







Summary of
High-Speed Tracking with Kernelized Correlation Filters
João F. Henriques, Rui Caseiro, Pedro Martins, and Jorge Batista
Summarize by Wenju Huang
Abstract
With the theory of circulant matrices, this paper present a classification trained with all patches form a single image, which can reduce the redundancy of the random sample in the normal classification. What’s more, the characteristic is mapped to high-dimensional space using the kernel trick. According to the kinds of the kernel function and the dimensionality of input futures, we get the different filters, such as MOSSE(linear kernel, one-dimensional future), KCF(non-linear kernel), and DCK(linear kernel, high-dimensional future).
1. Pre-knowledge
1) Regularized Least-Squares Classification (Ridge Regression)[1]
Compared with the ordinary least squares regression, the RLSC considers the sensitivity of the regression parameters w. The goal of training is to find a function f(z) = wTz that minimizes the squared error over samples xi and their regression targets yi.
the lamda is a trades off parameter between the the empirical risk and ||W||2.
2) The theory of Circulant matrices[2]
In linear algebra, a circulant matrix is a special kind of Toeplitz matrix where each row vector is rotated one element to the right relative to the preceding row vector.
An n*n circulant matrices C takes the form
Given a matrix equation
Cx = b
where C is a circulant square matrix of size n×n we can write the equation as the circular convolution
c*x = b
where c is the first column of C, and the vectors c, x and b are cyclically extended in each direction.
3) The kernel trick
Features which is linearly non-separable in the low-dimension space, will be linearly separated when map them to the high-dimension space. However, When operation directly in the high-dimension space, we will encounter the curse of dimensionality problem. Fortunately, the kernel trick can solve this problem. According the kernel trick, we have:
K(x,z) =<Φ(x),Φ(z) >
The above function means that we can use a suitable kernel function to get the product of two features in the the high-dimension space and don’t have to know the really high-dimension space. Note that different kernel function relative to the different high-dimension space, so we have to choose the kernel function according our feature need. Here some common kernel function.
Epanechnikov Kernel:

Uniform Kernel:
Normal Kernel:
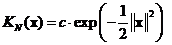

2. Major formulation and their inference
The finally output function is:
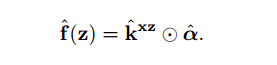
where f(z) is a vector, containing the output for all cyclic shifts of z., kxz is the kernel values and α is a learned coefficient.
kxz take the form:

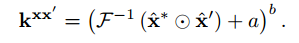
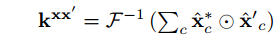
α can be obtained by
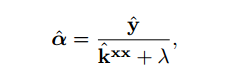
where lambda is a regularization parameter, and kxx is the kernel values like we introduce above. In fact, there is only the above three equations in our final algorithm. lambda is figured form the Regularized Least-Squares Classification with the circulant matrices and kernel trick.
[1]R. Rifkin, G. Yeo, and T. Poggio, “Regularized least-squares classification,”Nato Science Series Sub Series III Computer and Systems Sciences, vol. 190, pp. 131–154, 2003.
[2]wiki https://en.wikipedia.org/wiki/Circulant_matrix















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









