







一、需求分析
抓取盈盈理财数据
抓取url:
https://licai.yingyinglicai.com/product/list.htm
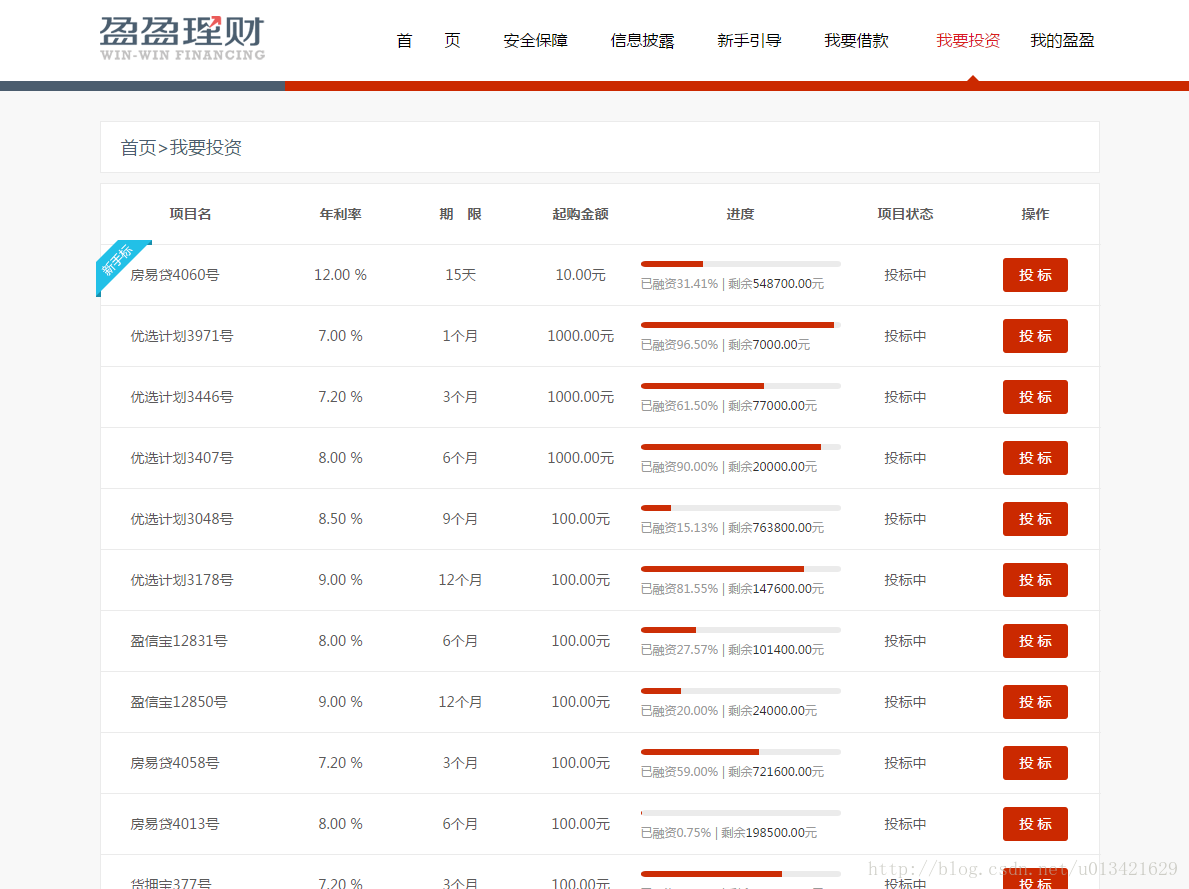
二、效果
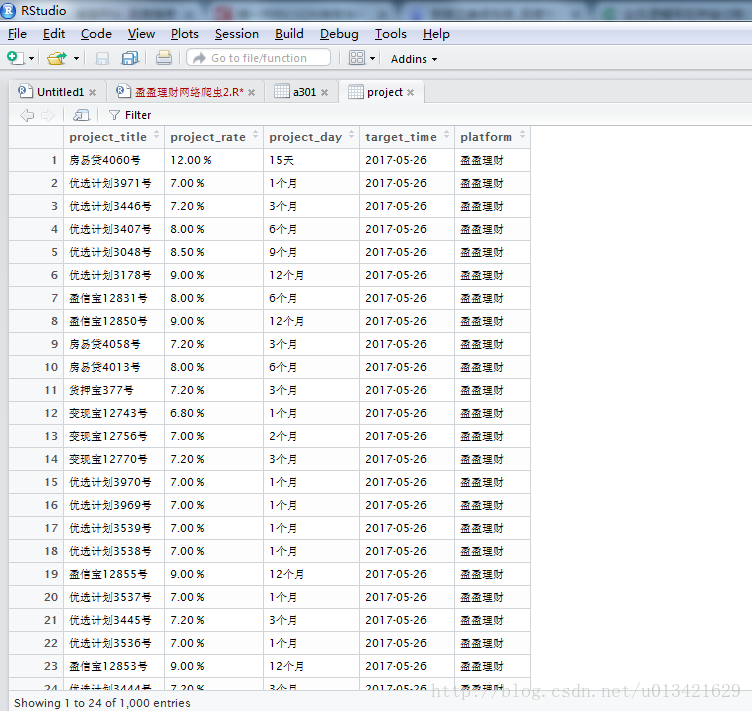
三、实现源代码
rm(list=ls())
library(XML)
library(RCurl)
k=1
url='https://licai.yingyinglicai.com/product/list.htm'
web<-postForm(url,turnPage="",pageNum=k,.opts=curlOptions(url=url,ssl.verifyhost=FALSE,ssl.verifypeer=FALSE))
for(k in 2:50){
web1 <-postForm(url,turnPage="",pageNum=k,.opts=curlOptions(url=url,ssl.verifyhost=FALSE,ssl.verifypeer=FALSE))
web<-c(web,web1)
}
temp1<-iconv(web,"gb2312","UTF-8") #转码
# Encoding(temp1) #UTF-8
doc<-htmlParse(temp1,asText=T,encoding="UTF-8") #选择UTF-8进行网页的解析
project_title<-sapply(getNodeSet(doc,"//p[@class='text-ellipsis-2']//a[text()]"),xmlValue)
project_rate<-sapply(getNodeSet(doc,"//tr//td[2]"),xmlValue)
project_day<-sapply(getNodeSet(doc,"//tr//td[3]"),xmlValue)
project_money_start<-sapply(getNodeSet(doc,"//tr//td[4]"),xmlValue)
target_time<-Sys.Date()
project<-data.frame(project_title,project_rate,project_day,target_time)
project$platform<-c("盈盈理财")
View(project)
##################模糊匹配处理天数################
a101<-grep("个月",project[,3])
a102<-project[a101,]
a102[,3]<-gsub("个月","",a102[,3])
a102[,3]<-as.numeric(a102[,3])*30
a201<-grep("天",project[,3])
a202<-project[a201,]
a202[,3]<-gsub("天","",a202[,3])
a301<-rbind(a102,a202)
a301[,3]<-as.numeric(a301[,3])
View(a301)
output<-write.table(a301,"E:\\数据抓取\\盈盈理财\\project_spider_data.txt",row.names=F,sep="\t")















 4608
4608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











