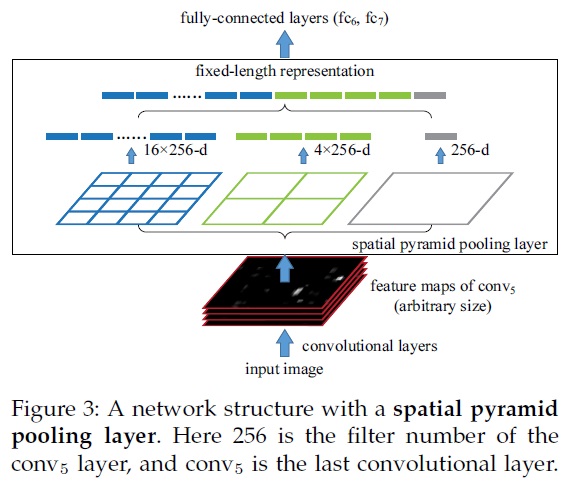
在上面的图中,conv5之后的pooling层 被SPP层代替。每个空间bin,作者取最大值作为响应值。
2.Training the Network
2.1 单尺度训练
与前人的工作一样,作者首先考虑一个网络有固定尺寸的输入。对于一个已知尺寸的图像,可以提前计算bin size。

2.2 多尺度训练
SPPnet 期望应用到任何尺度的图像。因此作者采用了2个尺度(180*180,240*240)训练。(请参考原文)
但是检测的时候,直接应用SPP net 到任何尺寸的图像。
- SPP net for Object Detection
a) 首先,使用selective search 得到2000个候选区域。
b) 然后将图像s = min(w,h), 计算conv5的特征图。
c) 在每个候选区域内,提取4级Spatial Pyramid,总共50个bin。256 feature map * 50 = 12800维。
d) 12800维特征送给全连接层。
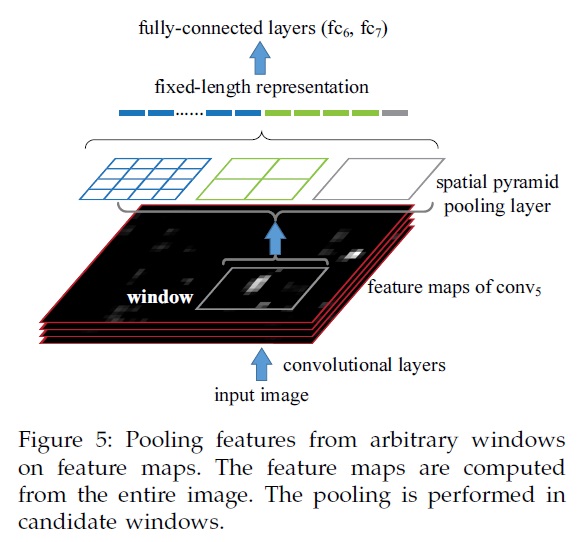
其他部分与R-CNN基本一致,请参考原文和R-CNN
end















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









