






CodeSYS平台ST语言编程
目录
IEC61131-3国际标准
IEC61131-3标准是为规范PLC的编程⽅法⽽制定的。该标准的⽬的在于简化编程⽅法,减轻⽤户重复学习的负担。基⾦会现场总线所制定的功能块集也符合IEC61131-3标准的基本要求。为适应控制系统向⽹络化、分布式结构⽅向发展的编程需要,IEC正在制定IEC61944标准作为IEC61131-3标准的补充.
包含两⼤类,5种编程语⾔
| 类型 | 详细分类 |
|---|---|
| ⽂本化 | ST语⾔(struct text)结构化⽂本 |
| IL(Instruction LIst)指令表 | |
| 图形化 | LD(Ladder Diagram)梯形图 |
| FBD(Function Block Diagram)功能块图形编程语⾔ | |
| SFC(Sequence Function Chart)顺序功能图 |
CodeSys平台简介
CodeSys是有德国的Smart Software Solution GmbH公司开发的,简称3s公司,⽬前最⾼版本为CodeSys V3.5版本。CoDeSys 包括 PLC 编程、可视化 HMI、安全 PLC、控制器实时核、现场总线及运动控制,是⼀个完整的⾃动化软件。它从架构上基本上可以分为三层,应⽤开发层,通信层和设备层。

CodeSys实时核作⽤
使⽤CodeSys RTE技术,在windows系统中安装PLC CodeSys软件,使得电脑变成⼀台⾼性能的可编程的控制器。
PLC的执⾏过程
执⾏过程包括三个阶段
- 采样输⼊
- 程序执⾏
- 输出刷新

采样输⼊
每⼀次扫描周期的开始,PLC都会检测输⼊设备(按钮,开关,IO模块)的状态,将状态写⼊输⼊映像寄存区。在程序执⾏阶段,PLC会从输⼊映像存储区内读取数据⽤于运算。输⼊的刷新只是存在于扫描开始的阶段,在扫描过程中即使是输出状态的改变,输⼊状态也不会发⽣改变(需要等待下⼀个扫描周期才会改变)。
执⾏阶段
该阶段PLC会从输⼊映像区或输出映像区内读取状态和数据,按照程序逻辑进⾏逻辑判断和运算,再将运算的结果存放到输出映像存储区相应的单元中。该阶段中只有输⼊映像区内的内容保持不变,其他映像存储区内的内容会随着程序运⾏发⽣改变。
输出刷新
PLC将输出映像区的状态和数据传送到输出点上,通过⼀定的⽅式隔离(如继电器)和功率放⼤(如三极管),来驱动外部负载。
其他阶段
完成内部诊断,通信,公共处理及输⼊输出服务等辅助任务。
扫描周期
重复上述的过程,没重复⼀次的时间就称为扫描周期。扫描周期⼀般为ms级别。
输出滞后时间
plc每个扫描周期的信号输出时间与硬件滤波和PLC输出电路相关,继电器型的PLC输出的滞后时间为10ms左右,晶体管的输出滞后时间为⼩于1ms
任务的四种⽅式
CodeSys平台中任务级别被分为32个级别,0位⾼优先级,31为最低优先级——任务级别越⼩优先级越⾼
循环任务 循环任务 循环任务通过固定的循环扫描⽅式,能保证PLC在⼀定循环时间内反复执⾏程序。即使程序的执⾏时间发⽣变化,也可以保持在⼀定的刷新间隔时间。如果程序执⾏的时间在固有的时间内,那么剩余的时间将做等待,如果应⽤中还有较低级别的任务未完成,那么则⽤剩余的等待时间来执⾏任务级别相对较低的任务
惯性滑⾏ 惯性滑⾏ 惯性滑⾏该⽅式也成为⾃由运⾏,程序已开始运⾏任务就会被处理,⼀个运⾏周期之后,任务将在下⼀次循环中重新启动。该⽅式不会收到PLC的扫描周期影响,确保每⼀次执⾏完程序的最后⼀条指令才会进⼊下⼀次扫描周期,否则PLC不会结束程序的扫描周期。程序每⼀次执⾏的时间都不⼀样,所以该⽅式不能保证程序的实时性。
事件 事件 事件该⽅式是由事件区域的变量的上升沿触发,开始执⾏。
状态 状态 状态该⽅式与事件类似,某个变量达到条件时候出发,与事件不通的是,当状态不满⾜时,则停⽌执⾏。
看⻔狗功能
它是控制器中硬件式的计时器,其功能是监控程序执⾏时候的异常和内部时钟发⽣的故障。当程序循环执⾏时死机或者进⼊死循环时候,看⻔狗将会使系统发出重置信号或者使当前程序停⽌执⾏。该功能主要⽤于实时性和安全等级较⾼的场景中。
如果循环的时间过⻓,超过看⻔狗设定的时间,CPU会检测出故障,终⽌程序的执⾏。
编程起步
运算符
运算符优先级
- 如果在表达式中有若⼲个操作符,则操作符会按照约定的优先级顺序执⾏
- 先执⾏优先级⾼的操作符运算,再顺序执⾏优先级低的操作符运算。
- 如果在表达式中具有优先级相同的操作符,则这些操作符按照书写顺序从左⾄右执⾏
| 作符** | 符号 | 说明 | 优先级(⾼到低排序) |
|---|---|---|---|
| ⼩括号 | () | 最⾼ | |
| 函数调⽤ | 函数名() | - | |
| 幂运算 | EXPT | 次⽅ | - |
| 去反 | NOT | True变False,False变True | - |
| 乘法 除法 取模 | * / MOD | 除法=取商,取模=余数 | - |
| 加减法 | + - | - | |
| ⽐较 | > < <= >= | - | |
| 等于 不等于 | = <> | - | |
| 逻辑与 | AND | 按位全1为True,不全1为False | - |
| 逻辑异或 | XOR | 相同为False,不同为True | - |
| 逻辑或 | OR | 按位有1为True,全0为False | 最低 |
数据类型
codeSyS中的数据类型可以划分为三⼤类:
标准数据类型、标准的扩展数据类型、⾃定义数据类型
标准数据类型
| ⼤类型 | 数据类型 | ⼤⼩(字节) | 取值范围 |
|---|---|---|---|
| 布尔类型 | BOOL | 1 | 0或1,TRUE或FALSE |
| 字节类型 | BYTE | 1 | 0~255 |
| 字类型 | WORD | 2 | 0~65535 |
| DWORD | 4 | 0~4294967295 | |
| LWORD | 8 | 0~18446744073709551615 | |
| 整型 | SINT | 1 | -128~127 |
| USINT | 1 | 0~255 | |
| INT | 2 | -32768~32767 | |
| UINT | 2 | 0~65535 | |
| DINT | 4 | -2147483648~2147483647 | |
| UDINT | 4 | 0~4294967295 | |
| LINT | 8 | -9223372036854775808~9223372036854775807 | |
| ULINT | 8 | 0~18446744073709551615 | |
| 浮点型 | REAL | 4 | -3.4028235E+38~3.4028235E+38 |
| LREAL | 8 | -1.7976931348623157E+308~1.7976931348623157E+308 | |
| 时间类型 | TIME | 4 | 0~4294967 例如 T#0d0h0m0s0ms |
| DATE | 4 | 1970/01/01~2106/02/07 例如 T#0d0h0m0s0ms | |
| TIME_OF_DAY | 4 | 0~4294967 例如 TOD#23:33:45.888 | |
| DATE_AND_TIME | 8 | 1970/01/01~2106/02/07 例如DT#1998-04-23 00:00:00 | |
| 字符串型 | STRING | 8*N | 单个字符占8Bit=1字节 例如 ‘a’ |
可以使⽤SIZEOF(VAR) 来计算变量的⻓度:

数据存储单位的转换
1字节(Byte)= 8位(bit)
1KB(Kilo Byte,千字节)= 1024B(Byte)
1MB(Mega Byte,兆字节)= 1024KB
1GB(Giga Byte,吉字节)= 1024MB
1TB(Tera Byte,太字节)= 1024GB
1PB(Peta Byte,拍字节)= 1024TB
1EB(Exa Byte,艾字节)= 1024PB
1ZB(Zeta Byte,泽字节)= 1024EB
1YB(Yotta Byte,尧字节)= 1024ZB
1BB(Bronto Byte,珀字节)= 1024YB
1NB(Nona Byte,诺字节)= 1024BB
1DB(Dogga Byte,⼑字节)= 1024NB
BOOL类型
布尔类型内存空间是8位,也就是1个字节,声明⼀个BOOL类型的变量,会开辟8位的内存空>>间,虽然它实际上只⽤ 1位(也就是最低位), 最低位是0,则为TRUE;最低位是1, 则为FALSE;存放8个布尔类型的数组,其所占空间为8*8=64个⽐特位=8个字节
Stop : BOOL ;
Start : ARRAY[0..9] OF BOOL;
整数型
没有⼩数点的数字称为整型。其中前缀:
U表示⽆符号整型,Unsigned S表示短整型,Short
D表示双整型,Double L表示⻓整型,Long
⽆符号整型和有符号整型区别在于⼆进制的最⾼位,⽆符号整型的空间全部存储数据本身,⽽有符号整型的最⾼位
存储着符号位。⽐如INT的存储范围是16位,最⾼位是符号位,所以能存储的范围是正整数⽐⽆符号整型存储的⼩⼀半 ,本身会存放正整数⽐⽆符号整型存储的⼩⼀半
Step : INT ;
⼦范围
⼦范围是⼀种⽤户⾃定义类型,该类型定义了某种数据类型的取值范围。其值的范围是基本数据类型的⼀个⼦集。如取值从 1 到 10 或从 100 到 1000 等,如果超过范围则会报错。
<标识符> : <数据类型> (<下限>..<上限>);
// 举例
VAR nPosition:INT(0..90); END_VAR
类型限定符
<Type>#<Literal>;
指定所要求的数据类型:BOOL、SINT、USINT、BYTE、INT、UINT、WORD、DINT、 UDINT、DWORD、REAL、LREAL(类型必须使⽤⼤写字⺟)。
指定常数。输⼊的数据必须与下指定的数据类型相匹配。
Value1 :=INT#20;
Value2 :=UINT#2;
// ⼆进制
Value3 := 2#010101
// ⼋进制
Value4 := 8#23
// ⼗六进制
Value5 := 16#F1
字符串型
字符串在CodeSys中如果没有指定String类型数据的⼤⼩,默认是分配80个字符给变量,实际在内存中占⽤的是[80+1]个字节,如果指定⼤⼩,则内存中占⽤[指定的⼤⼩+1]个字节。
Name : STRING; // 默认占⽤内存80+1=81个字节
Address: STRING[2];// 占⽤内存2+1=3个字节
TEST : STRING[3] := 'ABCD'; // 值保留ABC,D会被截断
如果⽤户指定了⻓度,那么存储字符超过指定的⻓度之外的字符,会被系统进⾏截断
字符串的转义
| 字符串 | 描述 |
|---|---|
| $<两个⼗六进制数> | ASCII 码的⼗六进制表示 |
| $$ | 美元符号 |
| $’ | 单引号 |
| $L 或 $l | 输⼊⾏ |
| $N 或 $n | 新⾏ |
| $P 或 $p | 输⼊⻚ |
| $R 或 $r | 换⾏ |
| $T 或 $t | Tab 键 |
浮点数
浮点数,这⾥主要是⽤于处理含有⼩数的数值数据,实数类型包含了REAL 及 LREAL 这 2 种数据类型
Price : REAL ; // 声明变量
Price := 0.350;
Price := 3.5e-1; // 使⽤科学记数法
时间类型
TIME时间
TIME1 := T#14ms;
TIME1 := T#100S12ms; (*最⾼单位的值可以超出其限制*) TIME1 := t#12h34m15s;
TIME_OF_DAY/TOD时刻
tTime_OF_DAY:TIME_OF_DAY:= TOD #21:32:23.123;
DATE⽇期
tDate:DATE:=D#2020-08-07;
标准的扩展数据类型
有联合、⻓时间类型、双字节字符串、引⽤、指针。
| 数据类型 | 关键字 | 位数 | 取值范围 |
|---|---|---|---|
| 联合体 | UNION | —— | ⾃定义 |
| ⻓时间 | LTIME | 64 | ns~d (纳秒~天) |
| 双字节字符 | WSTRING | 8*N | —— |
| 引⽤ | REFERENCE TO | —— | ⾃定义 |
| 指针 | POINTER TO | —— | ⾃定义 |
⻓时间
与 TIME 类型不同的是:TIME 的⻓度为32 位且精度为毫秒,LTIME 的⻓度为 64 位且精度为纳秒
VAR
tLT:LTIME; // 声明⻓时间类型
END_VAR
tLT := LTIME#1000d15h23m12s34ms2us44ns; // 精度为ns
宽字符串
与字符串类型数据(ASCII)不同,这⼀数据类型由 Unicode 解码。 每个字符串占的存储空间为 2*N+2;
wstr:WSTRING:='This is a WString';
引⽤REFERENCE
引⽤是⼀个对象的别名。这个别名可以通过变量名读写。引⽤所指向的数据将被直接改变,因此引⽤的赋值和所指向的数据是相同的。设置引⽤的地址⽤⼀个特定的赋值操作完成。⼀个引⽤是否指向⼀个有效的数据(不等于 0),可以使⽤⼀个专⻔的操作符来检查,如下所示。 ⽤以下语法声明引⽤,语法格式如下。
<标识符> : REFERENCE TO <数据类型>
示例程序代码:
VAR
REF_INT : REFERENCE TO INT; // 声明INT类型的引⽤ 名字为REF_INT;Value1: INT;
Value2 : INT;
END_VAR
// 使⽤
REF_INT REF = Value1; // 此时 REF_INT 指向 Value1,相当于将给Value1变量取了⼀个别名 REF_INT := 12; //此时 Var1 的值为 12
Value2 := REF_INT * 2; // 此时 Var2 的值为 24
通过专⽤指令
__ISVALIDREF 检查变量是否已经被正确引导。
具体⽤法如下:
<布尔变量> := __ISVALIDREF(<数据类型>声明为 REFERENCE 类型);
// 如果引⽤指向⼀个有效值,则返回值<布尔变量>为真(TRUE),否则为假(FALSE);
// <数据类型>必须声明为 REFERENCE 类型
联合体
联合体概念 有时需要使⼏种不同类型的变量存放到同⼀段内存单元中(内存空间共享)
联合体的特点:联合体成员都是使⽤同⼀块空间,每次使⽤空间只能选⼀个成员使⽤,不能同时使⽤⽐如:a成员使⽤空间,那 b 成员就不能使⽤,反之b成员使⽤空间,那 a 成员就不能使⽤
TYPE Un_WORD : UNION
nWord:WORD; nByte:ARRAY [0..1] OF BYTE;
END_UNION END_TYPE
UN_Word_test.nByte[0]:=nByte_Hight;
UN_Word_test.nByte[1]:=nByte_Low;
指针
指针就是⼀个地址(指向某⼀段内存空间的起始位置)所谓指针变量,也就是保存了内存地址的变量,计算机中所
有的数据都必须放在内存中,不同类型的数据占⽤的字节数不⼀样,例如 int 占⽤ 4 个字节,char 占⽤ 1 个字节。
为了正确地访问这些数据,必须为每个字节都编上号码,就像⻔牌号、身份证号⼀样,每个字节的编号是唯⼀的,
根据编号可以准确地找到某个字节。
声明指针的语法如下:
<标识符>: POINTER TO <数据类型 | 功能块 | 程序 | ⽅法 | 函数>;
类型可以为变量、程序、功能块、⽅法和函数的内存地址
通过在指针标识符后添加内容操作符“^”,可以取得指针所指地址的内容
指针只能存放1个字节⼤⼩的数据
指针+1只移动⼀个byte⼤⼩的内存地址
VAR
PointVar:POINTER TO INT; // 定义⼀个变量PointVar类型为指针类型var1:INT := 5;
var2:INT;
END_VAR
(*************************************************
ADR 指令,该指令是⽤来获取变量内存地址的操作符,执⾏完第⼀条指令后,
PointVar 内就已经获取 了 var1 的内存地址信息
*************************************************)
PointVar := ADR(var1); // 取地址
var2:= PointVar^; // 解指针,获取指针对应的地址的内容,并将值传递给Var2变量
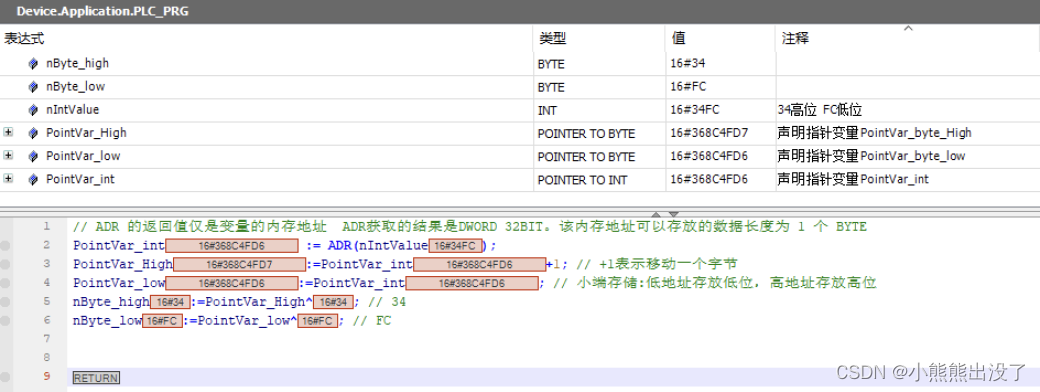
获取⾼低位的示例
VAR
PointVar_int:POINTER TO INT; // 声明指针变量PointVar_int PointVar_low:POINTER TO BYTE; // 声明指针变量PointVar_byte_low PointVar_High:POINTER TO BYTE; // 声明指针变量PointVar_byte_High nIntValue:INT := 16#34FC; // 34⾼位 FC低位
nByte_low:BYTE;
nByte_high:BYTE;
END_VAR
// ADR 的返回值仅是变量的内存地址 ADR获取的结果是DWORD 32BIT。该内存地址可以存放的数据⻓度为 1 个 BYTE
PointVar_int := ADR(nIntValue);
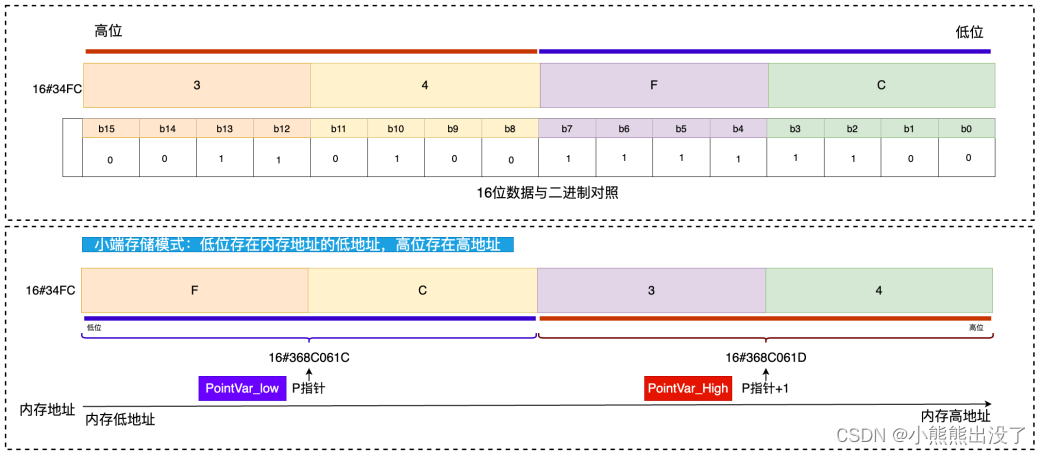
PointVar_High:=PointVar_int+1; // +1表示移动⼀个字节
PointVar_low:=PointVar_int; // ⼩端存储:低地址存放低位,⾼地址存放⾼位nByte_high:=PointVar_High^; // 23
nByte_low:=PointVar_low^; // FC
和c语⾔⽐较:c语⾔中指针+1,跳过当前指针类型⼤⼩的字节数
#include <stdlib.h>
int main()
{
int a = 10;
int *p = &a;
int *pp = p + 1;//+1,跳过当前指针类型⼤⼩的字节数
printf("p指针的地址:%p",p); //p 指针的地址:0x7ffdcb5fa9fc
printf("pp指针的地址:%pp",pp);//pp指针的地址:0x7ffdcb5faa00
return(0);
}
指针内存分析图
⾃定义数据类型
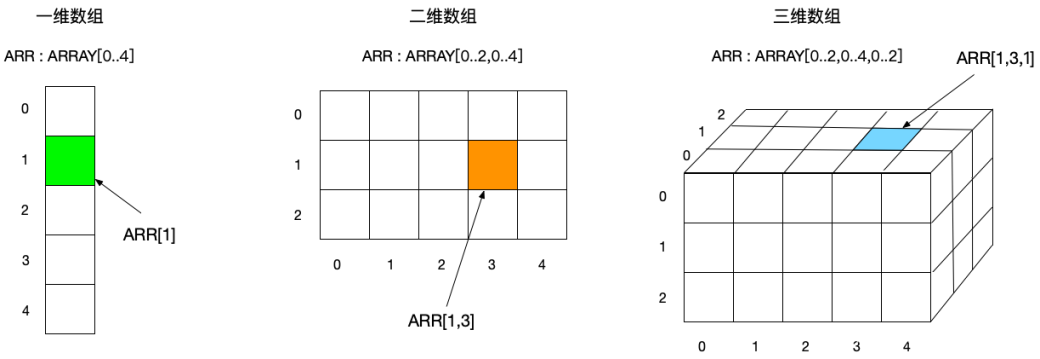
数组
数组是有序的存储在连续空间中的相同类型的⼀组数据。数组有⼀维、⼆维和三维数组。数组变量从字边界开始,也就是说,起始地址为偶数 BYTE 地址。随后,每个结构元素以其声明时的顺序依次存储到内存中
⼆维数组可以看作是⼀个特殊的⼀维数组,它⾃身的元素可以理解为⼜是⼀个新的⼀维数组
声明数组的语法
<数组名>:ARRAY [<ll1>..<ul1>,<ll2>..<ul2>,<ll3>..<ul3>] OF <基本数据类型>
示例程序代码:
// ⼀维数组
arrInt : ARRAY[0..9] OF INT; // ⻓度为10的int数组
// ⼆维数组
arrBool : ARRAY[0..2,3..4] OF BOOL; // ⻓度为3*2=6的bool数组// 三维数组
arrWord : ARRAY[0..2,3..4,0..4] OF WORD; // ⻓度为3*2*5=30的word数组
数组的初始化
// 完全初始化
arrBool : ARRAY[0..3] OF BOOL := [TRUE,TRUE,TRUE];//初始化三个值为true
// 使⽤缩写完全初始化数组
arrBool : ARRAY[0..9] OF BOOL := [10(TRUE)]; // ⻓度为10的bool数组,并完全初始化数组的10个元素
arrBool : ARRAY[0..3,1..5] OF BOOL := [4(TRUE),5(TRUE)]; // ⻓度为4*5=20的bool⼆维数组,并完全初始化数组的50个元素
// 不完全初始化
arrBool : ARRAY[0..3] OF BOOL := [TRUE,TRUE];//初始化2个值为true,最后⼀个值为FALSE
arrBool : ARRAY[0..9] OF BOOL := [4(TRUE),2(FALSE),4(TRUE)]; // ⻓度为10的bool数组,并初始化数组的前4个元素为TRUE,中间2个元素为FALSE,后⾯4个元素为TRUE
arrBool : [0..3,1..5] OF BOOL := [10(TRUE),2(FALSE),4(TRUE)]; // ⻓度为10的bool数组,并初始化数组的前10个元素为TRUE,2个为FAlSE,4个为TRUE,剩下的4个未显示初始化的默认为FALSE
数组的赋值
// ⼀维数组
arr1 : ARRAY [1..5] OF INT; // 定义了⼀个⻓度为5的⼀维int数组
arr1[1] := 10;// 给数组的第1个元素赋值
arr1[2] := 20;// 给数组的第2个元素赋值
arr1[3] := 30;// 给数组的第3个元素赋值
arr1[4] := 40;// 给数组的第4个元素赋值
// ⼆维数组
arrs : ARRAY[0..2,1..3] OF BOOL; arrs[0,1] := TRUE; // 给数组的第1个元素赋值
arrs[0,2] := TRUE; // 给数组的第2个元素赋值
arrs[0,3] := FALSE; // 给数组的第3个元素赋值
arrs[1,1] := TRUE; // 给数组的第4个元素赋值
arrs[1,2] := TRUE; // 给数组的第5个元素赋值
arrs[1,3] := FALSE; // 给数组的第6个元素赋值
arrs[2,1] := TRUE; // 给数组的第7个元素赋值
arrs[2,2] := TRUE; // 给数组的第8个元素赋值
arrs[2,3] := FALSE; // 给数组的第9个元素赋值
数组索引越界
使⽤数组的下标对数组元素进⾏访问时,下标访问超出数组元素个数时发⽣数组索引越界异常
arrInt : ARRAY[0..2] OF INT ;
// 访问数组元素arrInt[0] := 10 ; // 正常访问
arrInt[0] := 20 ; // 正常访问
arrInt[0] := 30 ; // 访问越界异常 OutBoundException
结构体
结构(struct)是由⼀系列具有相同类型或不同类型的数据构成的数据集合。结构体其最主要的作⽤就是封装。封装的好处就是可以再次利⽤。
结构变量从字边界开始,也就是说,起始地址为偶数字节地址。随后,每个结构元素以其声明时的顺序依次存储到内存中。
数据类型为 BOOL,BYTE 的结构元素从偶数字节开始存储,其他数据类型的数组元素从字地址开始存储。
TYPE <结构名>: STRUCT
<变量的声明 1>
.
.
<变量声明 n>
END_STRUCT END_TYPE
示例程序代码:
TYPE Person: // 定义⼀个⼈类的结构体
STRUCT
Name : STRING ; // 姓名
Age : UINT ; // 年龄
Address : STRING ; // 地址
Weight : REAL ; // 重量
END_STRUCT
END_TYPE
结构体的嵌套
结构体内的元素称为结构体成员,结构体成员可以是基本类型或者是结构体,通过结构体名
. 成员名来访问
示例:
// 结构体A
TYPE Astruct :
STRUCT
Name : STRING;
Age : INT ;
END_STRUCT
END_TYPE
// 结构体B
TYPE Bstruct:
STRUCT
Price : REAL ;
Number : INT ;
END_STRUCT
END_TYPE
// 结构体C 中包含结构体A和结构体B
TYPE Cstruct:
STRUCT
a : Astruct ;
b : Bstruct ;
c : BOOL ;
d : INT ;
END_STRUCT
END_TYPE
// 访问结构体
Cstruct.a.Name := 'min'; // 使⽤ . 符号来访问其成员Cstruct.d := 20 ;
结构体类型嵌套的可视化

数组结构体
结构体数组与基本类型数组的数值型数组不同⽀持在于每个数组元素都是⼀个结构体类型的数据,它们都分别包括各个成员项。
// 定义⽓缸结构体
TYPE Cylinder:
STRUCT
CyName : STRING ; // ⽓缸名称
Number : INT ; // ⽓缸编号
Extension_Q : BOOL ; // 伸出输出信号
Retraction_Q : BOOL ; // 缩回输⼊信号
Extension_I : BOOL ; // 伸出输⼊信号
Retraction_I : BOOL ; // 缩回输⼊信号
END_STRUCT
END_TYPE
// 声明数组结构体
VAR
CYs : ARRAY[0..9] OF Cylinder ;
END_VAR
// 使⽤
CYs[0].CyName := '移栽⽓缸' ;
CYs[0].Number := 1 ;
CYs[0].Extension_Q := TRUE ;
CYs[0].Extension_I := TRUE ;
CYs[0].Retraction_Q := FALSE ;
CYs[0].Retraction_I := FALSE ;
CYs[1].CyName := '顶升⽓缸' ;
CYs[1].Number := 2 ;
CYs[1].Extension_Q := TRUE ;
CYs[1].Extension_I := TRUE ;
CYs[1].Retraction_Q := FALSE ;
CYs[1].Retraction_I := FALSE ;
枚举
枚举的概念 如果⼀种变量有⼏种可能的值,可以定义为枚举类型。所谓“枚举”是将变量的值⼀⼀列举出来,
变量的值只能在列举出来的值的范围内
枚举类型声明的语法如下:
TYPE <标识符>: (<Enum_0> , <Enum_1>, ..., <Enum_n>) |<基本数据类型>; END_TYPE
示例代码:
TYPE Weekday :
(Sun:=0,
Mon:=1,
Tue:=2,
Wed:=3,
Thu:=4,
Fri:=5,
Sat:=6);
END_TYPE
变量
变量的命名,推荐使⽤匈⽛利命名法。st语⾔不区分⼤⼩写。
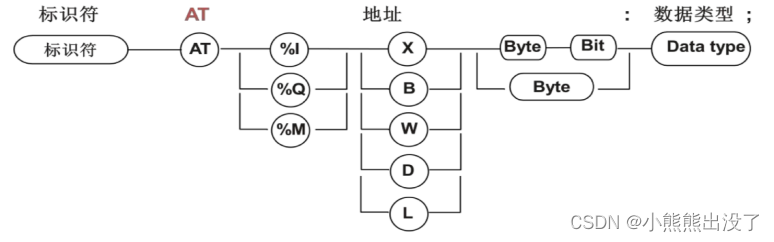
变量声明的语法,{} 内部为可选
变量名 { AT 地址 }: 类型 {:= 初始值 };
bButton : BOOL := TRUE ;
Btn : R_TRIG ; // 上升沿
变量名不能是系统关键字,下⾯是图示变量的定义
存储位置前缀
I:表示输⼊单元
Q:表示输出单元
M:表示存储区单元
数据⼤⼩前缀
X表示位,类型为BOOL
B表示字节,类型为BYTE
W表示字,类型为WORD
D表示双字,类型为DWORD
L表示⻓字,类型为LWORD
如果未显示指定,那么系统⾃动分配
ValueName AT%ID48:DWORD; // 表示I区 双字类型 整个含义为将变量存储到I区D48位置
全局变量
在POU之外定义的变量称为全局变量。对应⽤中所有单元都可⻅,同时也具备对外界访问交互的能⼒(需要在符号中对其公开读/写权限)。⽐如和上位机进⾏交互,和扫码枪进⾏交互。
VAR_GLOBAL// 声明全局变量
BUTTON : ARRAY[0..10] OF BOOL;
END_VAR
注意:全局变量名不能重复
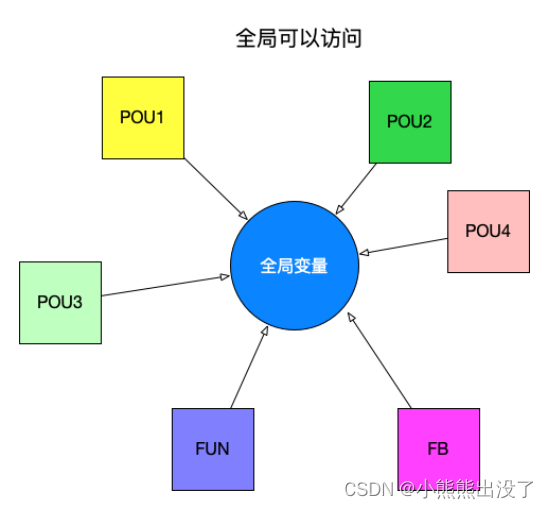
局部变量
定义在POU或者功能块FBD或功能FC内部的变量,局部变量只能在当前的POU中进⾏访问,不同的POU中局部变量可以重名,且不会相互影响。
- 变量是⽤于存储数据,变量具有名称,类型和值
- 变量的值可以发⽣变化
- 变量在使⽤之前必须先声明变量,及指定变量的类型和名称
语法如下:
VAR
< 变量名 >:<数据类型> {:=<初值>} ;// {}内部是可以省略的
END_VAR
// 变量名⻅名知意即可
// 数据类型可以是基本数据类型、系统内置引⽤类型(上升、下降沿)或者⽤户⾃定义类型(结构体、枚举、联合体等)
Button : bool ; // 定义⼀个名称为Button 类型为布尔类型的变量
R_click: R_TRIG ; // 定义⼀个变量名为R_click,类型为R_TRIG上升沿类型(功能块) 也成为实例化
变量的赋值
// 基本类型
<变量名> := 值 ; Button := True ; // 变量赋值
// 功能块类型(引⽤类型)
R_click(In:= ,PT:= , ET=> , Q=> ); // 调⽤实例化定时器功能块// 或者使⽤拆分赋值
R_click.In := 值 ;
R_click.PT := 值 ;
R_click();
变量名 := R_click.ET;
变量名 := R_click.Q ;
变量的细分
本地变量、输⼊变量、输出变量、输⼊输出变量、临时变量、静态变量、配置变量
本地变量
在POU内部VAR和END_VAR之间的变量都为本地变量,不能被外部访问。
输⼊变量
在POU内部VAR_INPUT和END_VAR之间的变量都为输⼊变量,可以在调⽤位置给输⼊变量赋值。不可以在程序内部修改值
VAR_INPUT
iIn1:INT; (* 输⼊变量*)
END_VAR
输出变量
在POU内部VAR_OUTPUT和END_VAR之间的变量都为输出变量。输出变量可以在调⽤时返回给调⽤者,调⽤者可以做进⼀步处理。可以被程序内部修改值
VAR_OUTPUT
iOut1:INT; (* 输出变量*)
END_VAR
输⼊输出变量
在POU内部VAR_IN_OUT和END_VAR之间的变量都为输⼊输出变量。输⼊输出变量不仅可以传⼊被调⽤的POU内,并且可以在被调⽤的POU内部修改。实际上传递给被调⽤POU内的变量是调⽤者变量的引
⽤
VAR_IN_OUT
iInOut1:INT; (* 输⼊输出变量*)
END_VAR
临时变量
定义在VAR_TEMP和END_VAR之间的变量为临时变量,临时变量在每次调⽤时会进⾏初始化(复位)。
VAR_TEMP
iTemp1:INT; (*临时变量*)
END_VAR
静态变量
不常⽤。定义在VAR_STAT和END_VAR之间的变量都为静态变量。静态变量在第⼀次调⽤时被初始化,在每次调⽤完此POU后,变量值依然保持下来。
VAR_STAT
iStat1:INT; (*静态变量*)
END_VAR
配置变量
定义在VAR_CONFIG和END_VAR之间的变量都为配置变量。配置变量是直接变量,⼀般是映射到功能块定义的不确定地址直接变量。在功能块内可以定义⼀个不确定地址的变量,此变量的地址通过* 来表示不确定的地址(任意的地址),然后添加⼀个配置变量表(通过添加全局变量表⽅式),把所有功能块实例中不确定地址变量添加到配置变量表中,在此变量表中把所有的不确定地址给明确下来,这样就可以集中管理所有功能块中不确定地址变量
功能块不确定地址变量定义语法:
<标识符> AT %<I|Q|M>* : <数据类型> 地址的最终确定是在全局变量列表的“变量配置”中完成:
// 示例
FUNCTION_BLOCK locio
VAR
xLocIn AT %I*: BOOL := TRUE;
xLocOut AT %Q*: BOOL;
END_VAR
常量
⼀些数值不变的参数,如定时器的时间、换算的⽐例等,这些数值不变的参数称为常量
VAR CONSTANT
c_iCon1:INT:=12;
END_VAR
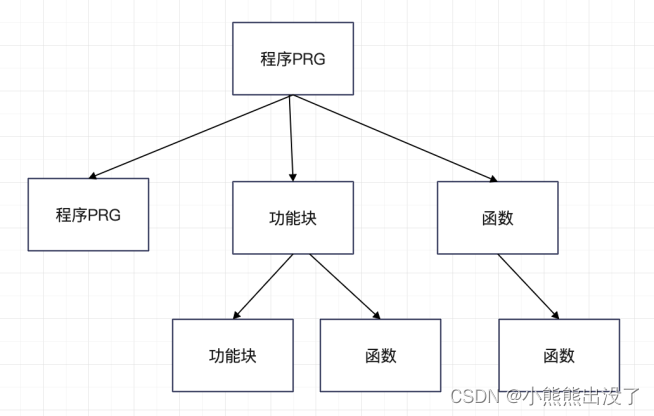
函数
函数Function是特殊的POU它可以被赋予参数,但是没有静态变量的程序组织单元。输⼊相同的参数总能的到相同的返回值。它的⼀⼤特点是不能使⽤内部变量存储值,运⾏时未被分配内存空间的单元算法。其声明的语法:
FUNCTION <函数名/函数返回值>:<返回值的数据类型>
VAR_INPUT
// 输⼊参数
END_VAR
VAR_OUTPUT
// 输出参数
END_VAR
VAR
// 函数内部变量
END_VAR
函数的特点:
- 可以有多个输⼊参数,但是返回值只有⼀个,对于返回值没有限定,可以返回复杂的结构体类型。
- 函数不能在内部存储值
- 函数使⽤时候不需要实例化
- 函数内部不能使⽤FBD功能块,函数只能调⽤函数。
- 函数可以被重载和扩展
– 梯形图中EN和ENO是函数的输⼊使能和输出使能,输⼊使能为true时,函数才开始执⾏。 - 函数调⽤时必须传⼊参数,可以指定传⼊,也可以按照顺序
功能块
功能块中拥有⾃⼰的空间,可以存放⾃⼰的内部变量,程序执⾏时会被功能块的实例分配内存空间。可以理解为⾼级语⾔中的类,可以通过类实例化对象,不同的对象具有不同的属性。
FUNCTION_BLOCK <功能块名字> {EXTENDS <⽗类功能块名>} // 括号内可省略VAR_INPUT
// 输⼊参数
END_VAR
VAR_OUTPUT
// 输出参数
END_VAR
VAR
/ / 函数内部变量
END_VAR
// 实例化 变量名 : 功能块名 ;
TonTest : TON ; // 定义⼀个定时器
// 调⽤
TonTest(IN:, PT:, ET=>, Q=> );
功能块特点:
- 功能块内部的变量和输出变量可以使⽤
RETAIN关键字修饰,使变量具有保持性,输⼊变量只能在调⽤时候声明为保持性变量 - ⼀般不允许对输⼊变量进⾏赋值
- 功能块可以调⽤函数和其他的功能块
- 功能块中不允许将固定地址变量作为局部变量可以使⽤
VAR_IN_OUTPUT类型来代替VAR_INPUT和VAR_OUTPUT类型的变量,减少内存空间的使⽤ - 功能块可以使⽤
extends来继承,使⽤SUPER.来调⽤⽗功能块的⽅法 - 功能块在调⽤时,允许不传⼊参数
程序
在程序中可以定义普通全局变量、映射硬件地址的全局变量、局部变量。程序必须与任务相结合,否则程序不会被执⾏。
掉电保持型变量
掉电保持型变量必须在全局变量表中定义,使⽤PERSISTENT或PERSISTENT RETAIN 来表示,语法如下:
VAR_GLOBAL PERSISTENT // 掉电保持变量申明END_VAR
VAR_GLOBAL PERSISTENT RETAIN // 掉电保持变量申明END_VAR
掉电保持型变量对⽐表,❌表示恢复初始值,✅表示保留原值
| 命令 | var | PERSISTENT | PERSISTENT RETAIN |
|---|---|---|---|
| 热复位 | ❌ | ✅ | ✅ |
| 冷复位 | ❌ | ❌ | ✅ |
| 初始值复位 | ❌ | ❌ | ❌ |
| 下载 | ❌ | ❌ | ✅ |
| 在线修改 | ✅ | ✅ | ✅ |
逻辑指令
IF判断指令
通过IF关键字,可以判断执⾏条件,根据执⾏条件,执⾏相应的指令

// ⽆分⽀
IF <布尔表达式1> THEN
// 条件成⽴执⾏
END_IF;
// 两条分⽀
IF <布尔表达式1> THEN
// 条件成⽴执⾏
ELSE
// 条件不成⽴执⾏
END_IF;
// 带条件的分⽀
IF <布尔表达式1> THEN
// 条件1成⽴执⾏
ELSIF <布尔表达式2> THEN
// 条件2成⽴执⾏
ELSIF <布尔表达式3> THEN
// 条件3成⽴执⾏
END_IF;
示例代码:
IF temp<17 THEN
heating_on := TRUE;
ELSE
heating_on := FALSE;
END_IF;
CASE指令
使⽤CASE指令,可以根据⼀个条件变量,根据其对应的多个值罗列处理对应的命令。条件变量只能是整数。

语法代码:
CASE <变量> OF
<值1>: // 变量的值等于值1的时候执⾏
// 指令1 ;
<值2>: // 变量的值等于值2的时候执⾏
// 指令2
<值3,值4,值5>: // 变量的值等于值3、值4、值5的时候执⾏
// 指令3
<值6..值10>: // 变量的值等于值6到值10之间的时候执⾏
// 指令4
... 省略多条CASE
<值 n>:
// 指令n
ELSE
// 没有匹配到任何⼀个值,则这⾥会执⾏
END_CASE;
示例代码:
CASE Value OF
0:
Value:= 1;
1:
Value:= 2;
3,4,5:
Value:= 3;
6..9:
Value:= 4;
ELSE
Value:= 100;
END_CASE;
FOR循环
通过FOR循环,可以编写重复处理逻辑。

语法:
// 初始值不允许⼤于结束值
// 计数器变量值⼤于结束值时停⽌循环
// {}内部可选值,步⻓省略默认每次+1,不省略每次增加指定步
FOR <计数器变量> := <初始值> TO <结束值> {BY <步⻓>} DO
// 逻辑指令
END_FOR;
// 举例
FOR Counter:=0 TO 5 BY 1 DO // 当Counter⼤于6时结束for循环
Var1:=Var1*2;
END_FOR;
WHILE 循环
WHILE循环条件可以是任意布尔表达式 。⼀旦循环条件满⾜,循环就执⾏,否则退出循环。

语法代码:
WHILE <布尔表达式> DO
// 相应逻辑
END_WHILE;
REPEAT循环
REPEAT循环不同于WHILE循环,因为循环条件是在循环指令执⾏后才检查的,循环⾄少执⾏⼀次,不管循环条件值如何。

语法代码:
REPEAT
// 相应逻辑,⾄少执⾏⼀次
UNTIL <布尔表达式>
END_REPEAT;
CONTINUE语句
CONTINUE指令在FOR、WHILE和REPEAT循环中使⽤,⽤于提前结束本轮循环,并重新开始下⼀轮循环。
FOR Counter:=1 TO 5 BY DO
IF Counter=3 THEN
// if条件成⽴时,遇到CONTINUE关键字,跳过本次循环,进⼊下⼀次循环
CONTINUE;
END_IF
END_FOR;
EXIT语句
EXIT指令⽤于退出FOR、WHILE和REPEAT循环
语法代码:
FOR Counter:=1 TO 5 BY DO
IF Counter=4 THEN
// if条件成⽴时,遇到EXIT关键字结束循环EXIT;
END_IF;
END_FOR;
JMP语句
JMP指令可⽤于⽆条件的跳转到指定标签处的代码⾏。 类似于CASE语句,JMP指令必须有⼀个跳转⽬标,也就是预定义的标签。到达JMP指令后,程会跳转到指定的标签处开始执⾏。这样的功能也可以通过WHILE 或 REPEAT循环来实现
语法代码:
<标签名>: JMP <标签名>;
RETURN 指令
RETURN 指令是返回指令,⽤于退出程序组织单元(POU),具体格式如下。
RETURN;
指令
沿指令
包括
- 上升沿R_TRIG
- 下降沿指令 F_TRIG
边沿检测指令⽤来检测 BOOL 信号的上升沿 (信号由 0→1)和下降沿(信号由 1→0)的 变化
在每个扫描周期中把信号 状态和它在前⼀个扫描周期的状态进⾏⽐较,若 不同则表明有⼀个跳变沿。因此,前⼀个周期⾥ 的信号状态必须被存储,以便能和新的信号状态 相⽐较。
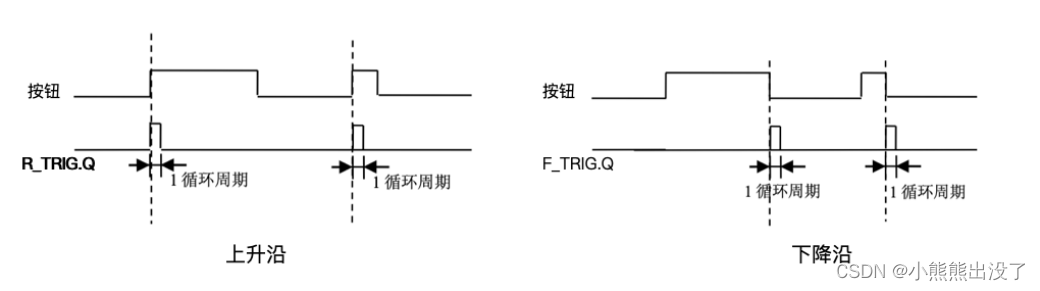
| 变量名 | 说明 |
|---|---|
| CLK | 触发上升沿/下降沿的条件 |
| Q | 上升沿/下降沿的输出 |
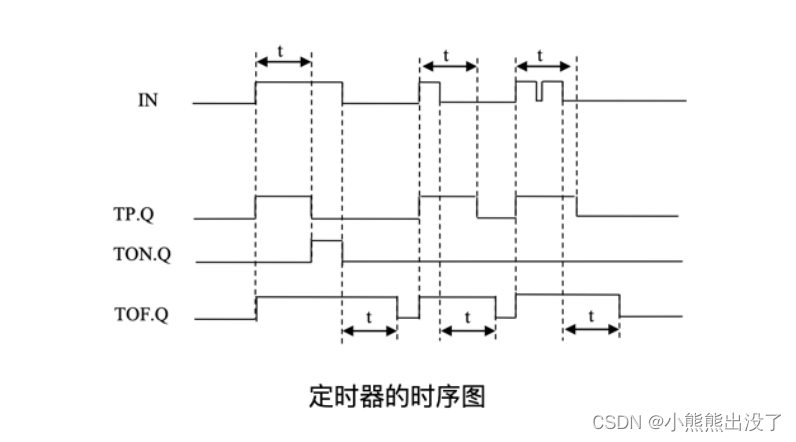
定时器
- 分为脉冲定时器 TP
- 通电延时定时器 TON
- 断电延时 定时器 TOF
- 实时时钟 RTC
脉冲定时器 、通电延时定时、 断电延时定时器 TOF的参数:
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| IN | 输⼊变量 | BOOL | 启动输⼊ |
| PT | 输⼊变量 | TIME | 延时时间 |
| Q | 输出变量 | BOOL | 定时器输出 |
| ET | 输出变量 | TIME | 当前定时时间 |
脉冲定时器 TP
功能:脉冲定时。
语法:在定时器的输⼊端 IN 从“0”变为“1”时,定时器则启动,⽆论定时器输⼊端 IN 如何变化,定时器的实际运⾏时间都是⽤户所定义的 PT 时间,在定时器运⾏时,其输出端 Q 的输出信号为“1”。
输出端 ET 为输出端 Q 提供定时时间。定时从 T#0s 开始,到设置的 PT 时间结束。当 PT 时间到时,ET 会保持定时时间直到 IN 变为“0”时。如果在达到 PT 定时时间之前输⼊ IN 已经变成“0”,输⼊ ET 编程 T#0s,PT 定时的时刻。复位该定时器,只需要设置 PT=T#0s 即可。
通电延时定时器 TON
功能:通电延时定时。
在定时器的输⼊端 IN 从“0”变为“1”时,定时器则启动,当到达定时时间 PT 且输⼊端的信号 IN 始终维持在“1”时,其输出端 Q 的输出信号为“1”,如果在定时器的定时时间到达之前,输⼊端 IN 信号由“1”变为“0”时,则定时器复位,下⼀个 IN 信号的上升沿定时器重启。 输出端 ET 提供定时时间,延时从 T#0s 开始,到设置的 PT 时间结束。PT 到达时,ET 将会保持定时时间直到 IN 变为“0”为⽌。如果在达到 PT 定时时间之前,输⼊ IN 变为“0”,输出 ET ⽴即变为 T#0s。为了重启定时器,可以设置 PT=T#0s,也可以将 IN=FALSE。
断电延时定时器 TOF
功能:断电延时定时。
在定时器的输⼊端 IN 从“0”变为“1”时,定时器的 Q 输出信号为“1”,定时器的启动输⼊端变为“0”时,定时器则启动,只要当定时器在运⾏,其输出 Q ⼀直为“1”,当到达定时时间时,输出端 Q 复位,在到达定时时间之前,如果定时器的输⼊端返回为“1”,则定时器复位,输出端的 Q 输出信号保持为“1”。可参考图 6.x 中的 TOF 相关时序图。
输出端 ET 提供定时时间,延时从 T#0s 开始到设置的定时时间 PT 结束。当 PT 时间到时,ET将保持定时时间直到输⼊ IN 返回“1”为⽌。如果在达到 PT 定时时间之前,输⼊ IN 变为“1”,输出 ET ⽴即变为 T#0s。复位定时器,可以设置将 PT=T#0s。
实时时钟 RTC
功能:在给定时间启动,返回当前⽇期和时间。
语法:RTC(EN, PDT, Q, CDT) 表示:当 EN 为 “0”,输出变量 Q 以及 CDT 为 “0”相关时间为 DT#1970-01-01-00:00:00。⼀旦 EN 为“1”,PDT 给予的时间将会被设置,并且将会以秒进⾏计数⼀旦 EN 为 TRUE 将返回 CDT 。⼀旦 EN 被复位为 FALSE, CDT 将会被复位为初始值 DT#1970-01-01-00:00:00。请注意,PDT 时间只上升沿有效。
标准定时器指令参数
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| EN | 输⼊变量 | BOOL | 启动使能 |
| PDT | 输⼊变量 | DATE_AND_TIME | 设置将要启动的时间和⽇期 |
| Q | 输出变量 | BOOL | 状态输出 |
| CDT | 输出变量 | DATE_AND_TIME | 当前计数时间和⽇期的状态 |
计数器指令
标准功能库中提供了加、减计数功能块,系统提供了 CTU 加计数器、CTD 减计数器和 CTUD 加减计数器三个功能块
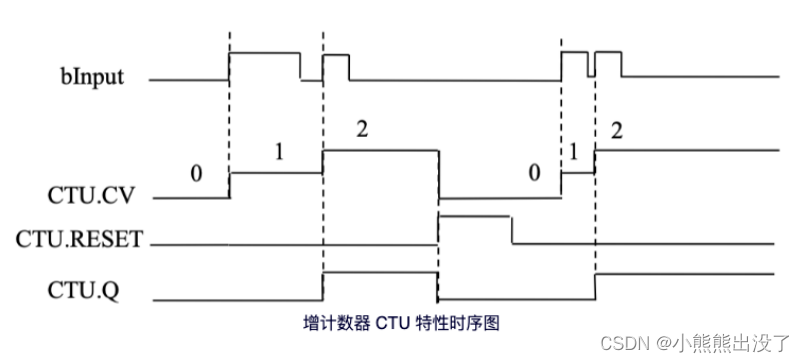
增计数器 CTU
当计数器输⼊端 CU 的信号从状态“0”变为状态“1”时,当前计算值加 1,并通过输出端CV 进⾏显示,第⼀次调⽤时(复位输⼊ RESET 信号状态为“0”),输⼊ PV 端的计数为默认值,当计数达到上限 32767 后,计数器将不会再增加,CU 也不会再起作⽤。
当复位输⼊端 RESET 的信号状态为“1”时,计数器的 CV 和 Q 都为“0”,只要输⼊端RESET 状态为“1”,上升沿对 CU 就不再起作⽤。当 CV 值⼤于或等于 PV 时,输出端 Q 为“1”。此时 CV 仍可继续累加,输出端 Q 继续为输出“1” 。
增量功能块。输⼊变量 CU 和复位 RESET 以及输出变量 Q 是布尔类型的,输⼊变量 PV 和输出变量 CV 是 WORD 类型。
CV 将被初始化为 0 ,如果复位 RESET 是 TRU 真的。如果 CU 有⼀个上升沿从 FALSE 为TRUE ,CV 提升 1,Q 将返回 TRUE,如此 CV 将⼤于或等于上限 PV。
减计数器 CTD
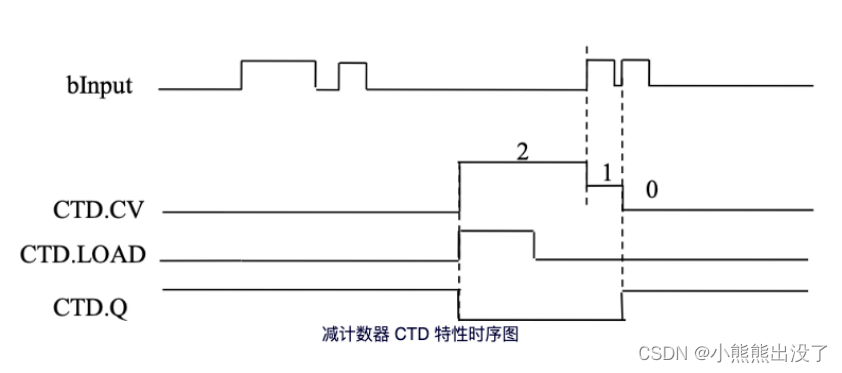
当减计数器输⼊端的 CD 信号从“0”变为状态“1”时,当前计数值减 1,并在输出端上 CV 显示当前值,第⼀次调⽤时(需要将加载输⼊端信号 LOAD 初始化,需要将其从“0”变为状态。
“1”,再变为状态“0”后功能块才能⽣效),输⼊ PV 端的计数为默认值,当计数达到 0 后,计数值将不在会减少,CD 也不再起作⽤。
当加载输⼊端信号 LOAD 为“1”时,计数值将设定成 PV 默认值,只要加载输⼊端信号LOAD 状态为“1”,输⼊端的 CD 上升沿就不起作⽤。
增/减双向计数器 CTUD
当加计数输⼊端的 CU 信号从“0”变为状态“1”时,当前计数值加 1,并在输出 CV 上线时。当减计数输⼊端的 CD 的信号状态从“0”变为状态“1”时,当前计数值减 1,并在输出端 CV 上显示。如果两个输⼊端都是上升沿,当前计数值将保持不变。
当计数值达到上限值 32767 后,加计数输⼊端 CU 的上升沿不再起作⽤。因此即使加计数输⼊端 CU 出现上升沿,及数值也不会增加。同理,当计数值达到下极限值 0 后,减计数输⼊端 CD 也不会在其作⽤,因此,即使减计数输⼊端 CD 出现上升沿,计数值也不会减少。
当 CV 值⼤于或等于 PV 值时,输出 QU 为“1”。当 CV 值⼩于或等于 0 时,输出 QD 为“1”。
选择操作指令
⼆选⼀指令 SEL
功能:通过选择开关,在两个输⼊数据中选择⼀个作为输出,选择开关为 FALSE 时,输出为第⼀个输⼊数据,选择开关为 TRUE 时,输出为第⼆个数据。
语法:其⽂本化语⾔语法格式如下,
OUT := SEL(G, IN0, IN1) // G为true 选择IN1; G为False 选择IN0;
参数 G 必须是布尔变量。如果 G 是 FALSE,则返回值的结果是 IN0, 如果 G 是 TRUE ,则返回值的结果为 IN1。
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| G | 输⼊变量 | BOOL | 输⼊选择位 |
| IN0 | 输⼊变量 | 任意类型 | 输⼊数据0 |
| IN1 | 输⼊变量 | 任意类型 | 输⼊数据1 |
| 返回值 | 输出变量 | 任意类型 | 返回结果 |
取最⼤值 MAX
功能:最⼤值函数。在多个输⼊数据中选择最⼤值作为输出。
语法:其⽂本化语⾔语法格式如下所示,
OUT := MAX(IN0, …,INx);// 返回值最⼤值
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| IN0 | 输⼊变量 | 任意类型 | 输⼊数据0 |
| INx | 输⼊变量 | 任意类型 | 输⼊数据x |
| 返回值 | 输出变量 | 任意类型 | 返回输⼊变量的最⼤值 |
取最⼩值 MIN
功能:最⼩值函数。在多个输⼊数据中选择最⼩值作为输出。
语法:其⽂本化语⾔语法格式如下所示, IN0, INn 以及 OUT 可以是任何数据类型
OUT := MIN(IN0, …,INn) ;
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| IN0 | 输⼊变量 | 任意类型 | 输⼊数据0 |
| INx | 输⼊变量 | 任意类型 | 输⼊数据x |
| 返回值 | 输出变量 | 任意类型 | 返回输⼊变量的最⼩值 |
限制值 LIMIT
功能:限制值输出。判断输⼊数据是否在最⼩值和最⼤值之间,若输⼊数据在两者之间,则直接把输⼊数据作为输出数据进⾏输出。
若输⼊数据⼤于最⼤值,则把最⼤值作为输出值。若输⼊数据⼩于最⼩值,则把最⼩值作为输出值。
语法:其⽂本化语⾔语法格式如下, IN, Min ,Max 以及返回值可以是任何数据类型
OUT := LIMIT(Min, IN, Max) ;
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| Min | 输⼊变量 | 任意类型 | 最⼩值 |
| IN | 输⼊变量 | 任意类型 | ⽐较的值 |
| Max | 输⼊变量 | 任意类型 | 最⼤值 |
| 返回值 | 输出变量 | 任意类型 | 若输⼊数据⼤于最⼤值,则把最⼤值作为输出值。若输⼊数据⼩于最⼩值,则把最⼩值作为输出值。 |
多选⼀ MUX
功能:多路器操作。通过控制数在多个输⼊数据中选择⼀个作为输出。
语法:其⽂本化语⾔语法格式如下,IN0,…,INn 以及 返回值可以是任何变量类型。但是 K 必须为 BYTE, WORD, DWORD, LWORD, SINT, USINT, INT, UINT, DINT, LINT, ULINT 或者 UDINT。 MUX 从变量组中选择第 K 个数据输出。
OUT := MUX(K, IN0,...,INn) ;
| 名称 | 定义 | 数据类型 | 说明 |
|---|---|---|---|
| K | 输⼊变量 | 整数类型 | MUX 从变量组中选择第 K 个数据输出 |
| IN0 | 输⼊变量 | 任意类型 | 备选值0 |
| INx | 输⼊变量 | 任意类型 | 备选值x |
| 返回值 | 输出变量 | 任意类型 | 选择第 K 个数据输出 |
位移指令
按位左移 SHL
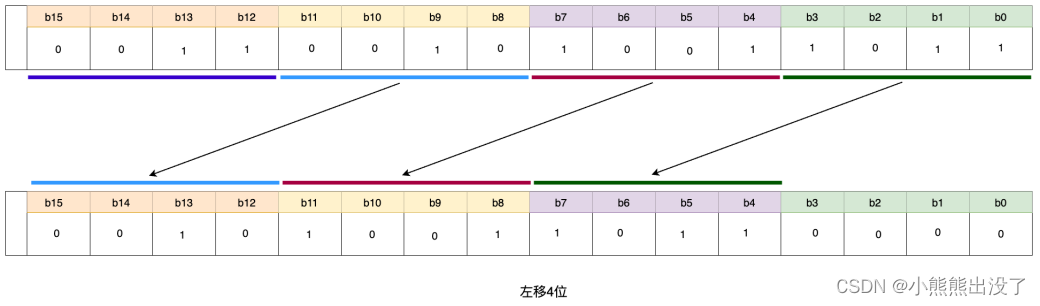
功能:对操作数进⾏按位左移,左边移出位不做处理,右边空位⾃动补 0。 语法:指令可以将输⼊ IN 中的数据左移 n 位,输出结果赋值⾄ OUT,⼆进制数左移⼀位相当于将原数乘以 2。
如果 n ⼤于数据类型宽度,BYTE, Word 和 DWORD 值将填补为零。
⽂本化语⾔语法格式如下:
OUT:= SHL (IN, n) ;// IN输⼊数据,n位移的宽度
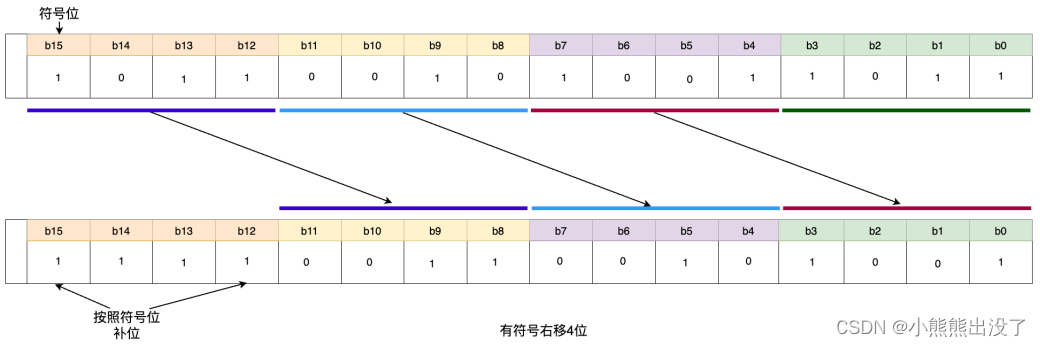
按位右移 SHR
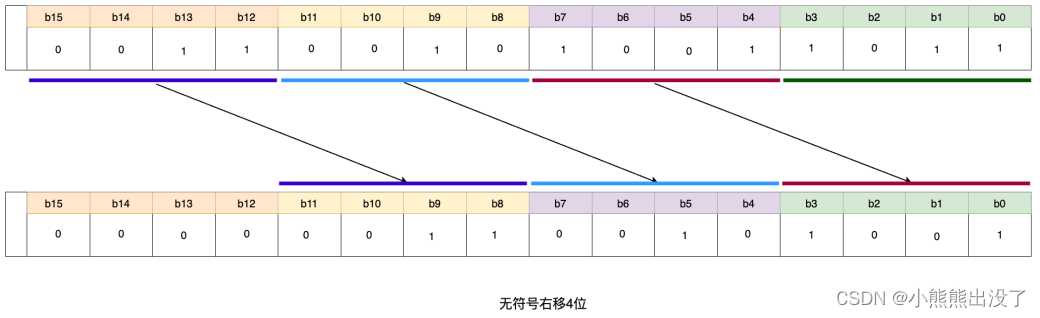
功能:对操作数进⾏按位右移,右边移出位不做处理,左边空位⾃动补 0。
语法:指令可以将输⼊ IN 中的数据右移 n 位,输出结果赋值⾄ OUT,⼆进制数右移⼀位相当于将原数除以 2。
- 如果 n ⼤于数据类型宽度, BYTE, Word 和 DWORD 值将填为零。
- 如果使⽤带符号数据类型,则算术移位将按最⾼位补充数。
其⽂本化语⾔语法格式如下所示:
OUT:= SHR (IN, n) ; // IN 需要位移的数据, n需要右移的位数
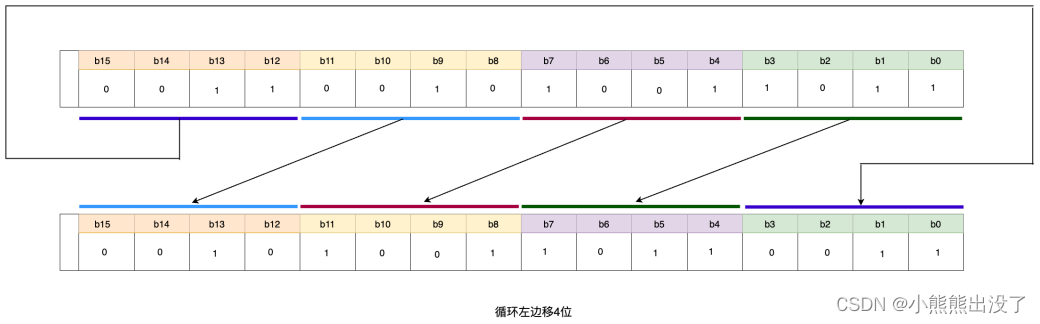
循环左移 ROL
功能:对操作数进⾏按位循环左移,左边移出的位直接补充到右边的最低位。
语法:允许的数据类型:BYTE、WORD、DWORD,使⽤该指令可以将输⼊ IN 中的全部内容循环的逐位左移,空出的位⽤移出位的信号状态填充。
其⽂本化语⾔语法格式如下所示,
OUT:= ROL (IN, n) ;//输⼊参数 n 提供数值表示循环移动的位数,OUT 是循环移位的操作结果。
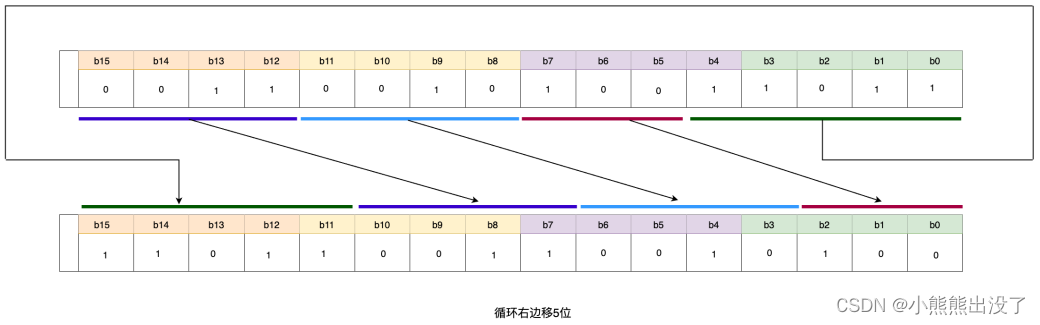
循环右移 ROR
功能:对操作数进⾏按位循环右移,右边移出的位直接补充到左边最⾼位。
语法:允许的数据类型:BYTE、WORD、DWORD。
使⽤该指令可以将输⼊ IN 中的全部内容循环的逐位右移,空出的位⽤移出位的信号状态填充。
其⽂本化语⾔语法格式如下所示
OUT: = ROR (IN, n) ;//输⼊参数 n 提供数值表示循环移动的位数,OUT 是循环移位的操作结果
数学运算指令
绝对值 ABS
功能:这个函数指令是⽤来计算⼀个数的绝对值,与正负号数符号没有关系。
语法:绝对值运算指令⽀持如下的变量类型,BYTE、WORD、DWORD、SINT、USINT、INT、UINT、DINT、UDINT、REAL、LREAL 和常数。
其⽂本化语⾔语法格式如下所示
OUT := ABS (IN); // 求绝对值
//
Result := ABS(-1);// Result为-1
平⽅根 SQRT
功能:⾮负实数的平⽅根。
语法:输⼊变量 IN 可以是 BYTE、WORD、DWORD、SINT、USINT、INT、UINT、DINT、UDINT、REAL、LREAL 和常数,但输出必须是 REAL 或 LREAL 类型。
其⽂本化语⾔语法格式如下所示
OUT := SQRT(IN);
// 实例
Res := SQRT(64); // Res结果为8
指数函数 EXP
功能:返回 e(⾃然对数的底)的幂次⽅,e 是⼀个常数为 2.71828 的数。
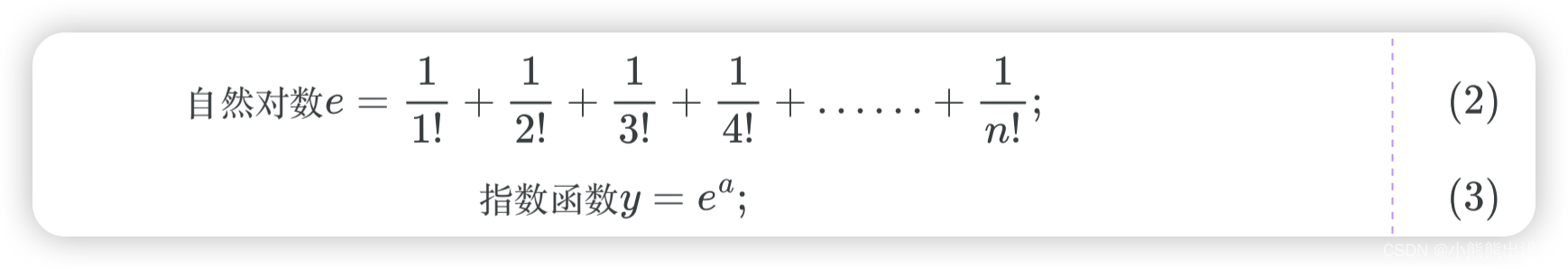
语法:输⼊变量 IN 可以是 BYTE、WORD、DWORD、SINT、USINT、INT、UINT、DINT、UDINT、REAL、LREAL 和常数,但输出必须是 REAL 或 LREAL 类型。
其⽂本化语⾔语法格式如下所示
OUT := EXP(IN);
// 实例
Res := EXP(2); // Res结果为 e^2 = 7.38905609893065
⾃然对数 LN
功能:返回⼀个数的⾃然对数。⾃然对数以常数项 e (2.71828182845904) 为底。

语法:输⼊变量 IN 可以是 BYTE、WORD、DWORD、SINT、USINT、INT、UINT、DINT、UDINT、REAL、LREAL 和常数,但输出必须是 REAL 或 LREAL 类型。
其⽂本化语⾔语法格式如下所示
OUT := LN (IN);
// 示例
Res := LN(16); // Res结果为2.7726 相当于对数函数的中的a=16
10 为底的对数 LOG
功能:返回底为 10 数的对数。

语法:输⼊变量 IN 可以是 BYTE、WORD、DWORD、SINT、USINT、INT、UINT、DINT、UDINT、REAL、LREAL 和常数,但输出必须是 REAL 或 LREAL 类型。
其⽂本化语⾔语法格式如下所示
OUT := LOG(IN);
// 示例
Res := LOG(30); // Res结果为1.4771 相当于对数函数的中的a=30
三⻆函数指令
语法:输⼊变量 IN 可以是 BYTE、WORD、DWORD、SINT、USINT、INT、UINT、DINT、UDINT、REAL、LREAL 和常数,但输出必须是 REAL 或 LREAL 类型。
其⽂本化语⾔语法格式如下所示
OUT := SIN(IN); // 正弦函数 SIN
OUT := COS(IN); // 余弦函数 COS
OUT := TAN(IN); // 正切函数 TAN
OUT := ASIN(IN); // 反正弦函数 ASIN
OUT := ACOS(IN); // 反余弦函数ACOS
OUT := ATAN(IN); // 反正切函数 ATAN
地址运算指令
SIZEOF 指令
功能:执⾏这个功能以确定给出的数据类型所需要的字节数量。
简单的说其作⽤就是返回⼀个对象或者类型所占的内存字节数。
语法:SIZEOF 的返回值的是⼀个⽆符号值,类型的返回值将会被⽤于查找变量 IN0 的⼤⼩,OUT 输出值的单位为字节,IN0 可以为任何数据类型。其⽂本化语⾔语法格式如下所示。
返回值类型:是隐式数据类型,它会根据实际数据值来决定。
| SIZEOF 的返回值 X | 隐式数据类型 |
|---|---|
| 0 <= size of x < 256 | USINT |
| 256 <= size of x < 65536 | UINT |
| 65536 <= size of x < 4294967296 | UDINT |
| 4294967296 <= size of x | ULINT |
其⽂本化语⾔语法格式如下所示
OUT := SIZEOF(IN0);
// 示例
Btn : BOOL;
Led : ARRAY[0..9] OF INT;
RES1 := SIZEOF(Btn); // 返回1,表示BOOL类型占⽤1个字节的空间
RES2 := SIZEOF(Led); // 返回2*10=20,表示Led变量占⽤20个字节的空间(⼀个int占2个字节)
地址操作符 ADR
功能:取得输⼊变量的内存地址,并输出。该地址可以在程序内当作指针使⽤,也可以作为指针传递给函数。
语法:ADR 操作符其返回值为⼀个 DWORD 的地址变量,IN0 可以为任何数据类型。
返回值:ADR 的返回值仅是变量的内存地址。该内存地址可以存放的数据⻓度为 1 个 BYTE。
其⽂本化语⾔语法格式如下所示
OUT :=ADR(IN0);
位地址操作符 BITADR
功能:返回分配变量的位地址信息偏移量。 语法:BITADR 操作符其返回值为⼀个 DWORD 的地址变量,IN0 可以为任何数据类型。
其⽂本化语⾔语法格式如下所示
OUT :=BITADR(IN0);
ADR 的返回值仅是变量的内存地址。该内存地址可以存放的数据⻓度为 1 个 BYTE。可以通过内容操作符“^” 提取对应地址中的内容注意偏移值取决于选项类型地址是否可以从⽬标系统中获得。
数据类型转换指令
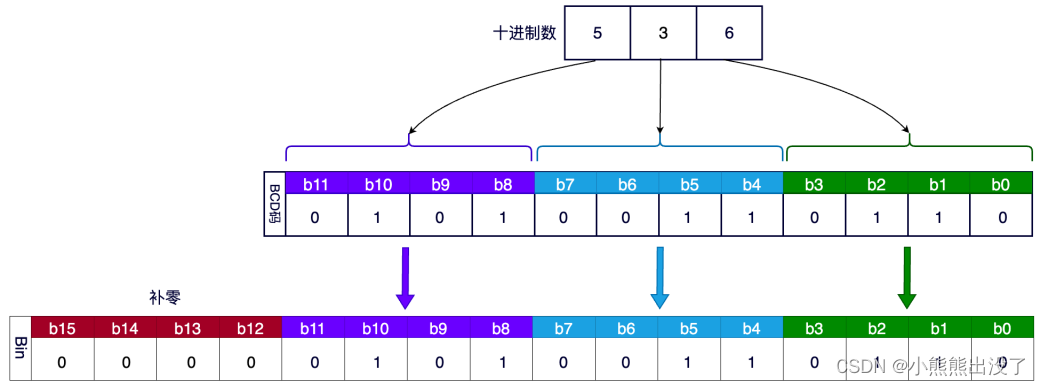
BCD 码
BCD(Binary Coded Decimal)即⽤ 4 位 2 进制数来并列表示 10 进制数中各个位数的值
BCD_TO_X
| 指令 | 说明 |
|---|---|
| BCD_TO_BYTE | BCD 转 BYTE |
| BCD_TO_DWORD | BCD 转 DWORD |
| BCD_TO_INT | BCD转INT |
| BCD_TO_WORD | BCD 转 WORD |
X_TO_BCD
| 指令 | 说明 |
|---|---|
| BYTE _TO_BCD | BYTE 转 BCD |
| DWORD_TO_BCD | DWORD 转 BCD |
| INT_TO_BCD | INT转 BCD |
| WORD_TO_BCD | WORD 转 BCD |
BOOL_TO_ 布尔类型转换
输出为 BOOL 时:输⼊不等于 0 时,输出为 TRUE。输⼊等于 0 时,输出为 FALSE。
输出为 TIME 或 TOD 时:输⼊将以毫秒值进⾏转换。
输出为 DATE 或 DT 时 :输⼊将以秒值进⾏转换。
| 指令 | 结果 |
|---|---|
| i:=BOOL_TO_INT(TRUE) | 1 |
| str:=BOOL_TO_STRING(TRUE) | ‘TRUE’ |
| t:=BOOL_TO_TIME(TRUE) | T#1ms |
| tof:=BOOL_TO_TOD(TRUE) | TOD#00:00:00.001 |
| dat:=BOOL_TO_DATE(FALSE) | D#1970 |
| dandt:=BOOL_TO_DT(TRUE) | DT#1970-01-01-00:00:01 |
BYTE_TO_ 字节类型转换
输出为数字类型时 :如果输⼊是 TRUE,则输出为 1。如果输⼊是 FALSE,则输出为 0。
输出为字符串类型时 :如果输⼊是 TRUE,则输出字符串’TRUE’。如果输⼊是 FALSE,则输出为字符串’FALSE’。
| 指令 | 结果 |
|---|---|
| bVarbool:= BYTE_TO_BOOL(255) | TRUE |
| iVarint:= BYTE_TO_INT(255) | 255 |
| tVartime:= BYTE_TO_TIME(255) | T#255ms |
| dtVardt:= BYTE_TO_DT(255) | DT#1970-01-01-00:04:15 |
| rVarreal:= BYTE_TO_REAL(255) | 255 |
| stVarstring:=BYTE_TO_STRING(255) | ‘255’ |
IntegralData_TO_整数类型转换
输出为 BOOL 时:输⼊不等于 0 时,输出为 TRUE。输⼊等于 0 时,输出为 FALSE。
输出为 TIME 或 TOD 时:输⼊将以毫秒值进⾏转换。
输出为 DATE 或 DT 时 :输⼊将以秒值进⾏转换。
| 指令 | 结果 |
|---|---|
| iVarsint:=WORD_TO_USINT(4836) | 255 |
| tVartime:=WORD_TO_TIME(4836) | T#4s863ms |
| dtVardt:= WORD_TO_DT(4836) | DT#1970-01-01-01:21:03 |
REAL_TO_实数类型转换
输出为 BOOL 时:输⼊不等于 0 时,输出为 TRUE。输⼊等于 0 时,输出为 FALSE。
输出为 TIME 或 TOD 时:输⼊将以毫秒值进⾏转换。
输出为 DATE 或 DT 时 :输⼊将以秒值进⾏转换。
REAL_TO_INT 四舍五⼊
| 指令 | 结果 |
|---|---|
| iVarsint:= REAL_TO_INT(1.5) | 2 |
TIME_TO_ 时间类型转换
| 指令 | 结果 |
|---|---|
| sVarstring:= TIME_TO_STRING(t#12ms) | ‘T#12ms’ |
| dVardword:= TIME_TO_DWORD(t#5m) | 300000 |
DATE_TO_ ⽇期类型转换指令
| 指令 | 结果 |
|---|---|
| sVarstring:= DATE_TO_STRING(D#1970-01-01) | ‘D#1970-01-01’ |
| iVarint:= DATE_TO_INT(D#1970-01-01) | 29952 |
DT_TO_⽇期时间类型转换
| 指令 | 结果 |
|---|---|
| byVarbyte:= DT_TO_BYTE(DT#1970-01-15-05:05:05) | 129 |
| sVarstr:= DT_TO_ STRING (DT#1998-02-13-05:05:06) | ‘DT#1998- 02-13-05:05:06’ |
TOD_TO_ 时间类型转换
| 指令 | 结果 |
|---|---|
| iVarusint:=TOD_TO_USINT(TOD#10:11:40) | 96 |
| tVartime:=TOD_TO_TIME(TOD#10:11:40) | T#611m40s0ms |
| dtVardt:=TOD_TO_DT(TOD#10:11:40) | DT#1970-01- 01-10:11:40 |
| rVarreal:=TOD_TO_REAL(TOD#10:11:40) | 3.67e+007 |
取整 TRUNC
功能:将数据截去⼩数部分,只保留整数部分
| 指令 | 结果 |
|---|---|
| iVarint:=TRUNC(1.7) | 1 |
| iVarint:=TRUNC(-1.2) | -1 |
通讯⽅式
EtherCAT配置
EtherCAT是⼀种基于以太⽹的开放式⼯业现场技术,具有通信刷新周期短、同步抖动⼩、硬件成本低等特点,⽀持线型、树型、星型以及混合⽹络拓扑结构。EtherCAT从站必须使⽤专⽤的通信控制芯⽚(ESC),EtherCAT主站可以使⽤标准的以太⽹控制器。
EtherCAT 出⾊的性能使得系统配置时对 ⽹络调试的需求得以降低。⾼带宽可以将 其他的 TCP/IP 与控制数据同时传输。然⽽, EtherCAT 并不是基于 TCP/IP 的,因此⽆需使⽤ MAC 地址或 IP 地址,更不需要 IT 专家配 置交换机或路由器。
EtherCAT 将其报⽂嵌⼊到标准的以太⽹数据帧中(形成 EtherCAT 数据帧)。设备通过 帧类型 0x88A4 识别 EtherCAT 数据帧。
EtherCAT 采⽤分布式时钟(DC)的⽅式 同步节点。各个节点的时钟校准完全基于硬件。第⼀个具有分布时钟功能的从站设备的时间被周 期性地发布给系统中的其他设备。采⽤这样的机制,其它从站时钟可以根据参考时钟精确 地进⾏调整。整个系统的抖动远⼩于 1µs。
EtherCAT运⾏机制
EtherCAT 的关键⼯作原理在于其节点对以太⽹数据帧的处理:在数据帧向下游传输 的过程中,每个节点读取寻址到该节点的数据,并将它的数据写⼊数据帧。这种传输⽅ 式提⾼了带宽利⽤率,使得每个周期通常⽤ ⼀个数据帧就⾜以实现整个系统的数据刷 新,同时,⽹络⽆需使⽤交换机或集线器
EtherCAT是⽤于过程数据的优化协议,凭借特殊的以太⽹类型,它可以在以太⽹帧内直接传送。EtherCAT帧可包括⼏个EtherCAT报⽂,每个报⽂都服务于⼀块逻辑过程映像区的特定内存区域,该区域最⼤可达4GB字节。数据顺序不依赖于⽹络中以太⽹端⼦的物理顺序,可任意编址。从站之间的⼴播、多播和通讯均得以实现
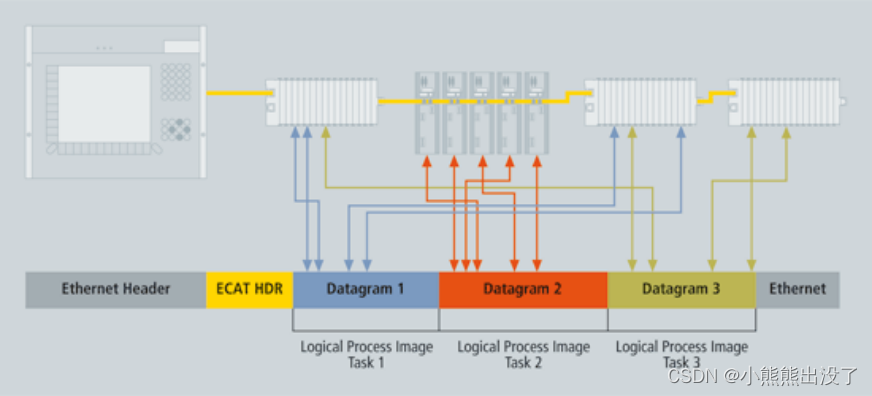
⽹络拓扑
⼀个 EtherCAT ⽹ 络最多可⽀持 65,535 个设备,⽽不受在拓扑 结构中放置位置的限制:线型、总线型、树 型、星型——或任意组合。快速以太⽹物理层 允许两个设备最⼤间距 100 ⽶(330 英尺), 采⽤光纤则设备间距可以更远。EtherCAT 还 可以提供更⾼的拓扑灵性,如设备的热连接、热插拔,以及通过环⽹实现的线缆冗余。
EIA-485(RS-485)
EIA-485(过去叫做RS-485或者RS485[1])是⾪属于OSI模型物理层的电⽓特性规定为2线、半双⼯、平衡传输线多点通信的标准。是由电信⾏业协会(TIA)及电⼦⼯业联盟(EIA)联合发布的标准。实现此标准的数位通讯⽹可以在有电⼦杂讯的环境下进⾏⻓距离有效率的通讯。在线性多点总线的组态下,可以在⼀个⽹路上有多个接收器。因此适⽤在⼯业环境中。
EIA⼀开始将RS(Recommended Standard)做为标准的字⾸,不过后来为了便于识别标准的来源,已将RS改为EIA/TIA[2]。电⼦⼯业联盟(EIA)已结束运作,此标准⽬前是电信⾏业协会(TIA)维护,名称为TIA-485,但⼯程师及应⽤指南仍继续⽤RS-485来称呼此⼀协定。
EIA-485的电⽓特性和RS-232不⼀样。EIA-485使⽤缆线两端的电压差值来表示传递信号,不同的电压差分别标识为逻辑1及逻辑0。两端的电压差最⼩为0.2V以上时有效,任何不⼤于12V或者不⼩于-7V的差值对接受端都被认为是正确的。
EIA-485仅仅规定了接受端和发送端的电⽓特性。它没有规定或推荐任何数据协议。EIA-485可以应⽤于配置便宜的区域⽹和采⽤单机发送,多机接受通信链接,使⽤和EIA-422类似的差动双绞线。它提供⾼速的数据通信速率(10m时35Mbit/s;1200m时100kbit/s)。有⼀个有关EIA-485的经验法则,是⽐特率乘以线⻓(单位为⽶)的乘积⽆法超过108,因此 50 m的在线速度不会超过2 Mbit/s[3],在特定条件下,其数据通信速率可以到64 Mbit/s.。
EIA-485和EIA-422⼀样使⽤双绞线进⾏⾼电压差分平衡传输,它可以进⾏⼤⾯积⻓距离传输(超过4000英尺,1200⽶)。和EIA-422相对照的是,EIA-422采⽤不可转换的单发送端,EIA-485的发送端需要设置为发送模式,这使得EIA-485可以使⽤双线模式实现真正的多点双向通信。
EIA-485推荐使⽤在点对点⽹络中,线型、总线型,不能是星型、环型⽹络。假如必须要使⽤星型⽹络,可以配合特殊的RS-485 star/hub中继器,可以在多个⽹络中双向的监听资料,并且将资料再发送到其他的⽹络上。
典型的终接电阻以及偏置电阻线路。EIA-485标准没有标示终接电阻以及偏置电阻的阻值理想情况下EIA-485需要2 个终接电阻,其阻值要求等于传输电缆的特性阻抗(⼀般⽽⾔,双绞线会是120 ohms)。没有特性阻抗的话,当所有的设备都静⽌或者没有能量的时候就会产⽣噪声,⽽且线移需要双端的电压差。没有终接电阻的话,会使得较快速的发送端产⽣多个数据信号的边缘,这其中的⼀些是不正确的。之所以不能使⽤星型或者环型的拓扑结构是由于这些结构有不必要的反映,过低或者过⾼的终接电阻可以产⽣电磁⼲扰(EMI)。有时在⼀组⽹络在线。会加上上拉及接地电阻(偏置电阻),若通信在线没有任何设备时,上⾯的资料可以有失效安全的机制。这样可以让⽹络在线有固定的偏置电压,节点较不容易在没有任何节点发送资料时,将在线的噪声解读成实际的资料。若没有偏置电阻,通信线处于浮接的状态,在所有节点都未发送资料或未供电时,最容易受到噪声的影响。
Modbus
Modbus是⼀种串⾏通信协议,是Modicon公司(现在的施耐德电⽓ Schneider Electric)于1979年为使⽤可编程逻辑控制器(PLC)通信⽽发表。Modbus已经成为⼯业领域通信协议事实上的业界标准,并且现在是⼯业电⼦设备之间常⽤的连接⽅式Modbus允许多个 (⼤约240个) 设备连接在同⼀个⽹络上进⾏通信协议
Modbus协议⽬前存在⽤于串⼝、以太⽹以及其他⽀持互联⽹协议的⽹络的版本。⼤多数Modbus设备通信通过串⼝EIA-485物理层进⾏。
对于串⾏连接,存在两个变种,它们在数值数据表示不同和协议细节上略有不同。Modbus RTU是⼀种紧凑的,采⽤⼆进制表示数据的⽅式,Modbus ASCII是⼀种⼈类可读的,冗⻓的表示⽅式。这两个变种都使⽤串⾏通信(serial communication)⽅式。RTU格式后续的命令/数据带有循环冗余校验的校验和,⽽ASCII格式采⽤纵向冗余校验的校验和。被配置为RTU变种的节点不会和设置为ASCII变种的节点通信,反之亦然。
对于通过TCP/IP(例如以太⽹)的连接,存在多个Modbus/TCP变种,这种⽅式不需要校验和计算。
对于所有的这三种通信协议在数据模型和功能调⽤上都是相同的,只有封装⽅式是不同的。
Modbus有⼀个扩展版本Modbus Plus(Modbus+或者MB+),不过此协议是Modicon专有的,和Modbus不同。它需要⼀个专⻔的协处理器来处理类似HDLC的⾼速令牌旋转。它使⽤1Mbit/s的双绞线,并且每个节点都有转换隔离设备,是⼀种采⽤转换/边缘触发⽽不是电压/⽔平触发的设备。连接Modbus Plus到计算机需要特别的接⼝,通常是⽀持ISA(SA85),PCI或者PCMCIA总线的板卡。

















 5006
5006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









