







 本文介绍了阿里巴巴在CTR预测中的两种深度学习模型:DIN(深度兴趣网络)和DIEN(深度兴趣进化网络)。DIN通过注意力机制捕捉用户历史行为与候选广告的相关性,自适应地学习用户兴趣表示。而DIEN进一步引入兴趣抽取和兴趣进化层,利用GRU单元和注意力机制捕捉用户兴趣随时间的演化,以更准确地预测点击率。这两种模型在处理用户行为序列的变长特征和兴趣多样性上具有创新性。
本文介绍了阿里巴巴在CTR预测中的两种深度学习模型:DIN(深度兴趣网络)和DIEN(深度兴趣进化网络)。DIN通过注意力机制捕捉用户历史行为与候选广告的相关性,自适应地学习用户兴趣表示。而DIEN进一步引入兴趣抽取和兴趣进化层,利用GRU单元和注意力机制捕捉用户兴趣随时间的演化,以更准确地预测点击率。这两种模型在处理用户行为序列的变长特征和兴趣多样性上具有创新性。
目录
2.1 base line (embeding + MLP)
3.1 兴趣抽取层Interest Extractor Layer
3.2 兴趣进化层Interest Evolution Layer
一 淘宝数据描述
https://tianchi.aliyun.com/dataset/dataDetail?dataId=56
Ali_Display_Ad_Click是阿里巴巴提供的一个淘宝展示广告点击率预估数据集。
1.1 auc 与gauc
推荐系统评价指标:AUC和GAUC
https://mp.weixin.qq.com/s/d764qYdnCSk62GQKfl_GCg
auc:
-
AUC的意义:随机抽取一对正负样本,AUC是把正样本预测为1的概率大于把负样本预测为1的概率的概率。
gauc:
我们采用了阿里提出来的gauc定义:
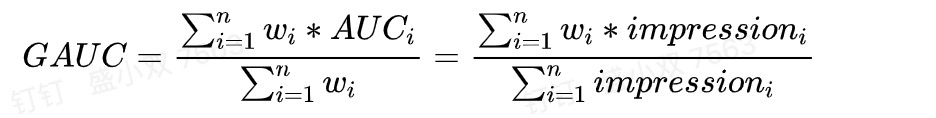
补充:其中为权重,一般可以设为每个用户view的次数,或click的次数,而且一般计算时,会过滤掉单个用户全是正样本或负样本的情况
二 DIN
从DIN到DIEN看阿里CTR算法的进化脉络
https://zhuanlan.zhihu.com/p/78365283
https://www.zhihu.com/search?type=content&q=DIN%E6%BF%80%E6%B4%BB%E5%8D%95%E5%85%83
DIN原理与实践(写的很好)
https://mp.weixin.qq.com/s/WDRKYJWBYF0izO_5vpgc6Q
2.1 base line (embeding + MLP)
在介绍算法之前我们先来看一看阿里的展示广告系统中用到哪些特征。主要有4个特征组,如下图所示,1)用户画像特征,2)用户行为特征,即用户点击过的商品,3)待曝光的广告,广告其实也是商品,后文中我们统称为candidate,4)上下文特征。
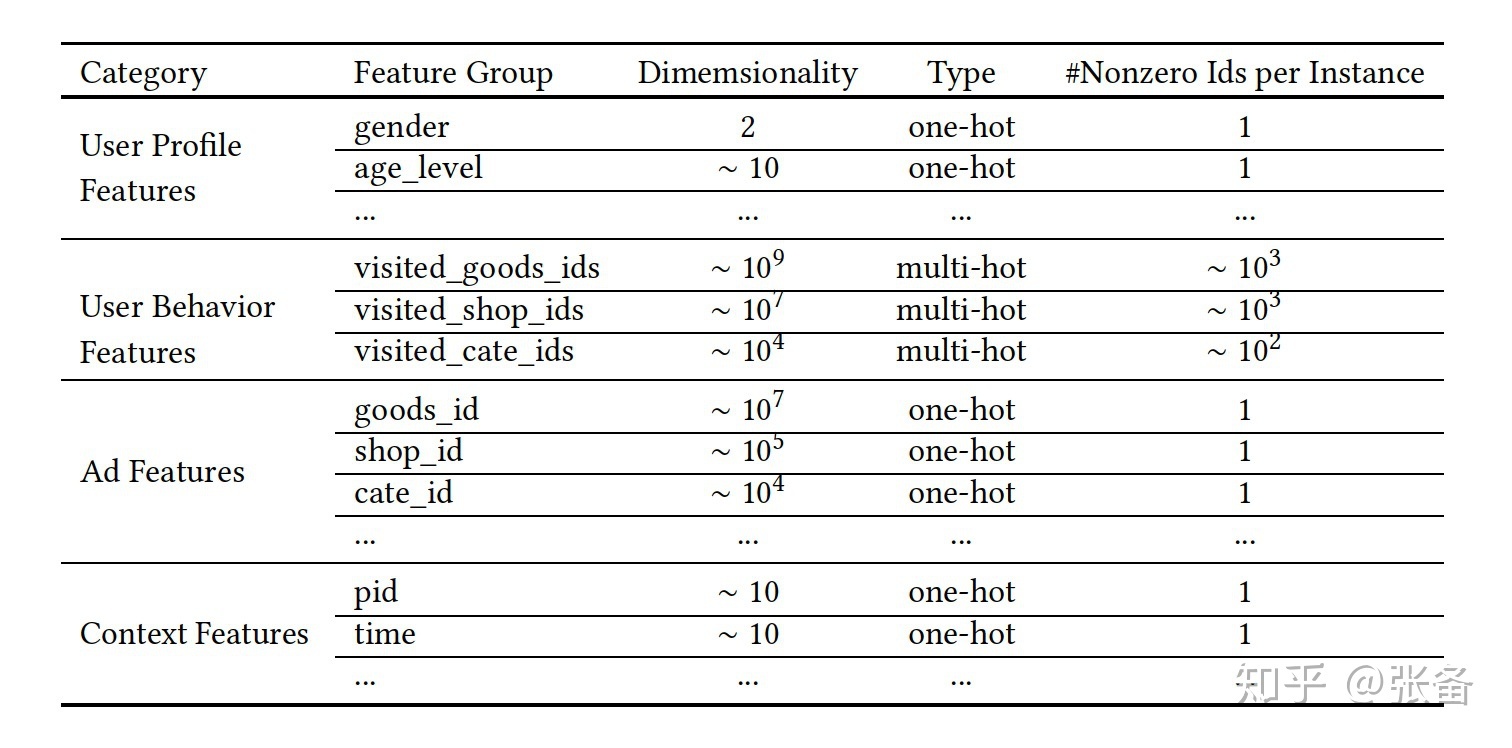
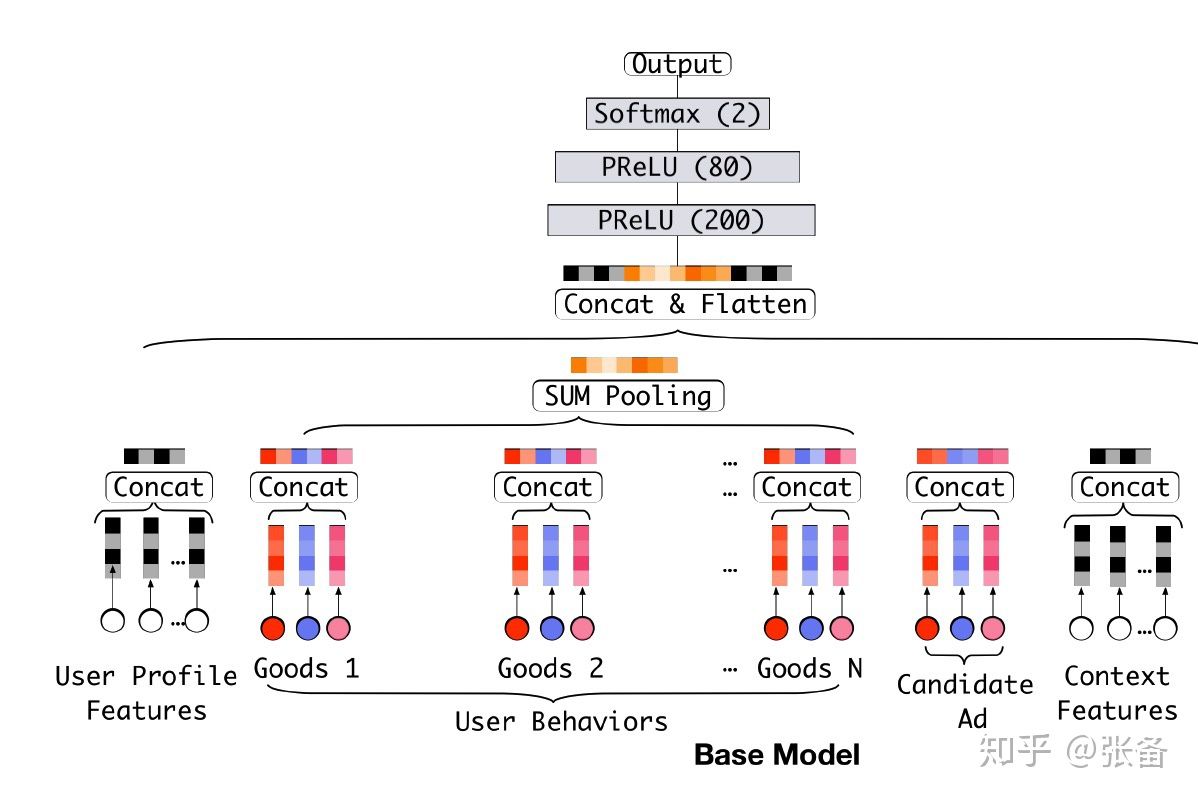
MLP只能接受固定长度的输入,但是每个用户在一段时间内的商品点击序列长度可能会不同,属于变长特征,那么该如何处理这样的变长特征?base模型采用pooling的方式,一般有两种方法,求和或者平均,求和就是对多个商品的embedding,在每个对应的维度上做求和。例如,点击序列有10个商品,那么就有10个商品的embedding,假设商品的embedding维度是16,那么分别在第1到16维上,对10个值求和。平均就是对多个embedding,在每个对应的维度上求平均。不管用户点击过多少个商品,经过pooling之后,得到的最终表示向量embedding和每个商品的embedding维度都是相同的。
回到阿里的展示广告系统,如图2所示,每个商品有3个特征域,包括商品自身,商品类别,商品所属的商铺。对于每个商品来说,3个特征embedding拼接之后才是商品的表示向量。对商品序列做pooling,上图中采用的是求和的方式,pooling之后得到用户行为序列的表示向量。然后再和其他的特征embedding做拼接,作为MLP的输入。
MLP输入端的整个embedding向量,除了candidate的embedding部分,其余的embedding部分可以视为用户的表示向量。base模型对于任何要预测的candidate,不管这个candidate是衣服,电子产品等,用户的表示向量都是确定的、不变的,对于任何candidate都无差别对待。
在电商这个场景中,通常用户的兴趣具有多样性,可能在一段时间内点击过衣服,电子产品,鞋子等。而对于不同的candidate来说,浏览过的相关商品对于预测帮助更大,不相关的商品对于ctr预估可能并不起作用,例如用户看过的衣服,鞋子对于iphone的预测并没有帮助。
这样做有什么问题?
1. 一个明显的问题是不同用户的行为序列长度是不同的,fixed-length信息表达不全面
2. 用户最终的行为只和历史行为中的部分有关,因此对历史序列中商品相关度应有区分
2.2 DIN
根据上述问题,有两个解决思路:
1.对不同用户尝试不同维度的向量,导致训练困难
2.如何在有限的维度表示用户的差异化兴趣?
DIN从第二个问题出发,引入局部激活单元,对特定的ad自适应学习用户兴趣表示向量。即同一用户在获选ad不同时,embedding向量不同。
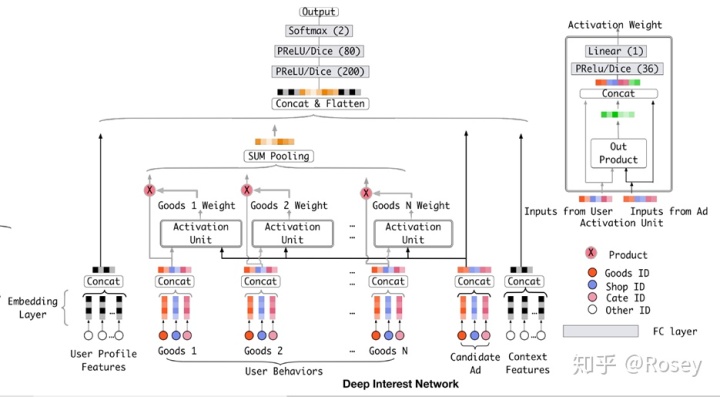
key idea
使用attention机制捕获ad和用户行为序列商品之间的关系
看结果
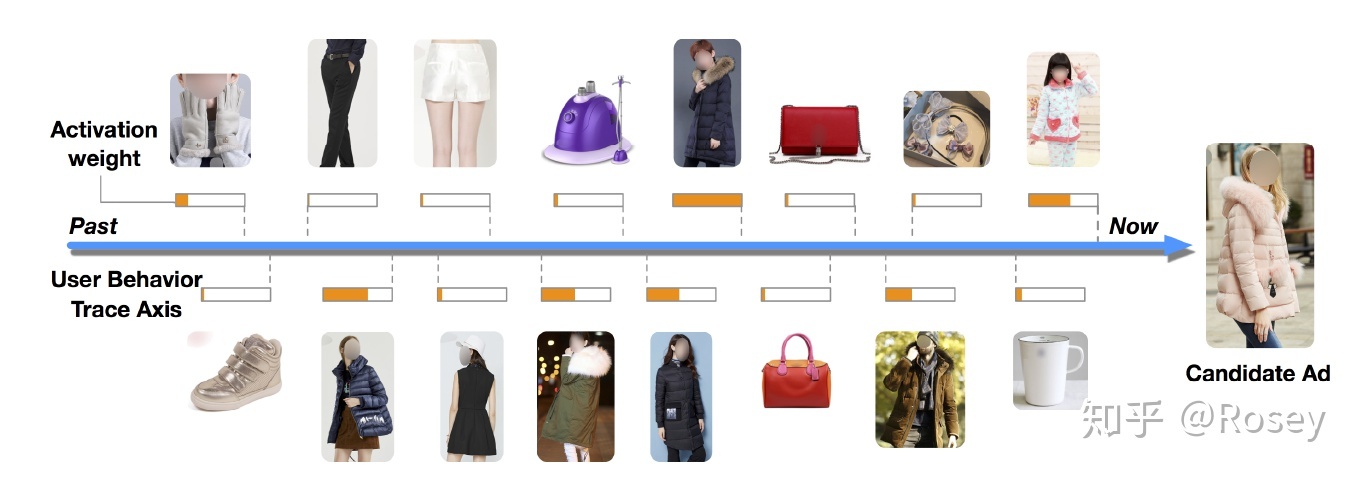
- 和ad相似度搞得物品拥有更高的权重
- 不相关物品的相似度低
下面是两个小tricks,对结果提升有帮助:
- Mini-batch Aware Regularization
- Dice Activation Function
Attention机制简单的理解就是,针对不同的广告,用户历史行为与该广告的权重是不同的。假设用户有ABC三个历史行为,对于广告D,那么ABC的权重可能是0.8、0.1、0.1;对于广告E,那么ABC的权重可能是0.3、0.6、0.1。这里的权重,就是Attention机制即上图中的Activation Unit所需要学习的。
为什么要引入Attention?举例:假设用户的兴趣的Embedding是Vu,候选广告的Embedding是Va,用户兴趣和候选的广告的相关性可以写作F(U,A) = Va * Vu。如果没有Local activation机制,那么同一个用户对于不同的广告,Vu都是相同的。如果有两个广告A和B,用户兴趣和A,B的相似性都很高,那么在Va和Vb连线上的广告都会有很高的相似性。这样的限制使得模型非常难学习到有效的用户和广告的embedidng表示。
DIN的核心idea是,候选广告需要和用户行为中的每一个商品做权重的计算,然后用权重去做加权平均得到用户针对这个候选广告的兴趣向量。也就是说 DIN 是通过考虑用户的当前点击行为与历史行为的相关性来自适应地计算用户兴趣的表示向量,用户的历史行为的权重依赖于正在看的商品。
DIN使用activation unit来捕获local activation的特征,使用weighted sum pooling来捕获diversity结构
三 DIEN
如果候选商品是衣服,那希望最近购买的衣服更能影响的当下的决策,DIN是不能做的, 他是用户行为序列中都是衣服embeding可能权重差不多,但其实越近的越能影响当下决策
推荐系统遇上深度学习(二十四)--深度兴趣进化网络DIEN原理及实战!
https://mp.weixin.qq.com/s/PtJHJMWzbOrKWejvcnClVg
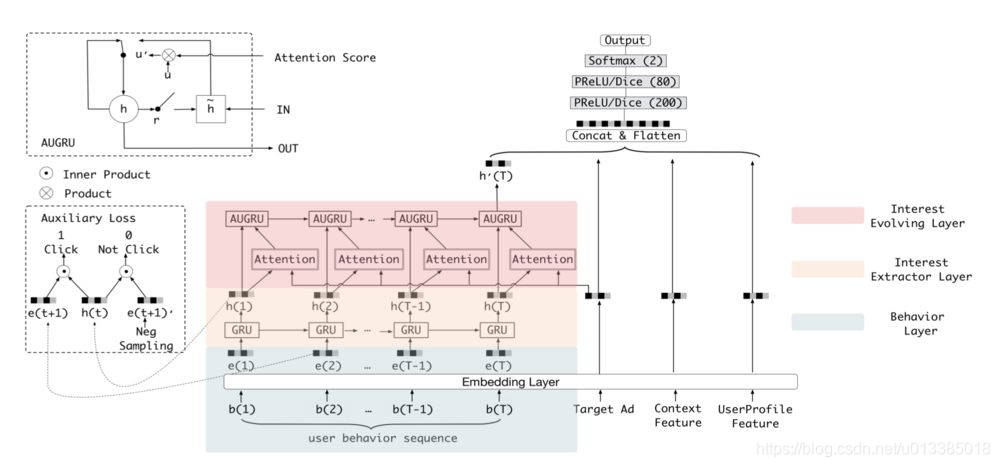
3.1 兴趣抽取层Interest Extractor Layer
兴趣抽取层Interest Extractor Layer的主要目标是从embedding数据中提取出interest。但一个用户在某一时间的interest不仅与当前的behavior有关,也与之前的behavior相关,所以作者们使用GRU单元来提取interest。GRU单元的表达式如下:
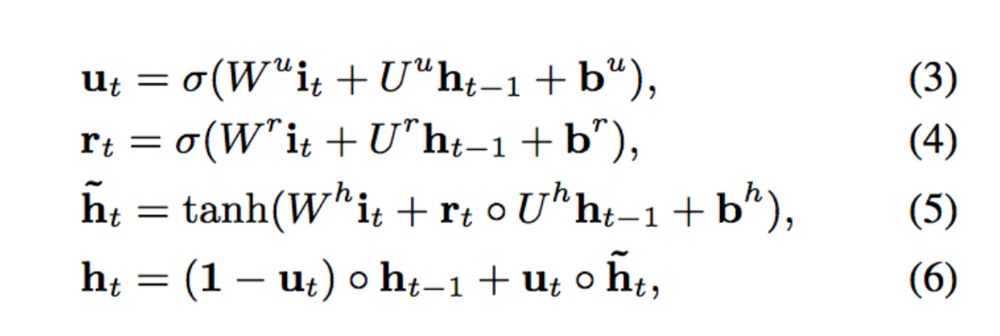
这里我们可以认为ht是提取出的用户兴趣,但是这个地方兴趣是否表示的合理呢?文中别出心裁的增加了一个辅助loss,来提升兴趣表达的准确性:
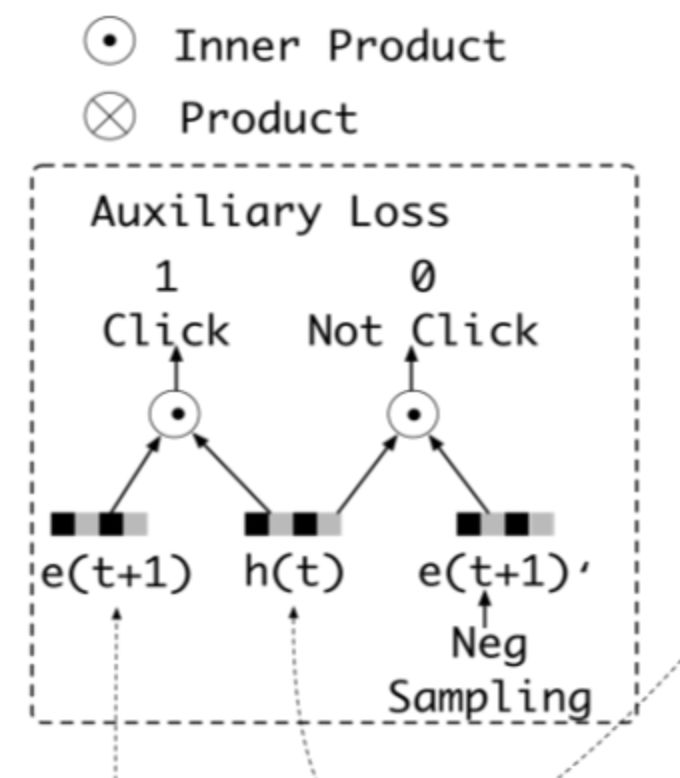
这里,作者设计了一个二分类模型来计算兴趣抽取的准确性,我们将用户下一时刻真实的行为e(t+1)作为正例,负采样得到的行为作为负例e(t+1)',分别与抽取出的兴趣h(t)结合输入到设计的辅助网络中,得到预测结果,并通过logloss计算一个辅助的损失:
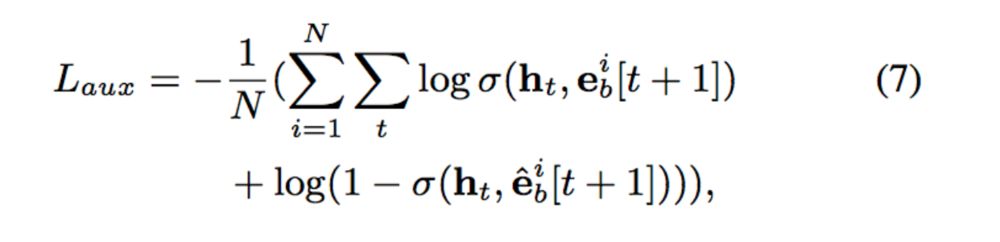
3.2 兴趣进化层Interest Evolution Layer
兴趣进化层Interest Evolution Layer的主要目标是刻画用户兴趣的进化过程。举个简单的例子:
以用户对衣服的interest为例,随着季节和时尚风潮的不断变化,用户的interest也会不断变化。这种变化会直接影响用户的点击决策。建模用户兴趣的进化过程有两方面的好处:
1)追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息。
2)可以根据interest的变化趋势更好地进行CTR预测。
而interest在变化过程中遵循如下规律:
1)interest drift:用户在某一段时间的interest会有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服。
2)interest individual:一种interest有自己的发展趋势,不同种类的interest之间很少相互影响,例如买书和买衣服的interest基本互不相关。
为了利用这两个时序特征,我们需要再增加一层GRU的变种,并加上attention机制以找到与target AD相关的interest。
attention的计算方式如下:
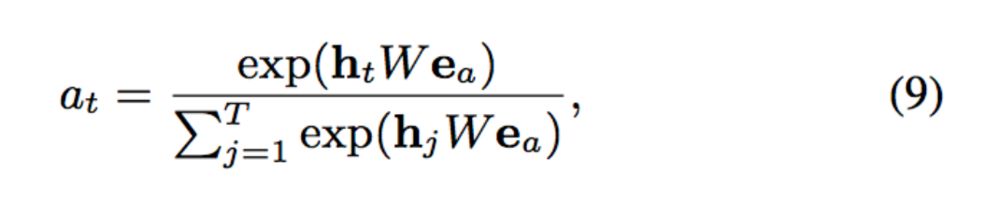
而Attention和GRU结合起来的机制有很多,文中介绍了一下三种:
GRU with attentional input (AIGRU)
这种方式将attention直接作用于输入,无需修改GRU的结构:
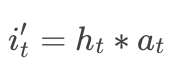
Attention based GRU(AGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:
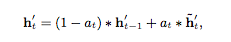
GRU with attentional update gate (AUGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:
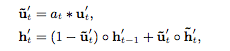

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









