










本专栏根据斯坦福大学2017年公开课CS231n的视频教程整理学习资料,做学习笔记。
首先简单介绍CS231n,又称Convolutional Neural Networks for Visual Recognition。
计算机视觉在我们的社会中无处不在,广泛应用于搜索、图像理解、应用程序、测绘、医药、无人驾驶飞机和自动驾驶汽车等领域。许多应用的核心是视觉识别任务,如图像分类,定位和检测。神经网络(又名“深度学习”)方法的最新发展极大地提高了这些最先进的视觉识别系统的性能。本课程深入探讨深度学习架构的细节,重点是学习端到端模型,尤其是在图像分类方向。
在CS231n课程中,学生将学习实施、训练和调试自己的神经网络,并获得对计算机视觉前沿研究的详细了解。最后的任务将涉及培训一个数百万参数卷积神经网络,并将其应用于最大的图像分类数据集(ImageNet)。我们将着重教授如何设置图像识别问题、学习算法(例如反向传播)、用于训练和微调网络的实际工程技巧,以及引导学生完成实践作业和最终课程项目。本课程的大部分背景和材料都将从中提炼出来实际的工程技巧,训练和微调网络,引导学生完成实践任务和最终的课程项目。
主讲教师:Fei-Fei Li
(美国斯坦福大学计算机科学系副教授,2015年12月1日,入选2015年“全球百大思想者”)
推荐观看李飞飞的TED讲座:如何教计算机理解图片。视频内附有多种字幕,包括中英文。
https://www.ted.com/talks/fei_fei_li_how_we_re_teaching_computers_to_understand_pictures#t-737258
当前计算机视觉可以识别一些简单的物体,类似于一个三岁大的小孩,能辩认出简单事物。如果把孩子的眼睛看作是生物照相机,那他们每200毫秒就拍一张照。—这是眼球转动一次的平均时间。所以到3岁大的时候,一个孩子已经看过了上亿张的真实世界照片。于是发起了 ImageNet 项目,一个含有1500万张照片的数据库, 涵盖了22000种物品。
目前为止, 我们已经教会计算机“看”对象,或者甚至基于图片,告诉我们一个简单的故事。但图片里还有更多信息是计算机未能理解的。将一个孩子从出生培养到3岁是很辛苦的。而真正的挑战是从3岁到13岁的过程中, 而且远远不止于此。
最终,我们希望能教会机器像我们一样看见事物:识别物品、辨别不同的人、 推断物体的立体形状、理解事物的关联、 人的情绪、动作和意图。
这里附上CS231n课程的视频链接:
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
(更新 2018/3/17: 由于期末及寒假,视频看得拖沓,基本2018年3月才又继续,到今天总算是匆匆扫完一遍了。虽然没有继续做笔记,但还是来此打卡,以示学习任务已坚持完成,共勉!)
A brief history
计算机视觉应用于很多邻域,包括生物、物理、心理学、工程、数学、计算机科学。
大约543,000,000年前,生物进化大爆炸,渐渐地,生物开始有了眼睛形成了视觉系统。
1963年,Larry Roberts,提出了Block world,检测简单的块状结构,并实现重建。
1966年,著名的MIT研究“THE SUMMER VISION PROJECT”,目的是”an attempt to use our summer workers effectively in the construction of a significant part of a visual system”。

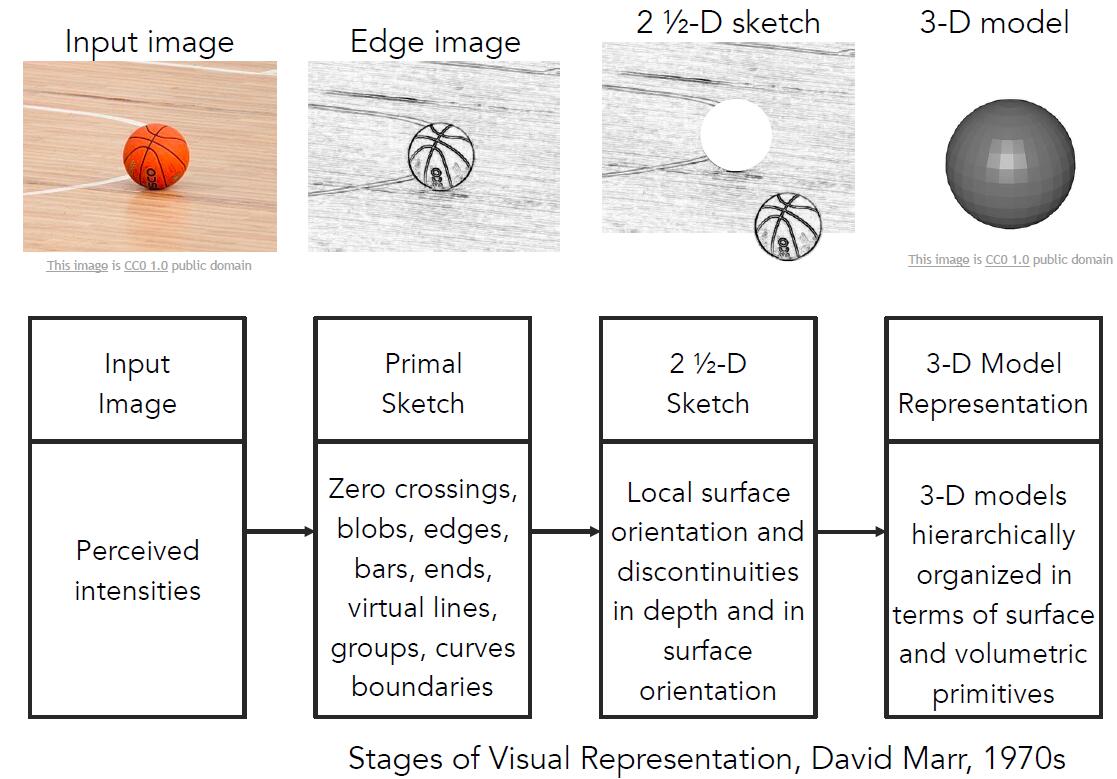
二十世纪七十年代,David Marr 提出了3D模型的重构方法。
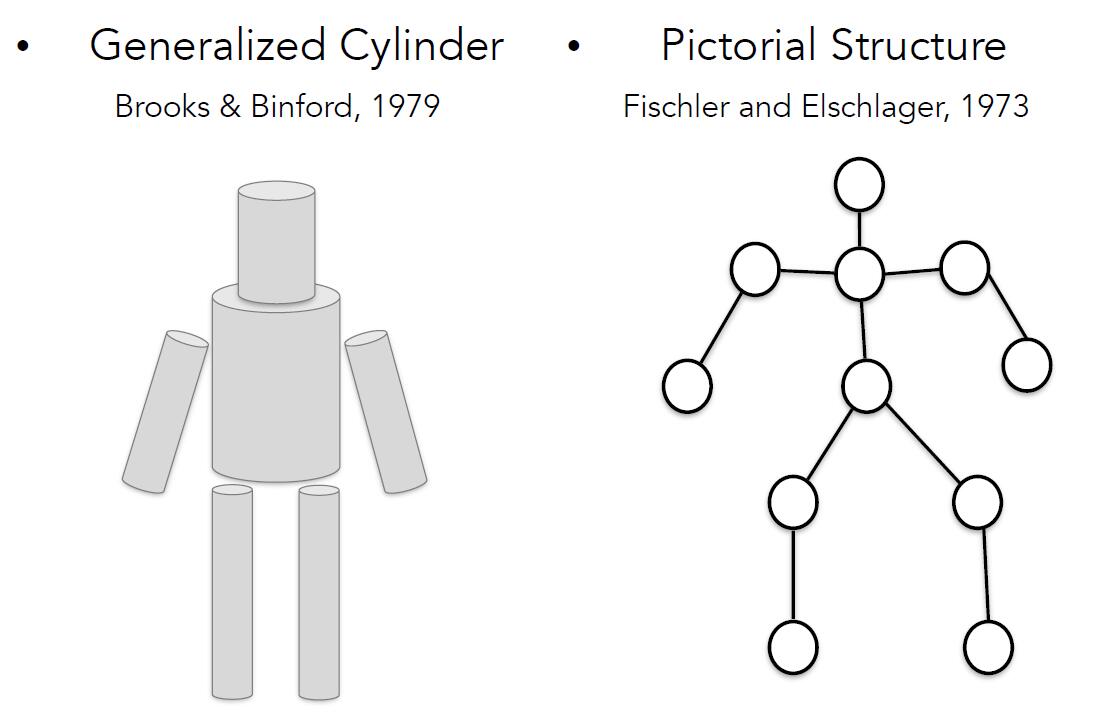
1973年,Fischler and Elschlager提出了 “Pictorial Structure”,1979年,Brooks & Binford提出了“Generalized Cylinder”,旨在通过简单的几何结构绘制真实世界的复杂物体而非纯粹的几何物体。
1987年,David Lowe 提出了对简单结构重构或识别的思想,他通过线条边缘来重构剃须刀的几何模型,
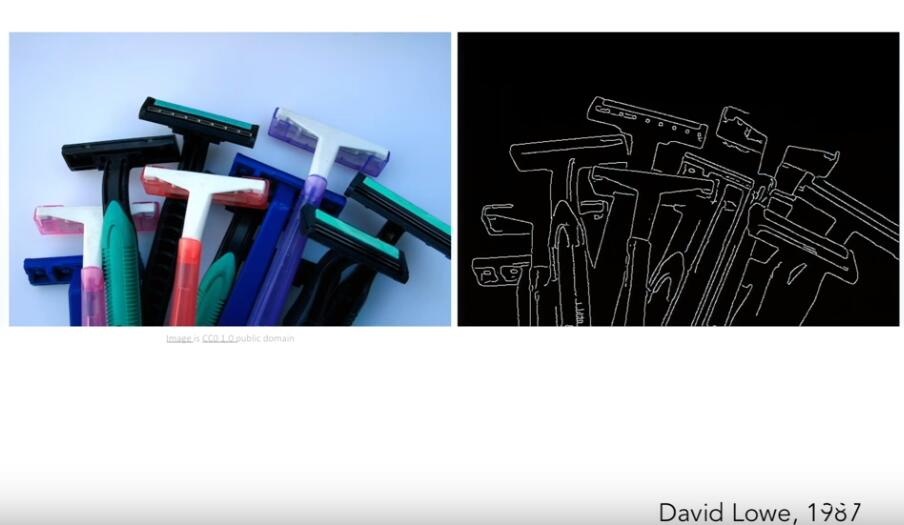
1997年,Shi & Malik 提出了“Normalized Cut”,将图像像素以群组的形式划分为各个有意义的区域,实现图像分割。比如在图一中,在不知道检测事物是人的情况下,将人所在区域的像素从背景中分隔提取出来。

2001年,Face Detection, Viola & Jones提出了“人脸检测”

1999年,David Lowe提出了“SIFT” & Object Recognition。可能因为相机角度、背景、视角、光照、自身变化等问题,相同物体在不同图像中有所差异。为了解决匹配问题,引出了SIFT特征的方法。

2006年,Lazebnik, Schmid & Ponce 提出了“Spatial Pyramid Matching”,通过特征来提供线索,确定是什么场景,比如自然景观、厨房、高速公路等。

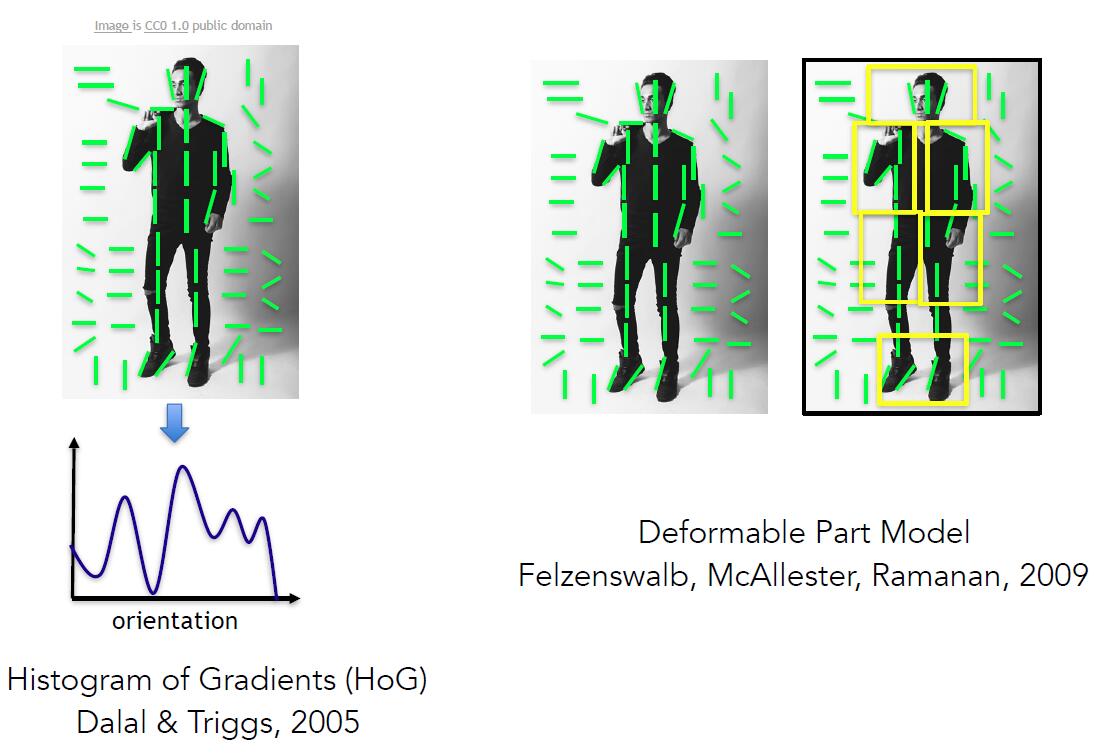
在此之后,陆续提出了HoG(Histogram of Gradients),Deformable Part Model 的识别方法。
CS231n overview
CS231n课程关注的是图像分类,这是视觉识别中最重要的问题之一。有很多的视觉识别问题都与图像分类紧密相关,比如物体检测、看图说话等。

CNN即卷积神经网络Convolutional Neural Networks,它是什么时候提出的呢?早在1998年,CNN就已提出,当时是用于手写字符的自动识别。
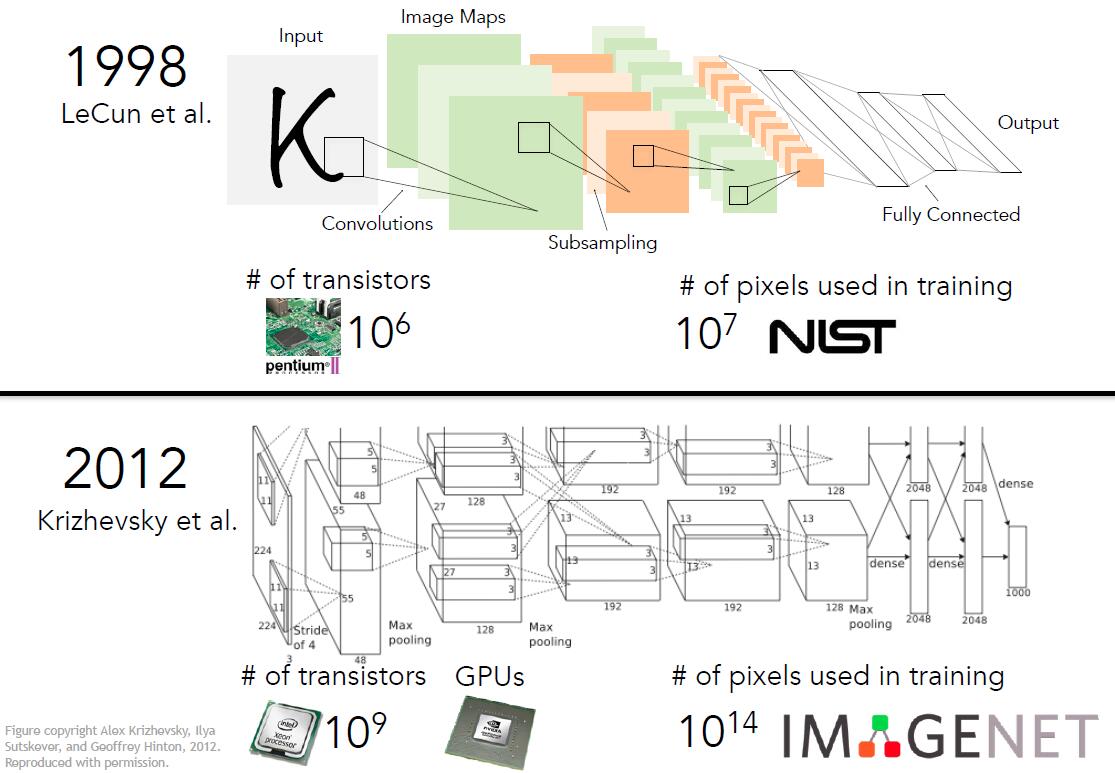
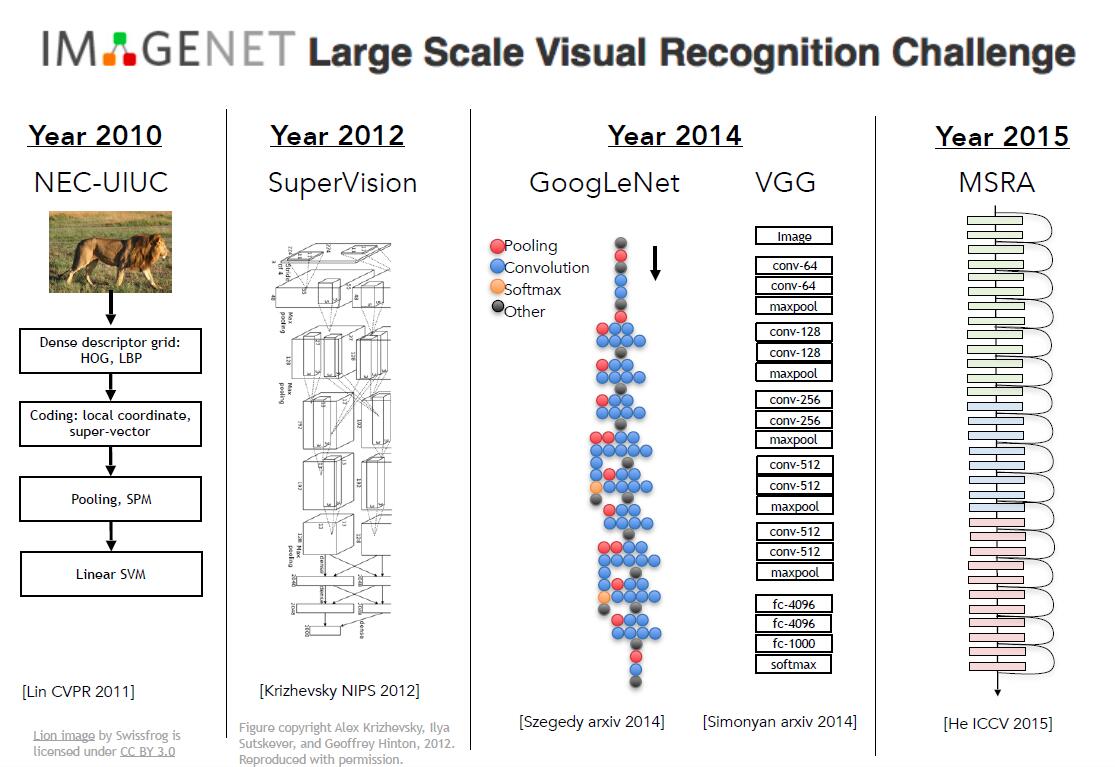
真正让CNN火起来的,是2012年”大规模视觉识别挑战”即“Large Scale Visual Recognition Challenge”,CNN一战成名,一鸣惊人。CNN在ImageNet竞赛中的表现直接奠定了它的重要地位,两个第一,正确率超出第二近10%,确实让人大跌眼镜。
计算机视觉的要求,远不止于目标识别。

我们希望计算机视觉能剖析隐藏在图像中的信息,找出事物间的相互联系,分析人的神情动作等。

正如Fei-Fei Li在TED讲座中所提到的,“一点一点地, 我们正在赋予机器以视力。首先,我们教它们去“看”。然后,它们反过来也帮助我们, 让我们看得更清楚。这是第一次,人类的眼睛不再独自地思考和探索我们的世界。我们将不只是“使用”机器的智力,我们还要以一种从未想象过的方式,与它们“合作”。我所追求的是:赋予计算机视觉智能,并为Leo(Fei-Fei Li儿子)和这个世界, 创造出更美好的未来。















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









