







卷积神经网络CNN
- 总体感知
卷积神经网络沿用了普通的神经元网络即多层感知器的结构,是一个前馈网络。以应用于图像领域的CNN为例,大体结构如图1。

这个典型的结构分为四个大层次:
- 输入图像 I.
- 多个卷积(C)-下采样(S)层:将上一层的输出与本层权重W做卷积得到各个C层,然后下采样得到各个S层。每次将原图像卷积后,都通过一个下采样的过程,来减小图像的规模。这些层的输出称为Feature Map。卷积层和采样层总是成对出现
- 光栅化(X)。是为了与传统的多层感知器全连接。即将上一层的所有Feature Map的每个像素依次展开,排成一列。
- 传统的多层感知器(N&O)。最后的分类器一般使用Softmax,如果是二分类,当然也可以使用LR。
卷积神经网络的核心出发点有三个:
- 局部感受野。形象地说,就是模仿你的眼睛,想想看,你在看东西的时候,目光是聚焦在一个相对很小的局部的吧?严格一些说,普通的多层感知器中,隐层节点会全连接到一个图像的每个像素点上,而在卷积神经网络中,每个隐层节点只连接到图像某个足够小局部的像素点上,从而大大减少需要训练的权值参数。举个栗子,依旧是1000×1000的图像,使用10×10的感受野,那么每个神经元只需要100个权值参数;不幸的是,由于需要将输入图像扫描一遍,共需要991×991个神经元!参数数目减少了一个数量级,不过还是太多。
- 权值共享。形象地说,就如同你的某个神经中枢中的神经细胞,它们的结构、功能是相同的,甚至是可以互相替代的。也就是,在卷积神经网中,同一个卷积核内,所有的神经元的权值是相同的,从而大大减少需要训练的参数。继续上一个栗子,虽然需要991×991个神经元,但是它们的权值是共享的呀,所以还是只需要100个权值参数,以及1个偏置参数。从MLP的 10^9 到这里的100,就是这么狠!作为补充,在CNN中的每个隐藏,一般会有多个卷积核。
- 池化。形象地说,你先随便看向远方,然后闭上眼睛,你仍然记得看到了些什么,但是你能完全回忆起你刚刚看到的每一个细节吗?同样,在卷积神经网络中,没有必要一定就要对原图像做处理,而是可以使用某种“压缩”方法,这就是池化,也就是每次将原图像卷积后,都通过一个下采样的过程,来减小图像的规模。以最大池化(Max Pooling)为例,1000×1000的图像经过10×10的卷积核卷积后,得到的是991×991的特征图,然后使用2×2的池化规模,即每4个点组成的小方块中,取最大的一个作为输出,最终得到的是496×496大小的特征图。
上述参考:http://www.moonshile.com/post/juan-ji-shen-jing-wang-luo-quan-mian-jie-xi#toc_11
- CNN的参数估计
参考博客:http://blog.csdn.net/u012162613/article/details/43225445 (有多篇文章讲的很好)
卷积神经网络的参数估计依旧使用Back Propagation的方法,不过需要针对卷积神经网络的特点进行一些修改。我们从高层到底层,逐层进行分析。
DL采用了与神经网络很不同的训练机制。传统神经网络中,采用的是back propagation的方式进行,简单来讲就是采用迭代的算法来训练整个网络,随机设定初值,计算当前网络的输出,然后根据当前输出和label之间的差去改变前面各层的参数,直到收敛(整体是一个梯度下降法)。而deep learning整体上是一个layer-wise的训练机制。这样做的原因是因为,如果采用back propagation的机制,对于一个deep network(7层以上),残差传播到最前面的层已经变得太小,出现所谓的gradient diffusion(梯度扩散)。
训练算法与传统的BP算法差不多。主要包括4步,这4步被分为两个阶段:
第一阶段,向前传播阶段:
a)从样本集中取一个样本(X,Yp),将X输入网络;
b)计算相应的实际输出Op。
在此阶段,信息从输入层经过逐级的变换,传送到输出层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是计算(实际上就是输入与每层的权值矩阵相点乘,得到最后的输出结果):
Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二阶段,向后传播阶段
a)算实际输出Op与相应的理想输出Yp的差;
b)按极小化误差的方法反向传播调整权矩阵。
- 文字识别系统LeNet-5
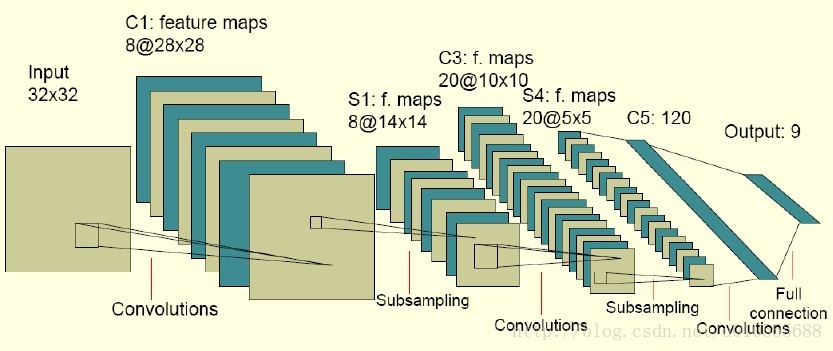
图中的卷积网络工作流程如下,输入层由32×32个感知节点组成,接收原始图像。然后,计算流程在卷积和子抽样之间交替进行,如下所述:
第一隐藏层进行卷积,它由8个特征映射组成,每个特征映射由28×28个神经元组成,每个神经元指定一个 5×5 的接受域;
第二隐藏层实现子 抽样和局部平均,它同样由 8 个特征映射组成,但其每个特征映射由14×14 个神经元组成。每个神经元具有一个 2×2 的接受域,一个可训练 系数,一个可训练偏置和一个 sigmoid 激活函数。可训练系数和偏置控制神经元的操作点。
第三隐藏层进行第二次卷积,它由 20 个特征映射组 成,每个特征映射由 10×10 个神经元组成。该隐藏层中的每个神经元可能具有和下一个隐藏层几个特征映射相连的突触连接,它以与第一个卷积 层相似的方式操作。
第四个隐藏层进行第二次子抽样和局部平均汁算。它由 20 个特征映射组成,但每个特征映射由 5×5 个神经元组成,它以 与第一次抽样相似的方式操作。
第五个隐藏层实现卷积的最后阶段,它由 120 个神经元组成,每个神经元指定一个 5×5 的接受域。
最后是个全 连接层,得到输出向量。
- 参考文献
http://blog.csdn.net/v_july_v/article/details/51812459

- Tensorflow实现
TensorFlow入门
http://hacker.duanshishi.com/?p=1639
tf.placeholder() 和 feed_dict

【TensorFlow】tf.nn.softmax_cross_entropy_with_logits的用法
http://blog.csdn.net/mao_xiao_feng/article/details/53382790
【TensorFlow】tf.nn.max_pool实现池化操作
http://blog.csdn.net/mao_xiao_feng/article/details/53453926
【TensorFlow】tf.nn.conv2d是怎样实现卷积的?
http://blog.csdn.net/mao_xiao_feng/article/details/53444333
7张3*3的featureMap
- import tensorflow as tf
- input = tf.Variable(tf.random_normal([1,5,5,5]))
- filter = tf.Variable(tf.random_normal([3,3,5,7]))
- op = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
- init = tf.initialize_all_variables()
- with tf.Session() as sess:
- sess.run(init)
- print(sess.run(op))
每一行代表7个卷积核在featureMap中同一个像素点的值,featureMap是3*3,所以共9行,代表9个元素的值

前馈神经网络
http://shomy.top/2017/01/01/tensorflow-fnn-example-1/
http://blog.csdn.net/u010089444/article/details/52563514
TF事先设计好网络,然后再填充数据,这种方式的好处是设计与数据分离,不用针对具体数据,而坏处是不容易调试,因为network中的变量在没有数据之前,都还没有分配内存,还好有可视化工具tensorboard,可以很清楚的看到每个变量的shape
TensorFlow-6-TensorBoard 可视化学习
http://www.jianshu.com/p/bce3e572bf47
. tf.summary.scalar
当你想知道 learning rate 如何变化时,目标函数如何变化时,就可以通过向节点附加 tf.summary.scalar 操作来分别输出学习速度和期望误差,可以给每个 scalary_summary 分配一个有意义的标签为 'learning rate' 和 'loss function',执行后就可以看到可视化的图表。
CNNs实现分类
http://shomy.top/2017/01/01/tensorflow-cnn-example-2/
http://www.jeyzhang.com/tensorflow-learning-notes-2.html
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name="W")
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name="bias")
def conv2d(x, W): # 卷积步长为1,卷积操作仅使用了滑动步长为1的窗口,使用0进行填充,所以输出规模和输入的一致;
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME",
name="conv2d")
def max_pool(
x): # 池化操作是在2 * 2的窗口内采用最大池化技术(max-pooling),padding='SAME'表示通过填充0,使得输入和输出的形状一致
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding="SAME", name="pooled")
xs = tf.placeholder(tf.float32, [None, 784])
ys = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(xs, [-1, 28, 28,
1]) # 首先reshape输入图像x为4维的tensor,第2、3维对应图片的宽和高,最后一维对应颜色通道的数目。(?第1维为什么是-1?)
# conv_1 layer
with tf.name_scope('conv-layer-1'):
W_conv1 = weight_variable(
[5, 5, 1, 32]) # outsize=32 : convolutions units(卷积核个数32个)
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # 28 * 28 * 32
h_pooled_1 = max_pool(h_conv1) # 14*14*32
# conv_2 layer
with tf.name_scope('conv-layer-2'):
W_conv2 = weight_variable(
[5, 5, 32, 64]) # 32个featureMap,outsize=64卷积核个数64个
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pooled_1, W_conv2) + b_conv2) # 14 * 14 *64
h_pooled_2 = max_pool(h_conv2) # 7 * 7 * 64
# func1 layer,full connection
with tf.name_scope('nn-layer-1'):
W_fun1 = weight_variable([7 * 7 * 64, 1024])
b_fun1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pooled_2, [-1, 7 * 7 * 64])
h_fun2 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fun1) + b_fun1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fun2_drop = tf.nn.dropout(h_fun2,keep_prob)
# 为了减少过拟合程度,在输出层之前应用dropout技术(即丢弃某些神经元的输出结果)。我们创建一个placeholder来表示一个神经元的输出在dropout时不被丢弃的概率。Dropout能够在训练过程中使用,而在测试过程中不使用。
# TensorFlow中的tf.nn.dropout操作能够利用mask技术处理各种规模的神经元输出。
# func2 layer,output layer: softmax
with tf.name_scope('nn-layer-2'):
W_fun2 = weight_variable([1024, 10])
b_fun2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fun2_drop, W_fun2) + b_fun2))
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction)))
train_step = tf.train.AdamOptimizer(1e-04).minimize(cross_entropy)
## accuracy
correct_prediction = tf.equal(tf.argmax(prediction, 1), tf.argmax(ys, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
import time
n_epochs = 15
batch_size = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
st = time.time()
for epoch in range(n_epochs):
n_batch = mnist.train.num_examples / batch_size
for i in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob:0.6})
print 'epoch', 1+epoch, 'accuracy:', sess.run(accuracy, feed_dict={keep_prob:1.0, xs: mnist.test.images, ys: mnist.test.labels})
end = time.time()
print '*' * 30
print 'training finish.\ncost time:', int(end-st) , 'seconds;\naccuracy:', sess.run(accuracy, feed_dict={keep_prob:1.0, xs: mnist.test.images, ys: mnist.test.labels})















 5010
5010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









