







这一章主要介绍了backpropagation算法的原理。
backpropagation的核心是一个计算
∂C∂w
的表达式。其中
C
为cost function,参数是weight
Warm up: a fast matrix-based approach to computing the output from a neural network
这一节回顾了一个基于矩阵的计算神经网络输出的算法。并对一些backpropagation用到的符号进行了定义。
这些定义和之前学的没什么不同。
如下图:
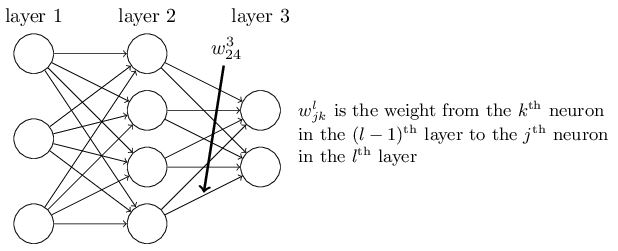
然后解释了为什么定义
这样定义可以在向量化的时候去掉一个转置符号,公式漂亮且加快了运算速度。

The two assumptions we need about the cost function
Backpropagation的目标是计算在网络中的任意
其中cost function
C
为:
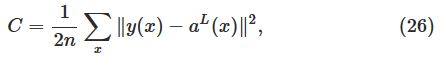
为了backpropagation能工作,我们需要做出以下两个主要的假设:
第一,cost function对于每一个训练样例
x
的
第二,cost function能够被写成神经网络输出的函数,如下图:
The Hadamard product
这一节介绍了一个运算符号
s⊙t
。
含义是elementwise的乘法运算,如下图例子:
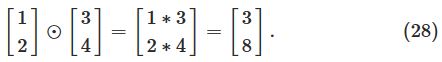
Backpropagation
The four fundamental equations behind backpropagation
这一节是关于backpropagation的重要的四个公式,是这一章的核心。
Proof of the four fundamental equations
这一节简单介绍了公式的推导。
My summary
感觉这两节的写法以及证明方法没有NTU课堂上的逻辑清晰,结合二者,我自己总结了一下。证明全是基于chain rule。
首当其冲要明白,算法的目的是计算 ∂C∂w 和 ∂C∂b 。
而 ∂C∂b 的计算方法可以由 ∂C∂w 的证明中得出来,因此先写出 ∂C∂w ,就可以轻易写出 ∂C∂b 。
以下是关于 ∂C∂w 的计算过程和证明过程:
首先,由于:
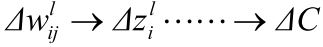
根据chain rule,可以写出:
∂C∂wlij=∂zli∂wlij∂C∂zli
。
对于等式右边第一项
∂zli∂wlij
:
由于
zli=∑jwlijal−1j
,因此
∂zli∂wlij=al−1j
(输入定义为
a0
)。
对于等式右边第二项
∂C∂zli
:
定义
δli=∂C∂zli
。
对于输出层:
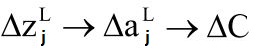
根据chain rule,可以写出:
δLj=∂aLj∂zLj∂C∂aLj=∂C∂aLjσ′(zLj)
(输出定义为
aL
)。
又由于:
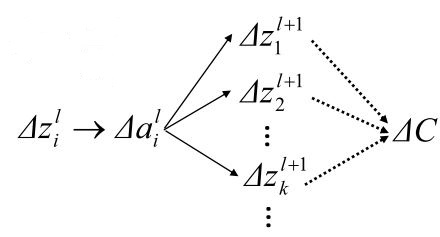
根据chain rule,可以写出:
δli=∂C∂zli=∂ali∂zli∑k∂zl+1k∂ali∂C∂zl+1k
上式右边第一项:
∂ali∂zli=σ′(zlj)
。
上式右边第二项:
zl+1k=∑iwl+1kiali+bl+1k
。
所以,
∂zl+1k∂ali=wl+1ki
。
上式右边第三项:
∂C∂zl+1k=δl+1k
。
综上,得到第l+1层到第l层的
δ
递推式,原来求的初始条件
L
也有了意义。
其递推式为:
至此,所有关于
∂C∂w
的计算过程和证明过程结束。可以得到以下三个重要公式:
δLj=∂C∂aLjσ′(zLj)
δl=((wl+1)Tδl+1)⊙σ′(zl)
∂C∂wlij=al−1jδli
同理,用链式法则可以得到最后一个重要公式:
∂C∂blj=δlj
至此,整个backpropagation简单版的推导与公式计算就此结束。
The backpropagation algorithm
mini-batch的伪代码:

具体实现,上一章有完整代码:
def backprop(self, x, y):
"""Return a tuple "(nabla_b, nabla_w)" representing the
gradient for the cost function C_x. "nabla_b" and
"nabla_w" are layer-by-layer lists of numpy arrays, similar
to "self.biases" and "self.weights"."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)In what sense is backpropagation a fast algorithm?
这一节解释了为什么backpropagation计算
∂C∂wj
的速度比较快。
朴素的算法是对于每一个weight,计算一次偏导,那么当整个神经网络的神经元个数非常多的时候,这个计算量就非常大了。而backpropagation快就在于它能够一次前向传播,一次后向传播计算出所有的偏导。
Backpropagation: the big picture
这一节解释了两个问题:
其一,这个算法在我们做这些矩阵与向量乘法的时候,究竟做了什么。
其二,第一个发现这个算法的人是如何发现它的。
对于第一个问题:
首先假设我们对weight
wljk
做了一个小改变:
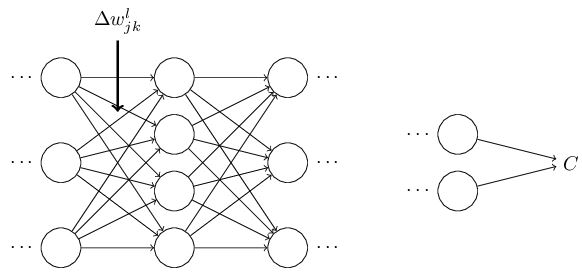
这个改变将会导致接下来一个神经元的输入的改变:
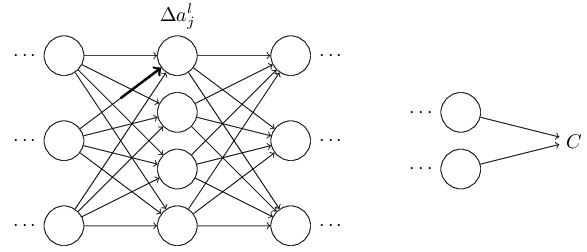
然后继续依此影响接下来的每一层:
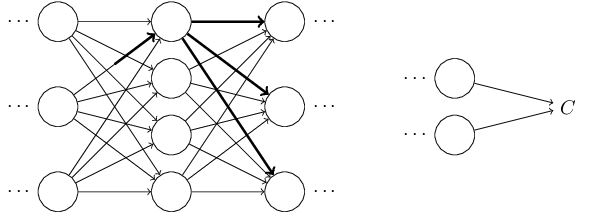
直到影响到输出,以及cost function:
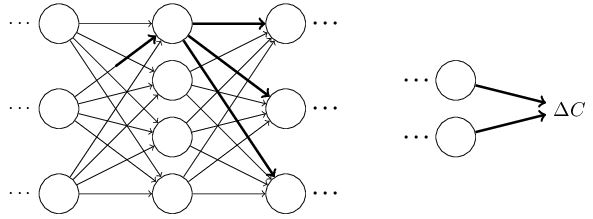
cost function的改变可以由一下式子给出:
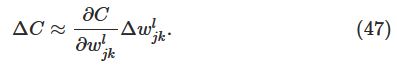
这个式子说明计算出
∂C∂wljk
,就可以计算出改变weight对cost function的影响。由类似chain rule的一系列运算,可以得到:
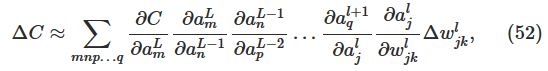
因此:
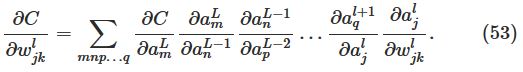
其实意义就是,backpropagation提供了一种计算以上所有影响了cost function路径的和。记录了这些路径的改变是如何影响到输出层和cost function的。
事实上,第二个问题也是由上述过程发现的,也就是说,第一个发现backpropagation的人也是按照以上流程发现了这种算法,而其原来的证明非常复杂,以上的证明只是简单版本的。















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









