








VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
一、介绍
在2012 年AlexNet 夺得ILSVRC 2012 图像分类挑战赛的冠军之后,CNN 便在大规模图像、视频识别中发挥了巨大的作用。VGG 网络在借鉴前人的基础上,研究了卷积网络深度和精度的关系,使用了3*3 小卷积核进行了实验,使用了16-19 层的卷积网络,并在ILSVRC 2014 比赛中获得定位冠军和分类亚军,并且开源了模型。
VGG 借鉴了一些前人的研究,将一些方法用在了自身的网络设计中。ILSVRC-2013分类冠军方法ZFNet,是对AlexNet改进,借鉴了其思想采用小卷积核方法;ILSVRC-2013定位冠军,OverFeat集分类、定位和检测于一体的卷积网络,使用了全卷积代替了全连接,实现高效的稠密(Dense)预测,VGG 在测试技巧中用到了Dense 预测的方法;借鉴了NIN网络,尝试了1*1卷积核提升模型精度
二、网络结构
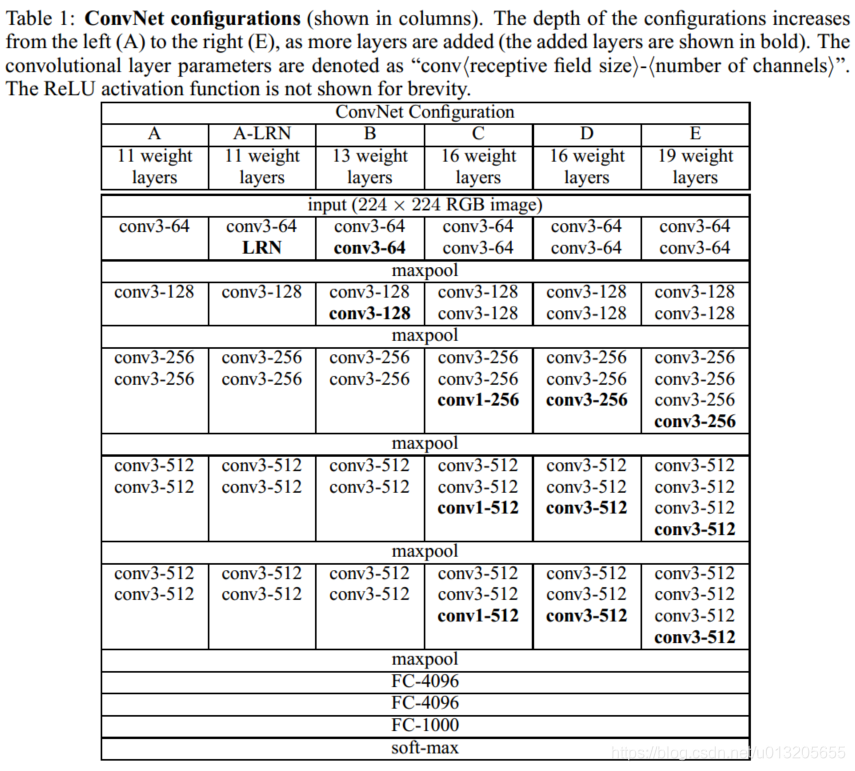
VGG网络的结构十分的清晰,论文中的表能清楚了看到6中网络结构的变化。图中conv3-64 代表卷积核大小为3*3,卷积核数量为64,conv1-256 代表卷积核大小为1*1,卷积核数量为256,依次类推。
可以看出6个网络都包含5个卷积block, 但每个block 中包含的卷积层不一样;都有5个maxpool,最后一个maxpool后,特征图通道数翻倍直至512;都是通过3个FC层进行分类输出;maxpool之间采用多个卷积层堆叠,对特征进行提取和抽象;分类之前特征图的分辨率都由224*224 变为了7*7
A模型:11层卷积
A-LRN:基于A增加一个LRN
B:第1,2个block中增加1个卷积3*3卷积
C:第3, 4, 5个block分别增加1个1*1卷积
D:第3, 4, 5个block的1*1卷积替换为3*3,
E:第3, 4, 5个block再分别增加1个3*3卷积
参数量如下图所示,可以看到VGG 19 的参数量并没有显著增加,主要是因为全连接层没有改变,卷积层的增加并不会显著增加参数量

在VGG 网络结构中堆叠的使用了3*3卷积,这样做的优点:
1.增大感受野,因为2个3*3堆叠等价于1个5*5,3个3*3堆叠等价于1个7*7
2.多个卷积堆叠,会增加非线性激活函数,增加特征抽象能力
3.小卷积核会减少训练参数
假设输入和输出通道数均为C,忽略bias 项,依据多通道卷积中卷积核权重计算公式:W =C0* Ci*Kh* Kw,1个7*7卷积时参数为:7*7*C*C = 49 *C*C;3个3*3卷积堆叠时参数为:3*(3*3)*C*C = 27 *C*C; 参数减少了: (49-27)/49 = 44.9%,总体会降低了很多参数量
在VGG 网络结构中堆叠的使用了1*1卷积,这样做的优点:增加非线性激活函数,提升模型效果
三、训练和测试技巧
1.训练技巧
训练参数设置
Batch size 256,动量是0.9,使用L2 正则化,学习率为0.01,当验证集的准确率不再下降时降低学习率,训练了74 epoch。
初始化
深层的网络用训练好的浅层网络的参数初始化,其中前四层和最后的全连接层使用A 模型参数初始化,中间层随机初始化,Biases 都初始化为0。
we initialised the first four convolutional layers and the last three fullyconnected layers with the layers of net A (the intermediate layers were initialised randomly)
同时作者提到Xavier 初始化的方法值得借鉴。
数据增强
针对位置
对训练图片尺寸设计,需要对训练图片进行缩放,然后裁剪出一个224*224区域
1.将S 定于为图片缩放之后的最小边,将训练图片按比例缩放图片至最小边为S
S >= 224
图片缩放的S 有两种定义方式:第一种是固定大小格式,使用256和384,并且384的网络用256 的参数初始化进行训练加速,也是单尺度模型;第二种是在[256,512] 之间随机的取值,是多尺度的,多尺度模型使用S = 384 模型的参数初始化进行训练加速
2.在缩放之后的训练图片中随机位置裁剪出224*224区域
3.随机进行水平翻转
2.测试技巧
测试图片需要等比例缩放至最短边为Q,测试图片中Q 的定义如下:
方法1 当S为固定值时:
Q = [S-32, S, S+32]
即S = 256 时,Q = 224,256,288
即S = 384 时,Q = 352,384,416
方法2 当S为[256,512]随机值时:
Q = (S_min, 0.5*(S_min + S_max), S_max)
此时Q 为固定值:Q = 256,384,512
测试时设置三个Q,对图片进行预测,取平均
测试方法
Dense 测试:稠密测试
稠密测试是将原有的3个FC层转换为卷积操作,第一个FC 层变为7*7卷积,后两个FC 层变为1*1卷积,这样就变为全卷积网络,可以实现任意尺寸图片输入。
测试图片先经过全卷积网络得到 N*N*1000 特征图,然后在通道维度上求和(sum-pooled)计算平均值,得到1*1000 输出向量,最后还会对图片进行水平翻转,得到两个图片的输出结果平均值
Multi-crop 测试:多尺度测试
在全连接网络的基础上,借鉴AlexNet与GoogLeNet,对图片进行Multi-crop多尺度裁剪,1张图测试,缩放至3种尺寸,并翻转,然后每种尺寸裁剪出50张图片;50 = 5*5*2;最后有3*50=150 张图片
作者提到他们在当时使用了C++ Caffe 工具包来实现网络,进行训练和测试
四、实验分析
作者做了5种类型的测试
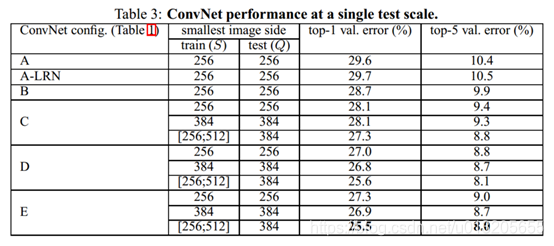
1.单尺度评估 Single scale
如图所示,使用三种不同的S值和对应的Q 值进行测试,S为固定值256,384,Q = S;S为[256,512]随机值,Q = 0.5(S_min + S_max)
实验结论:
>误差随深度加深而降低,当模型到达19层时,误差饱和,不再下降
>增加1*1的卷积可以提升模型性能
>训练时加入尺度扰动(scale jittering),有助于性能提升
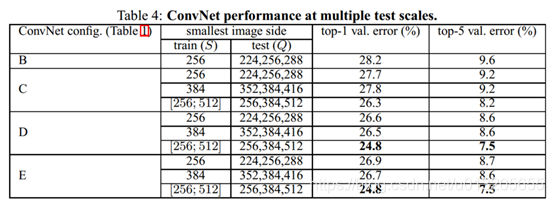
2.多尺度评估 Multi-scale
将S 设为3种值,每一种S 值对应3个不同值,如图
结果显示测试时采用Scale jittering有助于性能提升
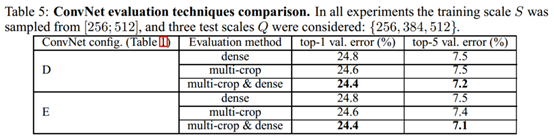
3.测试阶段的多裁剪 Multi-crope
在测试阶段,在multi-scale 基础上加入multi-crope 进行裁剪,使用等步长的滑动224*224的窗口进行裁剪,在尺度为Q的图像上裁剪5*5=25张图片,然后再进行水平翻转,得到50张图片,结合三个Q值,一张图片得到150张图片输入到模型中
实验结论显示:mulit-crop优于dense;multi-crop结合dense,可形成互补,达到最优结果
4.模型融合 Convnet fusion
ILSVRC 比赛中模型融合已经是常用方法,作者在ILSVRC中提交的模型为7个模型融合,比赛结束后继续采用最优的两个模型D/[256, 512]/256,384, 512, E/[256, 512]/256,384, 512,结合multi-crop和dense,得到最优结果
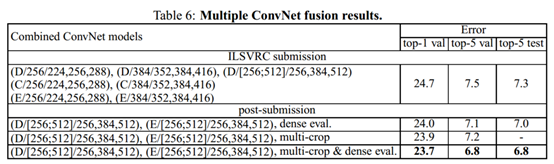
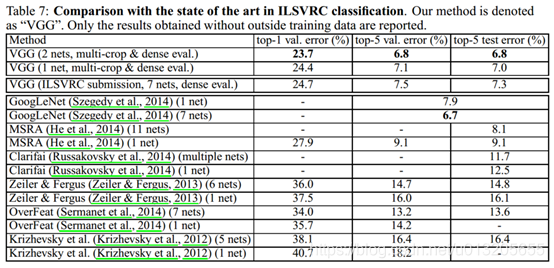
作者还对比了其他的模型,如图:
五、Summary
-
模型更深能提高更好的性能,后来出现了更深的模型
-
采用小卷积核,获得高精度
-
采用多尺度及稠密预测,获得高精度
-
1*1卷积可认为是线性变换,同时增加非线性层;1*1 的卷积核能增加模型的非线性映射
-
填充大小准则:保持卷积后特征图分辨率不变
-
LRN对精度无提升
-
Xavier初始化可达较好效果
-
S远大于224,图片可能仅包含物体的一部分
-
大尺度模型采用小尺度模型初始化,可加快收敛
-
物体尺寸不一,因此采用多尺度训练,可以提高精度
-
multi crop 存在重复计算,因而低效;multi crop可看成dense的补充,因为它们边界处理有所不同
-
小而深的卷积网络优于大而浅的卷积网络
-
尺度扰动对训练和测试阶段有帮助
-
使用的训练技巧和测试技巧,可以在比赛中涨点,实际工程中可以借鉴一些技巧
-
作者提到他们在当时开始使用了C++ Caffe 工具包来实现网络了,现在都在使用pytoch 框架,可以对比下两个框架区别
-
可以通过pytorch 复现论文中的测试方法

















 2683
2683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









