







1、讲一下BN、LN、IN、GN这几种归一化方法
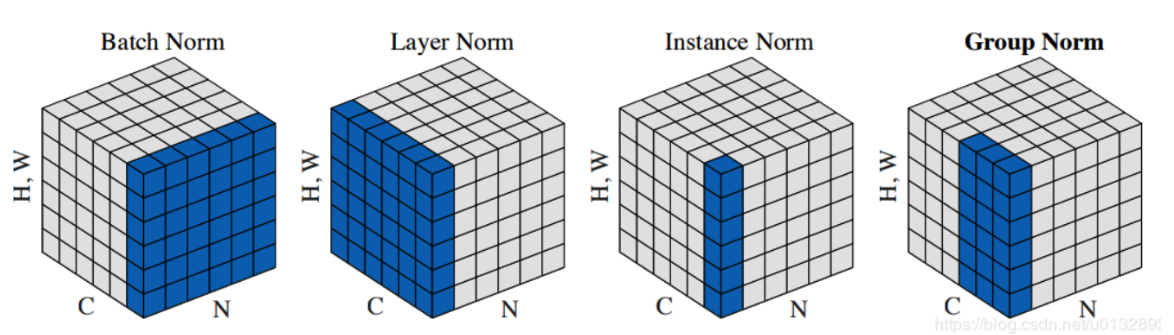
1)BN:
- BatchNormalization,假设特征在不同输入以及H、W层级上是均匀分布的,所以在NHW上统计每个channel的均值和方差,参数量为2C;
- 缺点是容易受到batch内数据分布影响,如果batch_size小的话,计算的均值和方差不具有代表性。而且不适用于序列模型中,因为序列模型中通常各个样本的长度都是不同的。此外当训练数据和测试数据分布有差别时也并不适用;
(2)LN:
- Layer Normalization,LN是独立于batch size的算法,样本数多少不会影响参与LN计算的数据量,从而解决BN的两个问题;
- 缺点是在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息;
(3)IN:
- Instance Normalization,IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batch_size 的影响,常用在风格化迁移,因为它统计了每个样本的每个像素点的信息;
- 缺点是如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理;
(4)GN:
- Group Normalization,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N, G,C//G , H, W],归一化的维度为[C//G , H, W];
- GN的归一化方式避开了batch size对模型的影响,特征的group归一化同样可以解决 I n t e r n a l InternalInternal C o v a r i a t e CovariateCovariate S h i f t ShiftShift 的问题,并取得较好的效果;
2、为什么Transformer 需要进行 Multi-head Attention
Transformer的多头注意力类似CNN中同一卷积层内使用多个卷积核的思路,因为模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
3、讲一下self attention的原理
Self-Attention 是输入数据内部元素之间发生的 Attention 机制,也可以理解为 Target = Source 的特殊情况下的 Attention 机制:
在这种情况下n个输入直接对应n个输出,没有序列顺序(因此可以并行计算),并且每个输入对应着一个K,V,Q。该操作可以表示为:
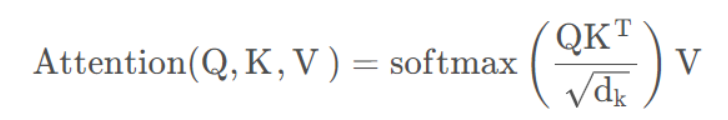
具体来说,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度,其中为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。
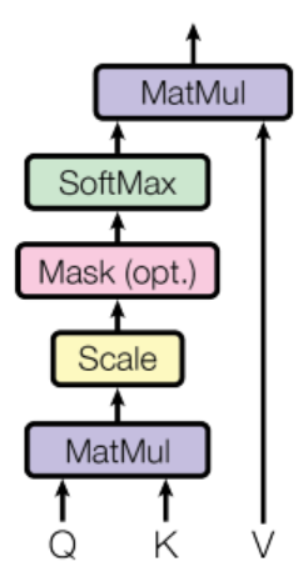
4、讲一下QKV的意义
Values 是由一个序列输入组成,此时给定 Target 中某个元素 Query,通过计算 Query 和各个 Key 的相似性,得到每个 Key 对 Value 的权重系数,然后对 Values 进行加权求和,即得到最终 Attention 数值 Output:
5、手写NMS代码
import numpy as np
def py_nms(dets, thresh):
"""Pure Python NMS baseline."""
#x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个候选框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#order是按照score降序排序的
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
#计算当前概率最大矩形框与其他矩形框的相交框的坐标,会用到numpy的broadcast机制,得到的是向量
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交框的面积,注意矩形框不相交时w或h算出来会是负数,用0代替
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算重叠度IOU:重叠面积/(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#找到重叠度不高于阈值的矩形框索引
inds = np.where(ovr <= thresh)[0]
#将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要把这个1加回来
order = order[inds + 1]
return keep#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
typedef struct Bbox{
int x;
int y;
int w;
int h;
float score;
}Bbox;
static bool sort_score(Bbox box1,Bbox box2){
return box1.score > box2.score ? true : false;
}
float iou(Bbox box1,Bbox box2){
int x1 = max(box1.x,box2.x);
int y1 = max(box1.y,box2.y);
int x2 = min(box1.x+box1.w,box2.x+box2.w);
int y2 = min(box1.y+box1.h,box2.y+box2.h);
int w = max(0,x2 - x1);
int h = max(0,y2 - y1);
float over_area = w*h;
return over_area/(box1.w * box1.h + box2.w * box2.h - over_area);
}
vector<Bbox> nms(std::vector<Bbox>&vec_boxs,float threshold){
vector<Bbox> results;
std::sort(vec_boxs.begin(), vec_boxs.end(), sort_score);
while(vec_boxs.size() > 0)
{
results.push_back(vec_boxs[0]);
int index = 1;
while(index < vec_boxs.size()){
float iou_value = iou(vec_boxs[0],vec_boxs[index]);
//cout << "iou:" << iou_value << endl;
if(iou_value > threshold)
vec_boxs.erase(vec_boxs.begin() + index);
else
index++;
}
vec_boxs.erase(vec_boxs.begin());
}
return results;
}
int main(){
vector<Bbox> input;
Bbox box1 = {1,1,1,1,0.3};
Bbox box2 = {0,0,2,2,0.4};
//Bbox box1 = {1,3,2,2,0.3}; //iou为负
//Bbox box2 = {0,0,2,2,0.4};
//Bbox box1 = {4,4,2,2,0.3};
//Bbox box2 = {0,0,2,2,0.4};
// Bbox box1 = {4,4,1,1,0.3};
// Bbox box2 = {0,0,2,2,0.4};
// Bbox box1 = {3,3,1,1,0.3};
// Bbox box2 = {0,0,2,2,0.4};
input.push_back(box1);
input.push_back(box2);
vector<Bbox> res;
res = nms(input, 0.2);
for(int i = 0;i < res.size();i++){
printf("%d %d %d %d %f",res[i].x,res[i].y,res[i].w,res[i].h,res[i].score);
cout << endl;
}
return 0;
}6、为什么Cascade RCNN有效
作者做出如下观察:
- RCNN中0.5是常用的正负样本界定的阈值,但是当阈值取0.5时会有较多的误检,因为0.5的阈值会使得正样本中有较多的背景,这是较多误检的原因;
- 用0.7的IOU阈值可以减少误检,但检测效果不一定最好,主要原因在于IOU阈值越高,正样本的数量就越少,因此过拟合的风险就越大;
基于上述两个观察就有了这篇文章的cascade R-CNN,简单讲cascade R-CNN是由一系列的检测模型组成,每个检测模型(检测头)都基于不同IOU阈值的正负样本训练得到,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,其界定正负样本的IOU阈值是不断上升的。
7、为什么DETR不需要NMS
DETR将目标检测看作set prediction问题,使用稀疏的object queries做预测,并采用二分图匹配做label assignment(即一个目标只有一个query进行预测),DETR避免了预测时产生大量的重复检测(duplicates),因此不需要非极大值抑制(NMS)等后处理操作。原文的实验也可以看到到Decoder层数增加,NMS对模型性能的积极影响逐渐消失。
8、说下retinanet的focal loss
one-stage detector的准确率不如two-stage detector的原因,作者认为原因是正负样本的类别不均衡导致的,因为RPN模块提供了相对稳定比例的正负样本(一般是1:3),但是one-stage里面则绝大部分样本为负样本。因此作者提出通过损失来平衡正负样本:
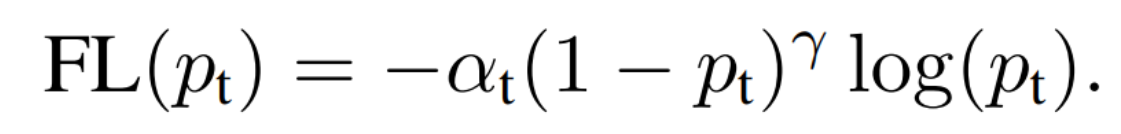
这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,即置信度越高权重越低。
9、讲一下CLIP
做CLIP的团队收集了4亿(图像-文本对),然后训练文本编码器和图像编码器,让成对数据生成的编码相似,损失函数包括两部分,一部分是图像-文本交叉熵损失,一部分是文本-图像交叉熵损失,用来分别训练文本和图像模型。
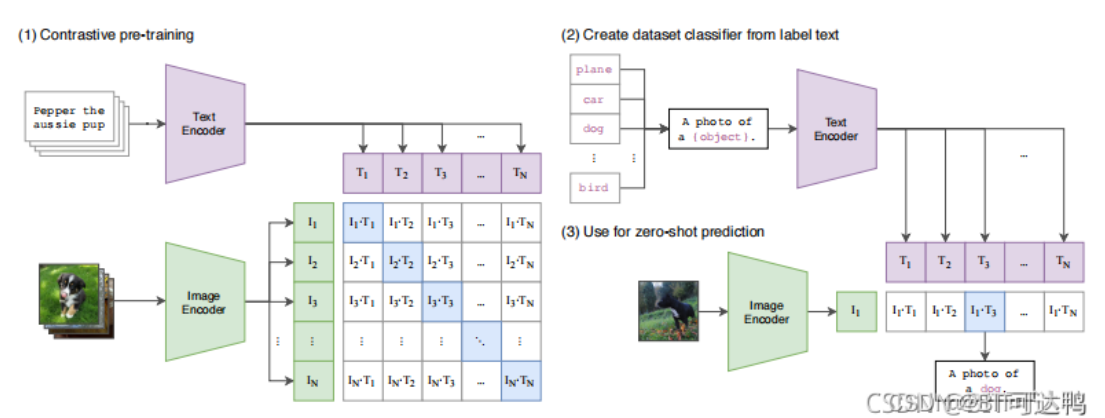

这样模型就可以通过图像-文本任务进行Zero-shot的下游迁移。
10、softmax公式,如果乘上一个系数a, 则概率分布怎么变?
当a>1时变陡峭,当a<1是变平滑
11、softmax和sigmoid函数的区别与联系
Sigmoid =多标签分类问题=多个正确答案=非独占输出
Softmax =多类别分类问题=只有一个正确答案=互斥输出

Softmax函数是二分类函数Sigmoid在多分类上的推广,目的是将多分类的结果归一化后以概率的形式展现出来。
12、如何解决正负样本不平衡问题
数据不平衡问题:
过采样,对训练集里面样本数量较少的类别(少数类)进行过采样,合成新的样本来缓解类不平衡。
欠采样,对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。
合成新的少数类
13、过拟合的解决方法:
过拟合:早停法、决策树剪枝、正则化、神经网络的dropout、逐层归一化(batch normalization)、增加样本,数据清洗之后在进行模型训练;
14、如何解决梯度消失和梯度爆炸问题
激活函数的原因,由于梯度求导的过程中梯度非常小,无法有效反向传播误差,造成梯度消失的问题
1)使用 ReLU、LReLU、ELU、maxout 等激活函数
sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。
2)使用批规范化
通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。从上述分析分可以看到,反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,Batch Normalization 就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
15、训练网络不收敛的原因
(1)没有做数据归一化;
(2)没有检查过预处理结果和最终的训练测试结果;
(3)没有做数据预处理;
(4)没有使用正则化;
(5)Batch Size设的太大;
(6)学习率设的不合适;
(7)最后一层的激活函数错误;
(8)网络存在坏梯度,比如当Relu对负值的梯度为0,反向传播时,梯度为0表示不传播;
(9)参数初始化错误;
(10)网络设定不合理,网络太浅或者太深;
(11)隐藏层神经元数量错误;
(12)数据集标签的设置有错误
16、使用较小卷积核的好处
使用了3个3*3卷积核来代替7*7卷积核,使用了2个3*3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
对于两个3*3卷积核,所用的参数总量为2*(3*3)*channels, 对于5*5卷积核为5*5*channels, 因此可以显著地减少参数的数量。
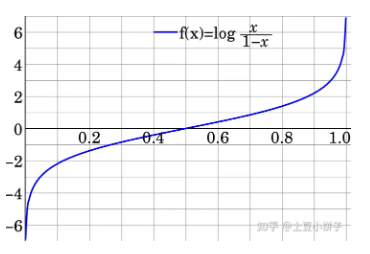
17、Logit函数和sigmoid函数的关系
当我们有一个概率p, 我们可以算出一个比值(odds), p/(1-p), 然后对这个比值求一个对数的操作得到的结果就是logit (L):

这个函数的特点是:可以把输入在[0,1]范围的数给映射到[-inf, inf]之间。所以,他的图像如下:
logistic function 是 logit funciton的反函数,那么我们可以得到:
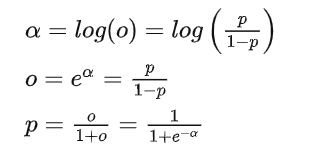
那么,这个p所对应的函数就是logistic function. 这个函数的作用是把[-inf, inf]的数给映射到[0,1]范围内。图像如下:
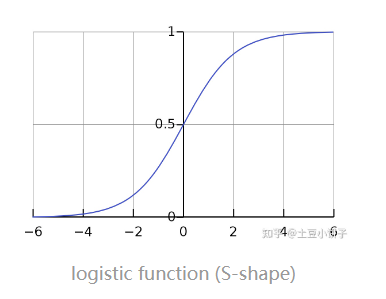
sigmoid function不是某一个函数,而是指某一类形如"S"的函数,都可以成为sigmoid的函数。所以,我们可以说logistic function是一种sigmoid function。
18、优化算法,Adam, Momentum, Adagard,SGD特点
Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与梯度历史平方值总和的平方根成反比。用adagrad将之前梯度的平方求和再开根号作为分母,会使得一开始学习率呈放大趋势,随着训练的进行学习率会逐渐减小。
Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。用来解决梯度下降不稳定,容易陷入鞍点的缺点。
SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行跟新。优点是更新速度快,缺点是训练不稳定,准确度下降。
Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,在经过偏置的校正后,每一次迭代后的学习率都有个确定的范围,使得参数较为平稳,结合momentum和adagrad两种算法的优势。
19、数据标准化的目的是什么?
在现实生活中,一个目标变量(y)可以认为是由多个特征变量(x)影响和控制的,那么这些特征变量的量纲和数值的量级就会不一样,比如x1 = 10000,x2 = 1,x3 = 0.5 可以很明显的看出特征x1和x2、x3存在量纲的差距;x1对目标变量的影响程度将会比x2、x3对目标变量的影响程度要大(可以这样认为目标变量由x1掌控,x2,x3影响较小,一旦x1的值出现问题,将直接的影响到目标变量的预测,把目标变量的预测值由x1独揽大权,会存在高风险的预测)而通过标准化处理,可以使得不同的特征变量具有相同的尺度(也就是说将特征的值控制在某个范围内),这样目标变量就可以由多个相同尺寸的特征变量进行控制,这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了。比如在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛。
简而言之:对数据标准化的目的是消除特征之间的差异性,便于特征一心一意学习权重。
由(1)我们可以知道当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理,反之则不需要进行数据标准化。
在图像数据上的体现是:消除图片过曝,质量不佳等对模型权重的影响;让梯度下降更稳定。
20、 卷积层的缺点
反向传播更新参数对数据的需求量非常大;卷积的没有平移不变性,稍微改变同一物体的朝向或者位置,会对结果有巨大的改变,虽然数据增强会有一定缓解;池化层让大量图像特丢失,只关注整体特征,而忽略到局部。总之,CNN最大的两个问题在于平移不变性和池化层。
21、池化
平均池化(avgpooling)可以保留背景信息。在feature map上以窗口的形式进行滑动(类似卷积的窗口滑动),操作为取窗口内的平均值作为结果,经过操作后,feature map降采样,减少了过拟合现象。前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变。
最大池化(maxpooling)可以提取特征纹理。减少无用信息的影响。maxpooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到。
全局池化(global pooling)来获取全局上下文关系。不以窗口的形式取均值,而是以feature map为单位进行均值化。即一个feature map输出一个值。
最大池化是更多的保留图像的特征纹理,而平均池化是更多的保留图像的背景信息
一般来说,当需要综合特征图上的所有信息做相应决策时,通常会用AvgPooling,例如在图像分割领域中用Global AvgPooling来获取全局上下文信息;在图像分类中在最后几层中会使用AvgPooling。因为网络深层的高级语义信息可以帮助分类器分类。在图像分割/目标检测/图像分类前面几层,由于图像包含较多的噪声和目标处理无关的信息,因此在前几层会使用MaxPooling去除无效信息。
22、如果模型欠拟合怎么办?
1.欠拟合:模型没有充分学习到数据集的特征,导致在训练集和测试集性能都很差的情况。
2.解决办法:
1.增加其他特征项,可以通过“组合”、“泛化”、“相关性”等的操作来添加特征项。
2.添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
3.减少正则化参数。
4.增加模型的复杂度,机器学习中SVM的核函数,决策树扩展分支,深度学习模型中增加网络的深度
5.增加训练次数
23、小目标难检测原因
小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理:
导致小目标在特征图的尺寸基本上只有个位数的像素大小,导致设计的目标检测分类器对小目标的分类效果差。
如果分类和回归操作在经过几层下采样处理的 特征层进行,小目标特征的感受野映射回原图将可能大于小目标在原图的尺寸,造成检测效果差。
小目标在原图中的数量较少,检测器提取的特征较少,导致小目标的检测效果差。
神经网络在学习中被大目标主导,小目标在整个学习过程被忽视,导致导致小目标的检测效果差。
Tricks
(1) data-augmentation.简单粗暴,比如将图像放大,利用 image pyramid多尺度检测,最后将检测结果融合.缺点是操作复杂,计算量大,实际情况中不实用;
(2) 特征融合方法:FPN这些,多尺度feature map预测,feature stride可以从更小的开始;
(3)合适的训练方法:CVPR2018的SNIP以及SNIPER;
(4)设置更小更稠密的anchor,回归的好不如预设的好, 设计anchor match strategy等,参考S3FD;
(5)利用GAN将小物体放大再检测,CVPR2018有这样的论文;
(6)利用context信息,建立object和context的联系,比如relation network;
(7)有密集遮挡,如何把location 和Classification 做的更好,参考IoU loss, repulsion loss等.
(8)卷积神经网络设计时尽量采用步长为1,尽可能保留多的目标特征。
(9)matching strategy。对于小物体不设置过于严格的 IoU threshold,或者借鉴 Cascade R-CNN 的思路。















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









