







一、问题描述
在hdfs上看到有个输出目录有_temporary目录,但任务实际已经结束了。
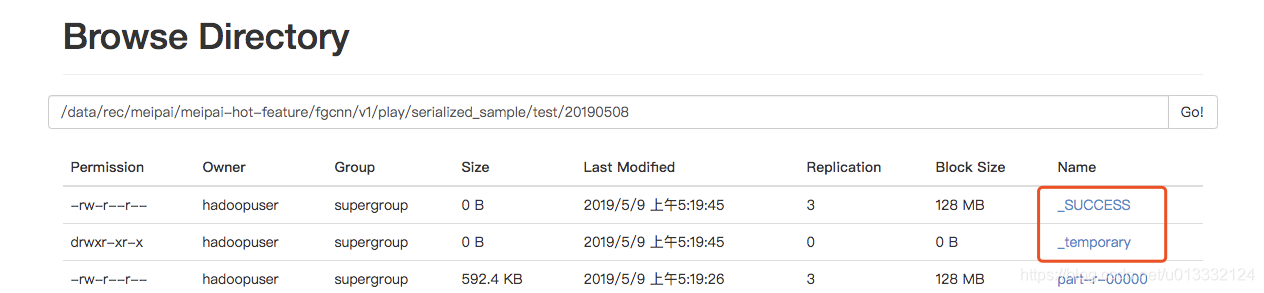
有_SUCCESS文件表示这个任务已经结束了。
二、问题定位
Spark 输出数据到 HDFS 时,需要解决如下问题:
- 由于多个 Task 同时写数据到 HDFS,如何保证要么所有 Task 写的所有文件要么同时对外可见,要么同时对外不可见,即保证数据一致性
- 同一 Task 可能因为 Speculation 而存在两个完全相同的 Task 实例写相同的数据到 HDFS中,如何保证只有一个 commit 成功
- 对于大 Job(如具有几万甚至几十万 Task),如何高效管理所有文件
所以spark任务在输出时不会立即输出到目标目录,而且在目标目录下创建一个_temporary文件用于输出数据,每个task都有自己单独的输出目录。等最终job结束后,才真正的将_temporary目录下的文件move到目标目录下,并且删除_temporary目录。
通过查看spark代码我们发现,spark判断job结束的方式是每个partiton的task都执行结束,而不管speculation的task是否已经结束。比如有个task因为执行慢开启了推测执行,那么它就会有两个attempt,这时只要有一个attempt运行成功,那么就判定为这个partition的task运行成功了。所以在job运行成功时,可能还有一些speculation还在执行。(虽然task运行成功后,会去主动kill其他的attempt,但是这是一个异步的过程,可能刚好在kill的过程中job已经结束了)
job结束后会去删除_temporary目录,但是因为还有几个speculation task还在运行,这几个speculation task可能又创建了_temporary作为输出。这样,我们就观察到这个目录运行结束了还有_temporary目录存在。
通过相关日志,我们也可以判断确实是这么一回事。
通过_temporary目录下的文件,我们可以判断出是task 20和task682出现了问题:
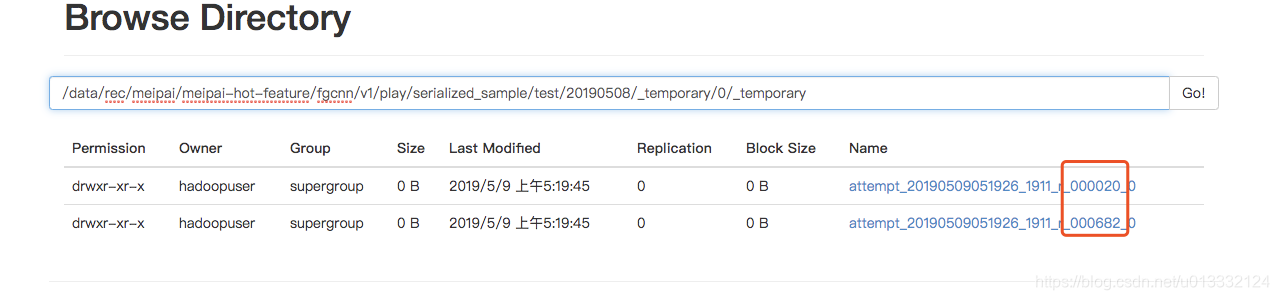
因此我们可以去ApplicationMaster中搜索相关日志:

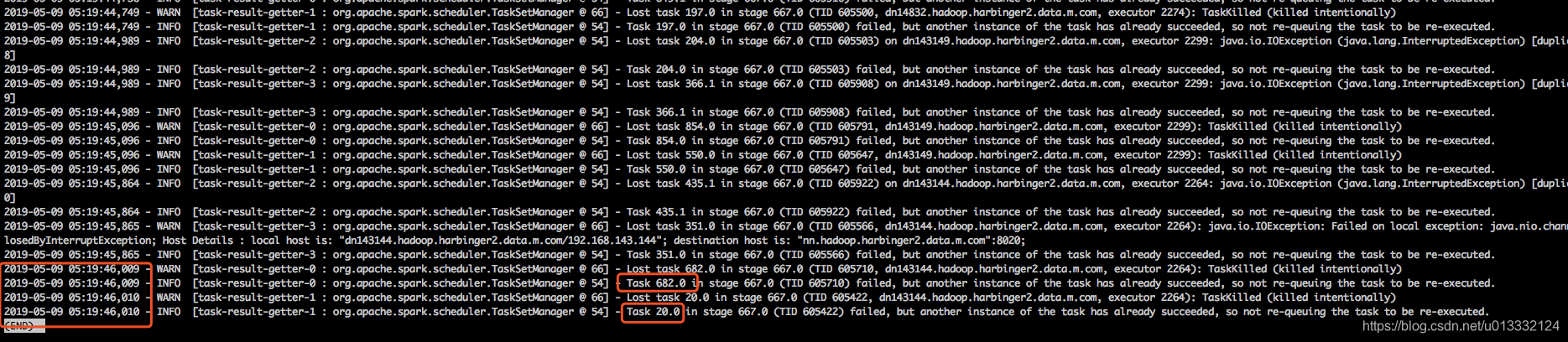
上面那张图说明stage 667在05:19:44,717的时候已经运行结束了,但是在这之后还陆陆续续有task上报结果上来,其中最晚的两个就是task 20和task 682。倒数第三个上报信息的task是task 351,这个task没有出现在_temporary,说明_temporary目录应该是在05:19:45,865左右删除的。之后task 20和task 682又创建了这个目录。
三、driver kill task的时间
我们以task 20来分析。
通过日志观察,task 20在05:19:43,546就已经运行成功了,并且主动去kill了task 20 attempt 0的那个运行记录。
2019-05-09 05:19:43,546 - INFO [task-result-getter-3 : org.apache.spark.scheduler.TaskSetManager @ 54] - Killing attempt 0 for task 20.0 in stage 667.0 (TID 605422) on dn143144.hadoop.harbinger2.data.m.com as the attempt 1 succeeded on dn143115.hadoop.harbinger2.data.m.c
om
2019-05-09 05:19:43,546 - INFO [task-result-getter-3 : org.apache.spark.scheduler.TaskSetManager @ 54] - Finished task 20.1 in stage 667.0 (TID 605893) in 233 ms on dn143115.hadoop.harbinger2.data.m.com (executor 2161) (951/1000)
task 20.0到05:19:46,010才真正上报了fail的结果上来。期间经过了2.5s。
看了下executor的日志,发现05:19:43,548 就收到了kill的请求,整个请求传输只用了2ms
2019-05-09 05:19:43,548 - INFO [dispatcher-event-loop-10 : org.apache.spark.executor.Executor @ 54] - Executor is trying to kill task 20.0 in stage 667.0 (TID 605422)
在05:19:46,006才真正kill了task 20.0。
2019-05-09 05:19:46,006 - INFO [Executor task launch worker-0 : org.apache.spark.executor.Executor @ 54] - Executor killed task 20.0 in stage 667.0 (TID 605422)
看了下kill task的相关代码,发现它是以设置task运行线程interrupt标志位的方式来kill task的。因此,kill的过程和task的代码是否能正确响应中断有关。2.5s 的时间就可以理解了
//Task.scala
/**
* Kills a task by setting the interrupted flag to true. This relies on the upper level Spark
* code and user code to properly handle the flag. This function should be idempotent so it can
* be called multiple times.
* If interruptThread is true, we will also call Thread.interrupt() on the Task's executor thread.
*/
def kill(interruptThread: Boolean, reason: String) {
require(reason != null)
_reasonIfKilled = reason
if (context != null) {
context.markInterrupted(reason)
}
if (interruptThread && taskThread != null) {
taskThread.interrupt()
}
}
从方法的注释可以看出,用户代码要处理好中断,否则可能导致task kill时间很长的问题。
四、解决方案
从spark的某处代码可以看出,spark方面是知道这个问题的,但是到目前版本都没有修改这个问题。
// Sometimes (e.g., when speculative task is enabled), temporary directories may be left
// uncleaned. Here we simply ignore them.
if (currentPath.getName.toLowerCase == "_temporary") {
return (None, None)
}
如果要解决这个问题,可以修改stage的判断规则,确保所有的task都上报结果上来了再结束job(包括那些被kill的task)。但是这样就会有一个问题,就像上面说的,kill task是以比较温和的方式进行,如果用户代码没处理好中断,很可能会导致kill时间很久的问题。如果以这种方式来判断job结束,任务的运行时间会更长。同时很可能导致推测执行没有任何意义。
因此,这可能也是spark明知道有这个问题却一直没修复的原因。
参考资料
https://zhuanlan.zhihu.com/p/45351972

















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









