






Chanhee Park, Hyeonseok Moon, Chanjun Park
1
{ }^{1}
1, Heuiseok Lim
1
{ }^{1}
1
韩国国立大学,大韩民国
{pch7678, glee889, bcj1210, limhseok}@korea.ac.kr
摘要
检索增强生成(RAG)作为一种有效的方法,通过引入外部知识增强了大型语言模型(LLMs)的生成能力,从而获得了广泛关注。然而,由于检索和生成组件之间的复杂交互作用,RAG系统的评估仍然面临挑战。这一限制导致了能够进行详细、组件特定评估的基准稀缺。在本文中,我们介绍了MIRAGE,这是一个专门为RAG评估设计的问题回答数据集。MIRAGE由7,560个精心策划的实例组成,并映射到一个包含37,800个条目的检索池,从而能够高效且精确地评估检索和生成任务。我们还引入了新的评估指标,旨在衡量RAG适应性,涵盖诸如噪声脆弱性、上下文可接受性、上下文不敏感性和上下文误解等维度。通过在各种检索器-LLM配置下的全面实验,我们提供了关于模型对的最佳匹配以及RAG系统内部微妙动态的新见解。该数据集和评估代码公开可用,允许在多样化的研究环境中无缝集成和定制 1 { }^{1} 1。
1 引言
大型语言模型(LLMs)持续进步,在表现上逐渐超越人类能力(Achiam等人,2023;Dubey等人,2024)。尽管它们的知识库不断扩大,LLMs中的参数化知识容量本质上是有限的(Yu等人,2023a;Lewis等人,2020)。因此,LLMs在应对训练后出现的信息或其训练语料库中代表性不足的数据时面临挑战(Mallen等人,2023;Kasai等人,2023)。
为了解决这些局限性,提出了检索增强生成(RAG)系统作为实际解决方案(Lu等人,2023;Gao等人,2023;Fan等人,2024;Hofstätter等人,2023)。RAG通过集成检索系统获取的外部非参数化知识来增强LLM性能,从而扩展了模型在超出其参数化知识范围内的准确响应能力(Vu等人,2023)。研究表明,RAG技术提高了领域适应性(Hsieh等人,2023)并减轻了幻觉问题(Ji等人,2023)。
然而,尽管RAG系统快速发展,但对其稳健和全面评估方法的研究却滞后。我们确定了RAG系统评估中的几个关键挑战。首先,用于评估的检索池往往过大,使得过程资源密集且效率低下(Mallen等人,2023;Zhao等人,2024)。例如,许多研究依赖于Wikipedia快照 2 { }^{2} 2,其中包含超过五百万个条目,用于评估检索器和RAG系统(Lu等人,2023;Izacard和Grave,2021)。索引如此庞大的数据集会产生显著的计算成本并引入大量延迟。
其次,当前针对RAG系统的评估方法往往过于关注性能提升,通常忽视检索与生成之间的复杂动态(Xie等人,2024;Ru等人,2024)。生成性能的提升通常是在不考虑关键方面的情况下测量的,例如检索知识的有效整合或系统中的知识冲突。
1
1
{ }^{1}
1 MIRAGE代码和数据可在https://github.com/nlpai-lab/MIRAGE获得。
1
{ }^{1}
1 对应作者
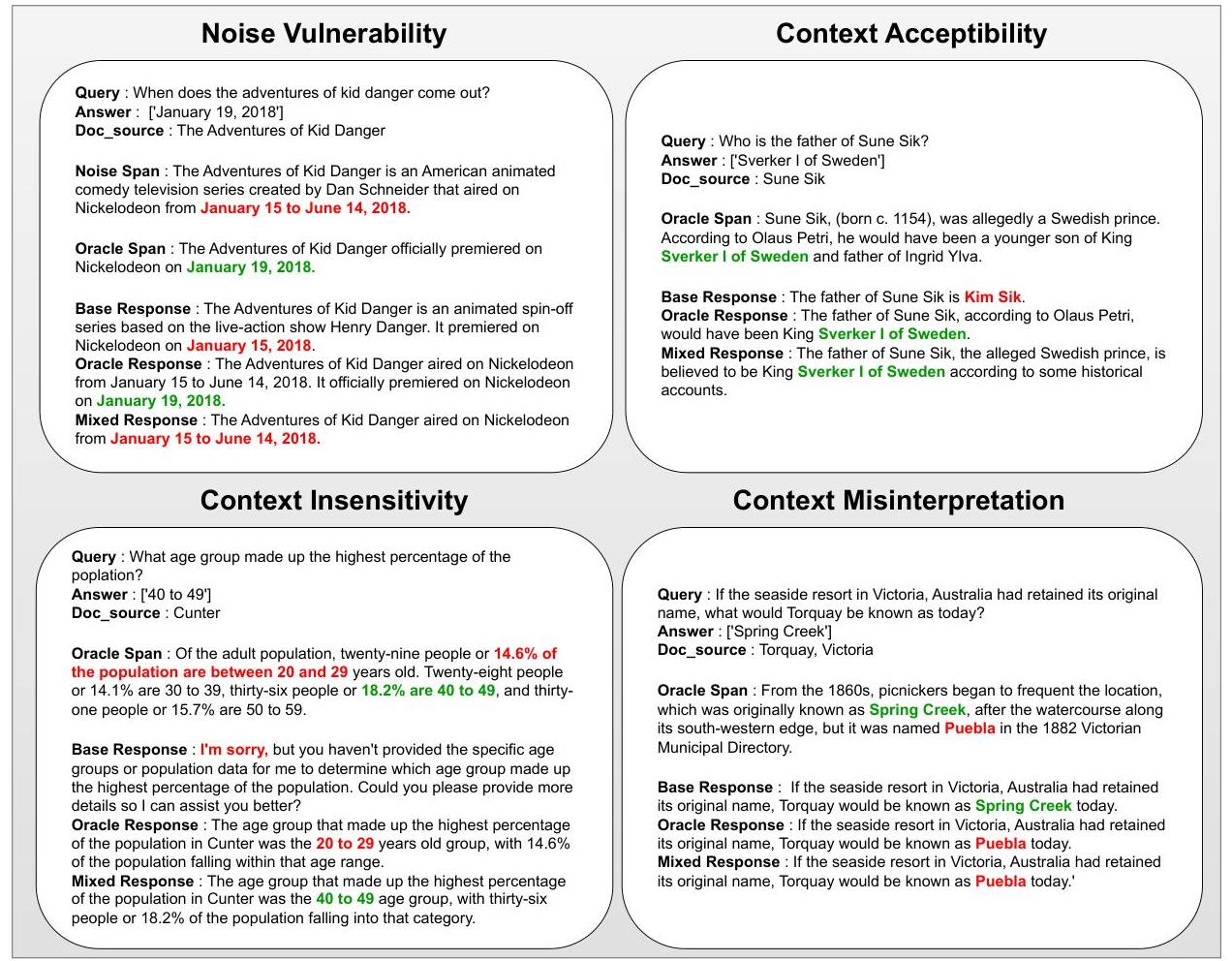
图1:四个RAG适应性指标的示例。通过分析模型在三种不同设置下的响应,我们评估模型在利用相关信息的同时忽略无关噪声的能力。
第三,许多基于LLM的评估设置依赖于大规模外部LLM如GPT-4或Claude3,引发了关于成本和可访问性的担忧(Es等人,2023)。这限制了评估在多样化研究背景下的可扩展性和可复制性。
为了解决这些局限性,我们引入了 M I M I MI RAGE,这是一种紧凑而具有挑战性的基准,专门设计用于评估RAG系统。作为一个轻量级代理,MIRAGE可以替代计算繁重的RAG评估,它包含7,560个查询,链接到一个包含37,800个文档片段的检索池。每个查询至少配有一个包含回答问题所需关键信息的正向文档片段和几个内容相似但缺乏关键信息的负样本。这种设置使我们可以精确快速地评估LLM和检索器的性能,同时保持较小且更高效的检索池。
此外,我们提出了四种新指标,
能够对LLM的生成性能及其整合检索信息的能力进行细粒度分析。这些指标专门设计用于评估给定LLM和检索器设置的RAG适应性,以找到最佳组合。
MIRAGE通过对现有基准的重新组织和改进构建而成(Mallen等人,2022;Kwiatkowski等人,2019;Joshi等人,2017;Yu等人,2023b;Dua等人,2019)。在本文中,我们详细展示了数据构建管道以确保进一步的可重复性。我们公开提供我们的基准和代码 3 { }^{3} 3。
2 相关工作
检索增强生成(RAG)在自然语言处理领域引起了广泛关注,推动了各种工具、基准和数据集的发展,用于评估系统性能(Lewis等人,2020;
3
{ }^{3}
3 代码和数据将在发表后发布
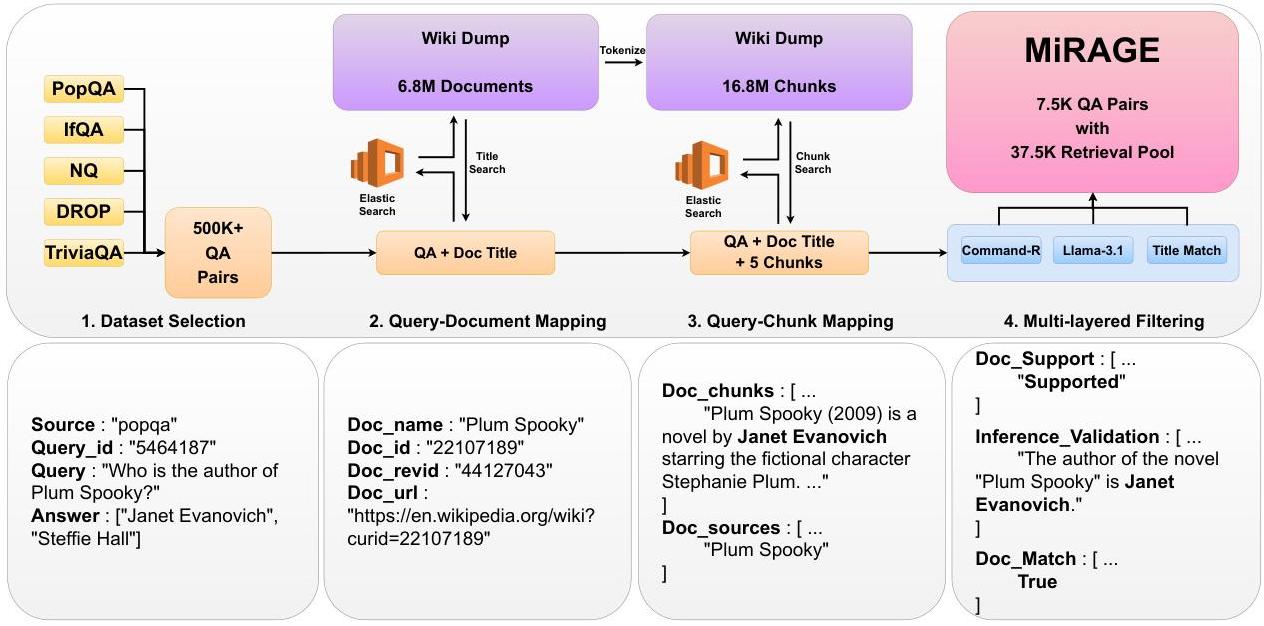
图2:MIRAGE的数据过滤过程
Neelakantan等人,2022)。目前的工作主要集中在衡量检索上下文的质量(Karpukhin等人,2020)。然而,现有的解决方案往往存在局限性,例如数据集不完整或缺乏全面覆盖检索和生成任务的专用基准(Fabbri等人,2021)。本节回顾了与RAG系统评估相关的工具、问答数据集和基准,突出其优势及需要改进的领域(Yang等人,2015)。
2.1 RAG框架
最近的检索增强生成(RAG)进展推动了各种评估工具和基准的发展(Gao等人,2023)。然而,现有的解决方案往往因缺乏全面数据集或未能充分评估检索器性能而受到限制。已经出现了几种用于评估RAG系统的工具,专注于如上下文相关性、答案真实性及答案相关性等指标。例如,RAGAS(Es等人,2023)提供了一个框架来评估这些RAG性能维度。类似地,ARES(SaadFalcon等人,2023)提供了一个自动化评估系统,利用微调于合成数据的轻量级语言模型法官来评估检索和生成组件。此外,RAGCHECKER(Ru等人,2024)实现了对RAG系统内检索和生成的详细分析。虽然这些工具通过多样的评估指标提供了有价值的见解,但它们通常缺乏专为全面评估RAG性能设计的数据集。
2.2 QA数据集
已开发出多个问答(QA)数据集,用于挑战大型语言模型(LLMs),提出没有相关上下文难以回答的查询。例如PopQA、TriviaQA、IfQA和DROP,这些数据集主要基于Wikipedia数据,旨在暴露RAG环境中的性能差异。例如,TriviaQA(Joshi等人,2017)包含从95K名业余爱好者编写的问题对中提取的超过650K问题-答案-证据三元组,每个问题平均有六个支持证据文档。同样,PopQA(Mallen等人,2022)是一个大规模开放域QA数据集,包含14K个以实体为中心的问题-答案对。尽管这些数据集提供了有价值的QA对,但它们缺乏集成的检索池,要求研究人员开发自己的检索系统和数据加载流程,这可能会使实验复杂化并限制可重复性。
2.3 RAG基准
一些基准,如RGB(Chen等人,2024b)和RECALL(Liu等人,2023),提供了专门设计用于RAG评估的数据集。尽管这些基准做出了贡献,但它们往往
无法彻底评估检索器性能,这是RAG系统中的关键组件。像Natural Questions(NQ)(Kwiatkowski等人,2019)和MS MARCO(Bajaj等人,2016)这样的大规模数据集已被广泛应用于信息检索和问答任务中,维护排行榜和基准以供更广泛的社区使用。然而,这些数据集依赖于整个Wikipedia转储,虽然全面,但规模太大,不适合本地检索池的构建。例如,NQ语料库要求QA系统处理整个Wikipedia文章,其中许多可能并不包含相关答案,这导致检索和评估效率低下。
据我们所知,目前尚无公开可用的基准,同时提供问答对和专为RAG系统评估设计的相应检索池。这一空白凸显了对综合性基准的需求,该基准既能促进RAG系统的评估,又能提供易于访问的检索池,从而实现更高效和可重复的实验。
3 MIRAGE
MIRAGE数据集被设计为高质量基准,旨在通过一组具有挑战性的问答对评估RAG系统的各个组件。为了确保鲁棒性和相关性,我们采用了细致的多阶段过滤过程,如图2所示。下面,我们概述了从初始选择到多层过滤的每个数据集构建阶段,以保证数据质量。
3.1 数据集选择
我们通过选择满足三个主要标准的现有QA数据集开始了MIRAGE的构建:(1) 基于Wikipedia的内容,(2) 提供答案跨度,(3) 包含文档信息。选择了PopQA、Natural Questions (NQ)、TriviaQA、IfQA和DROP等数据集,因为它们符合这些标准。这些数据集要么直接提供文档标题(PopQA、NQ),要么包含可追溯到完整Wikipedia文章的段落(TriviaQA、IfQA、DROP)。聚焦于多跳检索的数据集,如HotpotQA或WikiHop(Yang等人,2018;Li等人,2021)被排除在外,以集中于单跳检索场景。此选择过程
结果得到了来自五个不同数据集的超过500,000个QA对的初始池。
3.2 查询到文档的映射
对于查询-文档对齐,我们收集了超过600万篇Wikipedia文章,使用的是2024年9月的enwiki转储 4 { }^{4} 4。与标准数据集构建实践不同,我们反向操作,将现有查询映射回其各自的Wikipedia文章。使用Elasticsearch,我们处理了文档展示分散的数据集,以有效地将查询与文章链接起来。在此阶段,我们过滤掉了无法映射的查询和那些具有重复文档来源的查询,以简化数据集并确保主题覆盖的多样性。这一步骤产生了61,165个准确映射到Wikipedia文章的QA对。
3.3 文档分块
为了促进高效检索,我们使用BERT-base-uncased分词器将Wikipedia文章分割成330个标记的块。此分割采用递归的句子级策略,以保持句子完整性并尽量减少信息丢失。330个标记长度被确定为提供最佳平衡,初步实验表明,这种块大小在检索相关和负样本方面优于其他选项(例如110或550个标记)。这个过程生成了总共 16 , 508 , 989 16,508,989 16,508,989个文档块,每个块都按文档标题索引以便高效查询。对于每个查询,我们通过标题匹配检索前5个文档块,假设答案很可能位于相应的文档中。这一假设通过后续的过滤步骤进行了严格测试。
3.4 多层过滤
为了确保数据集的质量和挑战水平,我们应用了一种多层过滤方法。此过滤过程专注于优化正样本和负样本,以确保检索和生成评估的可靠性。
步骤1:支持标签分配 鉴于人工相关性判断的成本较高,我们利用了
4
{ }^{4}
4 我们使用2024年9月1日的enwiki转储 https://dumps.wikimedia.org/enwiki/20240901/
C4AI command-r模型(Cohere, 2024),该模型经过优化适用于RAG系统,来分配支持标签。该模型评估检索到的块是否提供了足够的上下文来回答给定的查询。这一步自动近似了人类对块相关性的判断,大大减少了人工标注的成本。此任务的详细提示见附录A。
步骤2:通过推理验证 为进一步验证块的相关性,我们使用Llama-3.18B Instruct(Dubey等人,2024)进行基于推理的验证。该模型的任务是使用检索到的块回答查询,并将模型准确响应的实例标记为有效。此外,我们过滤掉模型无需提供的上下文即可回答查询的实例,确保剩余数据点对RAG评估更具挑战性。
步骤3:文档标题验证 对于通过前一验证步骤的块,我们确保每个查询至少有一个相关块准确映射到查询的参考文档。此步骤至关重要,以确认块包含原始数据集中的正确答案,并且模型不是依靠无关信息生成响应。
3.5 人工验证
由于上述过滤过程严重依赖大型语言模型的推理能力,自动生成标签的质量无法得到保证。为了验证这些标签,我们通过随机抽样100个查询和映射到每个查询的500个文档块进行了人工验证。三位注释者被要求根据块中提供的信息判断查询是否可以回答。
平均而言,注释者与模型标签的一致性达到95%,显示出与自动标注过程的高度一致性。通过Krippendorff’s alpha测量的注释者间一致性为0.85,表明注释者之间有很强的一致性。此外,三名注释者的成对Cohen’s Kappa分数范围为0.83至0.89,进一步证实了注释的可靠性。
注释过程的细节见
附录E,注释界面的示例见图5。
3.6 最终数据集统计
最终的MIRAGE由7,560个QA对映射到一个包含37,800个文档块的检索池组成。每个查询都关联一个或多个正向块和若干负样本,从而使检索器、LLM和RAG系统的精确评估成为可能。这一结构化数据集促进了在RAG环境下对检索和生成组件的高效细粒度分析。有关提示设计和过滤方法的更多细节见附录A。
4 评估框架
为了彻底评估RAG系统的性能,我们定义了三种不同的评估设置:无上下文的基本响应、带有正确上下文的Oracle响应以及同时包含噪声和Oracle块的混合响应。混合响应设置反映了现实世界的RAG场景,因为在实践中,RAG系统同时处理噪声和相关信息。相比之下,基本和Oracle设置分别作为每种系统的下限和上限性能。我们始终观察到模型的性能在其基本和Oracle性能之间。通过分析模型在这三种设置下的行为,我们识别出系统在处理外部知识时的优势和弱点。
4.1 输入上下文配置
我们在三种不同的输入设置下评估RAG系统的LLM和检索组件。性能通过系统输出与正确答案标签之间的完全匹配准确性进行测量,确保对检索器和LLM组件的严格评估 5 { }^{5} 5。
基础设置(Ans B B \mathbf{B}_{\mathbf{B}} BB ): 在此配置中,LLM仅基于其内部参数化知识生成答案,没有任何外部上下文。这作为基线用于评估LLM在没有检索增强时嵌入的固有知识。
5
{ }^{5}
5 MIRAGE支持包括仅LLM、仅检索器和带检索器的LLM在内的多种设置的评估,为各种用例提供灵活框架。
Oracle上下文设置(Ans
O
\mathbf{O}
O ): 在此设置中,LLM仅提供正确的上下文块,无噪声或无关信息。从映射到每个查询的前五个块中选择一个相关块。此设置评估当提供高度相关信息时LLM生成准确答案的能力。
混合上下文设置(Ans M \mathbf{M} M ): 在这里,LLM接收五个块的混合,包括一个相关(Oracle)块和几个无关(噪声)块。每个查询的相关块分布如图4所示。此设置测试模型在嘈杂检索上下文中区分相关和无关信息的鲁棒性。
通过比较LLM在这三种设置下的性能,我们评估其内在知识能力、利用外部上下文的能力以及对噪声信息的鲁棒性。我们通过检查生成的RAG系统输出与标签单词或句子的完全匹配来确定准确性。每个查询的输出,表示为Ans,根据完全匹配标签获得二进制评分。
4.2 RAG适应性指标
基于我们预定义的三种情况,我们将子组 G ( b , o , m ) ⊂ D G(b, o, m) \subset D G(b,o,m)⊂D 定义为方程1,其中 D D D 是整个数据集。在这里, b , o b, o b,o, 和 m m m 是取值为0或1的二进制变量。它们用作变量,基于RAG系统的生成结果定义与每种情况相对应的组。
G ( b , o , m ) = { d ∈ D ∣ A n s B ( d ) = b ∧ Ans O ( d ) = o ∧ Ans M ( d ) = m } \begin{gathered} G(b, o, m)=\left\{d \in D \mid \mathbf{A n s}_{\mathbf{B}}(d)=b \wedge\right. \\ \left.\operatorname{Ans}_{\mathbf{O}}(d)=o \wedge \operatorname{Ans}_{\mathbf{M}}(d)=m\right\} \end{gathered} G(b,o,m)={d∈D∣AnsB(d)=b∧AnsO(d)=o∧AnsM(d)=m}
利用这一指示器,我们引入了四个新指标,旨在捕捉检索和生成组件之间细微的相互作用。这些指标提供了对模型在各种输入条件下的行为的详细分析,揭示了系统的适应性和潜在弱点。详细示例见图1。
噪声脆弱性:该指标评估模型在上下文中对噪声的敏感程度。具体来说,它捕捉到模型由于无关信息提供错误答案的情况,即使正确上下文存在也是如此。
这些情况发生在模型在混合上下文中失败 ( Ans M ( d ) = 0 ) \left(\operatorname{Ans}_{\mathbf{M}}(d)=0\right) (AnsM(d)=0),但在给出Oracle上下文时成功 ( Ans O ( d ) = 1 ) \left(\operatorname{Ans}_{\mathbf{O}}(d)=1\right) (AnsO(d)=1),表明在过滤无关块方面存在困难。
∣ G ( 0 , 1 , 0 ) ∣ + ∣ G ( 1 , 1 , 0 ) ∣ ∣ D ∣ \frac{|G(0,1,0)|+|G(1,1,0)|}{|D|} ∣D∣∣G(0,1,0)∣+∣G(1,1,0)∣
上下文可接受性:该指标评估模型有效利用所提供上下文生成准确答案的能力。它捕捉到模型在Oracle和混合上下文中都能正确回答的情况 ( Ans M ( d ) = \left(\operatorname{Ans}_{\mathbf{M}}(d)=\right. (AnsM(d)= Ans O ( d ) = 1 \operatorname{Ans}_{\mathbf{O}}(d)=1 AnsO(d)=1 ),表明在处理嘈杂输入时提取相关信息的鲁棒性。
∣ G ( 0 , 1 , 1 ) ∣ + ∣ G ( 1 , 1 , 1 ) ∣ ∣ D ∣ \frac{|G(0,1,1)|+|G(1,1,1)|}{|D|} ∣D∣∣G(0,1,1)∣+∣G(1,1,1)∣
上下文不敏感性:该指标突出显示模型未能利用上下文信息,无论是否提供正确上下文均产生错误答案的情况。具体来说,它跟踪模型的基础和Oracle响应均为错误的情况 ( Ans B = Ans O = 0 ) \left(\operatorname{Ans}_{\mathbf{B}}=\operatorname{Ans}_{\mathbf{O}}=0\right) (AnsB=AnsO=0),揭示了将其外部知识整合到推理过程中的挑战。
∣ G ( 0 , 0 , 0 ) ∣ + ∣ G ( 0 , 0 , 1 ) ∣ ∣ D ∣ \frac{|G(0,0,0)|+|G(0,0,1)|}{|D|} ∣D∣∣G(0,0,0)∣+∣G(0,0,1)∣
上下文误解:当模型即使提供了正确上下文仍生成错误响应时发生幻觉。该指标识别出模型在无上下文时正确回答 ( Ans B = 1 ) \left(\operatorname{Ans}_{\mathbf{B}}=1\right) (AnsB=1)但给出Oracle上下文时产生错误答案 ( Ans O = 0 ) \left(\operatorname{Ans}_{\mathbf{O}}=0\right) (AnsO=0)的情况。这些实例表明模型要么误解了上下文,要么过度依赖无关信息,导致幻觉输出。
∣ G ( 1 , 0 , 0 ) ∣ + ∣ G ( 1 , 0 , 1 ) ∣ ∣ D ∣ \frac{|G(1,0,0)|+|G(1,0,1)|}{|D|} ∣D∣∣G(1,0,0)∣+∣G(1,0,1)∣
4.3 综合RAG评估
由于这四个指标涵盖了所有可能的情况,它们相加为1,使得系统级分析成为可能,并揭示了LLM可能的弱点和优势。该框架不仅突出了检索系统在增强或阻碍
| LLM | 检索器 | 噪声 脆弱性 ( ↓ ) (\downarrow) (↓) | 上下文 可接受性 ( ↑ ) (\uparrow) (↑) | 上下文 不敏感性 ( ↓ ) (\downarrow) (↓) | 上下文 误解 ( ↓ ) (\downarrow) (↓) |
|---|---|---|---|---|---|
| Top-1 | |||||
| LLAMA2-7B | Contriever | 47.63 | 35.33 | 16.37 | 0.67 |
| BGE-Base | 25.77 | 57.19 | 16.37 | 0.67 | |
| nv-embed-v2 | 18.21 | 64.75 | 16.37 | 0.67 | |
| GPT3.5 | Contriever | 42.26 | 48.76 | 8.44 | 0.54 |
| BGE-Base | 24.36 | 66.67 | 8.44 | 0.54 | |
| nv-embed-v2 | 17.67 | 73.36 | 8.44 | 0.54 | |
| GPT-40 | Contriever | 35.73 | 55.42 | 8.29 | 0.57 |
| BGE-Base | 20.57 | 70.57 | 8.29 | 0.57 | |
| nv-embed-v2 | 15.38 | 75.76 | 8.29 | 0.57 | |
| Top-3 | |||||
| LLAMA2-7B | Contriever | 36.56 | 46.40 | 16.37 | 0.67 |
| BGE-Base | 21.72 | 61.23 | 16.37 | 0.67 | |
| nv-embed-v2 | 16.81 | 66.15 | 16.37 | 0.67 | |
| GPT3.5 | Contriever | 30.91 | 60.11 | 8.44 | 0.54 |
| BGE-Base | 17.39 | 73.64 | 8.44 | 0.54 | |
| nv-embed-v2 | 13.16 | 77.87 | 8.44 | 0.54 | |
| GPT-40 | Contriever | 25.94 | 65.20 | 8.29 | 0.57 |
| BGE-Base | 13.67 | 77.47 | 8.29 | 0.57 | |
| nv-embed-v2 | 10.75 | 80.39 | 8.29 | 0.57 | |
| Top-5 | |||||
| LLAMA2-7B | Contriever | 36.78 | 46.17 | 16.37 | 0.67 |
| BGE-Base | 24.08 | 58.88 | 16.37 | 0.67 | |
| nv-embed-v2 | 19.93 | 63.03 | 16.37 | 0.67 | |
| GPT3.5 | Contriever | 27.45 | 63.57 | 8.44 | 0.54 |
| BGE-Base | 16.42 | 74.60 | 8.44 | 0.54 | |
| nv-embed-v2 | 13.21 | 77.81 | 8.44 | 0.54 | |
| GPT-40 | Contriever | 22.65 | 68.49 | 8.29 | 0.57 |
| BGE-Base | 12.79 | 78.36 | 8.29 | 0.57 | |
| nv-embed-v2 | 10.64 | 80.50 | 8.29 | 0.57 |
表1:各种RAG系统的RAG适应性评分。我们展示了涉及三种不同LLM、三种不同检索器和三种top-k设置的代表性能结果,共计27种模型组合。涵盖所有60种配置的全面实验详见附录C。
生成性能的作用,还提供了在相关和无关信息混杂的真实场景中模型行为的关键见解。图1展示了每个类别的示例,提供了我们评估方法捕捉的不同错误模式的视觉表示。
∑ b , o , m ∈ { 0 , 1 } ∣ G ( b , o , m ) ∣ ∣ D ∣ = 1 \sum_{b, o, m \in\{0,1\}} \frac{|G(b, o, m)|}{|D|}=1 b,o,m∈{0,1}∑∣D∣∣G(b,o,m)∣=1
5 实验
本节介绍了实验设置,包括研究中使用的数据集、模型和评估指标,随后是对实验结果的综合分析。
5.1 数据集
MIRAGE数据集旨在评估RAG系统在一系列问答任务中的表现。
它包含7,560个QA对,每个映射到一个包含37,800个文档块的检索池。对于每个查询,我们包含相关和无关的文档块混合,以测试系统过滤噪声和识别正确信息的能力。该数据集在不同领域和上下文中保持平衡,确保对检索和生成能力的全面评估。
5.2 模型
我们在RAG设置下评估了检索器和LLM的组合。使用的检索器包括各种尺寸和架构的模型,如BGE(Chen等人,2024a)、E5(Wang等人,2024)、Contriever(Izacard等人,2021)、GTE(Zhang等人,2024)和nv-embed-v2(Lee等人,2024)。对于生成,我们使用了五个LLM:Llama-2-7BChat、Llama-2-70B-Chat(Touvron等人,2023)、GPT-3.5-Turbo、GPT-4o和QWEN2-7B-Instruct(Yang等人,2024)。这些LLM代表了从中等规模模型到最先进系统的多样化
性能水平范围。
5.3 结果与分析
RAG系统性能:总结在表1中的结果显示,RAG系统的性能取决于检索块的数量和检索器与LLM的质量。一般来说,从Top-1增加到Top-3检索块会提高性能,因为包含Oracle块的可能性更高。然而,推进到Top-5检索通常会引入额外的噪声,导致某些配置的性能下降。这种效果在GPT-3.5-Turbo和Llama-2-7B-Chat等模型中尤为明显,当处理额外的噪声块时得分降低。
GPT-4o和nv-embed-v2的组合在所有检索设置下表现出强大的性能,即使在引入额外块的情况下也能保持高分。这表明模型具有过滤无关信息并专注于相关块的强大能力。相比之下,Llama-2模型的性能对噪声更为敏感,表明这些模型在检索结果包含无关信息时受益较少。
此外,尽管检索器性能会影响噪声脆弱性和上下文可接受性,但在未使用Oracle信息的情况下——即上下文不敏感性和上下文误解——与模型本身无关,无论给定的检索器或检索结果如何,这些情况始终保持一致。这表明正确利用上下文的能力完全取决于LLM的能力。因此,这种依赖关系解释了为什么在Oracle设置下整体性能无法达到完美分数。尽管这些指标不能区分检索器,但它们提供了对LLM弱点的宝贵见解。
检索器性能:包含37,800个独特文档块的MIRAGE也是评估检索器性能的宝贵工具。表2展示了各种检索模型在F1和NDCG分数方面的性能。结果显示,MIRAGE基准有效地区分了不同模型尺寸和架构的性能。更大、更新的模型,如nv-embed-v2,始终优于较小的检索器如BGE
| 模型 | F1 | 精确率 | 召回率 | NDCG |
|---|---|---|---|---|
| Top-1 | ||||
| BGE-S | 63.03 | 67.87 | 60.99 | 67.87 |
| BGE-B | 64.12 | 68.94 | 62.08 | 68.94 |
| BGE-L | 68.60 | 73.73 | 66.43 | 73.73 |
| E5-S | 64.32 | 68.97 | 62.35 | 68.97 |
| E5-B | 63.54 | 68.13 | 61.61 | 68.13 |
| E5-L | 71.38 | 76.65 | 69.14 | 76.65 |
| GTE-B | 59.40 | 63.94 | 57.50 | 63.94 |
| GTE-L | 63.29 | 67.98 | 61.33 | 67.98 |
| Contriever | 39.82 | 43.25 | 38.40 | 43.25 |
| E5-Mistral | 67.96 | 73.07 | 65.81 | 73.07 |
| NV | 73.92 | 79.40 | 71.60 | 79.40 |
| Top-3 | ||||
| BGE-S | 45.31 | 32.35 | 82.95 | 78.34 |
| BGE-B | 45.82 | 32.70 | 83.95 | 79.42 |
| BGE-L | 47.71 | 34.09 | 87.24 | 83.03 |
| E5-S | 45.00 | 31.95 | 82.93 | 78.92 |
| E5-B | 45.59 | 32.47 | 83.74 | 78.76 |
| E5-L | 48.47 | 34.53 | 88.93 | 85.55 |
| GTE-B | 44.32 | 31.64 | 81.20 | 75.58 |
| GTE-L | 46.42 | 33.14 | 84.99 | 79.36 |
| Contriever | 34.38 | 24.61 | 62.84 | 56.17 |
| E5-Mistral | 47.61 | 33.82 | 87.71 | 83.34 |
| NV | 50.77 | 36.35 | 92.56 | 88.05 |
| Top-5 | ||||
| BGE-S | 32.98 | 20.92 | 88.12 | 80.70 |
| BGE-B | 33.42 | 21.21 | 89.25 | 81.84 |
| BGE-L | 34.51 | 21.92 | 92.02 | 85.20 |
| E5-S | 32.76 | 20.69 | 88.26 | 81.41 |
| E5-B | 33.39 | 21.15 | 89.46 | 81.40 |
| E5-L | 34.69 | 21.97 | 92.97 | 87.40 |
| GTE-B | 32.66 | 20.72 | 87.31 | 78.37 |
| GTE-L | 33.84 | 21.49 | 90.32 | 81.76 |
| Contriever | 26.78 | 17.02 | 71.43 | 60.00 |
| E5-Mistral | 34.36 | 21.72 | 92.40 | 85.51 |
| NV | 36.38 | 23.18 | 96.41 | 89.78 |
表2:MIRAGE数据集上各种检索模型的性能比较。S、B和L分别表示小型、基础和大型模型变体。粗体表示每个指标和Top-k设置下的最佳性能。
和Contriever。这些结果与先前的研究一致,后者表明更先进的检索架构能带来更高的检索准确性。值得注意的是,nv-embed-v2模型始终检索到更多的相关块,从而提高了整体RAG系统性能,特别是在与高性能LLM结合时。
LLM性能:在固定上下文设置下,LLM的性能报告见表3。在此设置中,我们给LLM提供每个查询对应的5个文档块。此设置允许快速评估各种LLM的能力,而不依赖检索器,仅使用MIRAGE数据集。
GPT-4o和GPT-3.5-Turbo在没有外部上下文的情况下表现出最高的准确性,证明了在回答问题方面具有强大能力。尽管Llama-2-7B-Chat和QWEN2-7B-Instruct最初表现较低,但当与检索系统集成时显示出显著改进,突显了检索增强对较弱模型的积极影响。这些结果表明,检索可以有效帮助缩小小型模型与最先进的系统之间的性能差距。
| 模型 | 基础 | 混合 上下文 | Oracle 上下文 |
|---|---|---|---|
| LLAMA2-7B | 6.60 | 74.19 | 82.96 |
| LLAMA2-70B | 15.75 | 80.33 | 87.57 |
| Qwen2-7B | 7.39 | 8------ | |
| 3.74 | 90.22 | ||
| GPT3.5 | 31.96 | 87.27 | 91.02 |
| GPT4o | 45.82 \mathbf{4 5 . 8 2} 45.82 | KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …athbf{8 7 . 4 9 | 91.14 \mathbf{9 1 . 1 4} 91.14 |
表3:MIRAGE数据集上各种LLM的性能比较:基础设置评估了LLM在没有任何上下文情况下的内部知识。混合上下文设置评估了LLM利用相关块并忽
------略无关信息的能力。Oracle上下文测试了LLM是否能有效使用必要信息进行准确推理。分数以准确性报告。
总体而言,结果展示了MIRAGE通过稳健的指标驱动框架提供对RAG系统的细致评估的能力。这种方法揭示了不同模型组合在各种检索上下文级别上的优势和弱点。
6 结论
在本文中,我们介绍了MIRAGE,这是一个专门设计用于全面评估RAG系统性能的基准。通过广泛的实验,我们展示了MIRAGE能够提供关于检索模型和LLM之间交互的详细见解,揭示处理噪声上下文和整合外部知识时的优势和劣势。MIRAGE填补了现有基准留下的空白,为评估各种配置、检索器和LLM的RAG系统提供了灵活的框架。
局限性
尽管MIRAGE在RAG系统评估方面取得了显著进展,但有几个局限性需要在未来的工作中加以注意:
数据污染风险:由于使用公开可用的数据集构建MIRAGE,存在数据污染的潜在风险。在MIRAGE上评估的模型可能在预训练或微调过程中接触过部分数据集,从而导致评估不够准确。尽管我们通过仔细的数据分区和过滤来尽量减少这种风险,但完全消除是具有挑战性的。未来版本的MIRAGE应探索更严格的分区策略,例如时间分割,以确保训练和评估数据之间没有重叠。
单跳任务重点:虽然MIRAGE有意设计为使用最少计算资源测试多个系统,其轻量级特性仅限于单跳问答,答案来源于单一Oracle块。这简化了评估过程,但限制了需要多步推理的复杂任务。在实际场景中,模型通常需要整合来自多个来源的信息。为了更好地捕捉真实应用场景的复杂性,未来的MIRAGE版本应纳入需要跨多个文档块进行深度推理的多跳任务。
数据不平衡:MIRAGE中来自不同源数据集的QA对存在固有的数据不平衡。某些数据集比其他数据集更被代表,这可能会偏倚评估结果,特别是对于可能学习到频繁模式的检索器模型。解决未来版本MIRAGE中的这种不平衡将允许对检索器进行更均匀的评估,确保没有特定数据集不成比例地影响结果。
难度水平:最先进的模型在MIRAGE上表现出高性能,其中一些在基于Oracle的设置中超过了 90 % 90 \% 90%的准确性。这表明MIRAGE有效地评估了检索和生成,但对于Oracle设置来说,基准可能不够具有挑战性。然而,在更复杂、嘈杂的环境中,性能下降表明仍有改进空间,特别是在处理模糊或嘈杂上下文时。未来的工作可以通过引入更精细的对抗样例或任务复杂性来进一步增加挑战水平。
错误标签:尽管经过严格过滤和人工验证,MIRAGE数据集中可能存在一小部分错误标签
。在某些情况下,Oracle块可能被错误标记,或者答案标签可能与正确答案不完全一致。尽管这些错误只影响数据集的一小部分,但仍可能给评估引入噪声。未来对标签过程的改进应集中在减少这些错误上,以确保更稳健的数据集。
道德声明
MIRAGE基准是使用公开可用的数据集和资源构建的,所有这些都符合开放访问政策。我们确保在构建MIRAGE过程中未使用任何敏感或私人数据。此外,我们强调在评估框架中数据透明度和模型责任的重要性。尽管MIRAGE主要关注技术评估,但在现实应用中部署RAG系统的道德影响不应被忽视。我们鼓励MIRAGE用户在使用此基准评估的RAG系统部署时考虑社会影响、潜在偏差和公平性问题。该数据集仅供研究使用,应谨慎确保基于其构建的系统得到负责任地部署。
致谢
本工作得到了ICT Creative Consilience Program的支持,该计划由韩国政府(MSIT)资助的Institute of Information & Communications Technology Planning & Evaluation(IITP) 授予(IITP-2025-RS-2020II201819)。本工作得到了Institute for Information & communications Technology Promotion(IITP) 的支持,该机构由韩国政府(MSIT)资助(RS-2024-00398115,关于生成式AI产出可靠性和一致性研究)。本工作还得到了Institute of Information & communications Technology Planning & Evaluation(IITP) 的支持,该机构在Leading Generative AI Human Resources Development (IITP-2024-R2408111) 计划下由韩国政府(MSIT)资助。
参考文献
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman,
Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, 等人. 2023. Gpt-4 技术报告. arXiv 预印本 arXiv:2303.08774.
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, 等人. 2016. Ms marco: 一个人工生成的机器阅读理解数据集. arXiv 预印本 arXiv:1611.09268.
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, Zheng Liu. 2024a. Bge m3-embedding: 自我知识蒸馏实现的多语言、多功能、多粒度文本嵌入. arXiv 预印本 arXiv:2402.03216.
Jiawei Chen, Hongyu Lin, Xianpei Han, Le Sun. 2024b. 在检索增强生成中评估大型语言模型的基准. 第38届AAAI人工智能会议论文集, 第38卷, 第17754-17762页.
Cohere. 2024. Command r 模型. https://cohere. com/command. 访问日期: 2024-03-01.
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, Matt Gardner. 2019. Drop: 一个需要段落离散推理的阅读理解基准. arXiv 预印本 arXiv:1903.00161.
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, 等人. 2024. The llama 3 herd of models. arXiv 预印本 arXiv:2407.21783.
Shahul Es, Jithin James, Luis Espinosa-Anke, Steven Schockaert. 2023. Ragas: 检索增强生成的自动化评估. arXiv 预印本 arXiv:2309.15217.
Alexander R Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, Dragomir Radev. 2021. Summeval: 再次评估摘要评估. 计算语言学协会会刊, 9:391-409.
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li. 2024. 关于RAG满足LLMs的调查: 走向检索增强的大规模语言模型. 第30届ACM SIGKDD知识发现与数据挖掘国际会议论文集, 第64916501页.
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang. 2023. 大型语言模型的检索增强生成: 调查. arXiv 预印本 arXiv:2312.10997.
Sebastian Hofstätter, Jiecao Chen, Karthik Raman, Hamed Zamani. 2023. Fid-light: 高效且有效的检索增强文本生成. 第46届国际ACM SIGIR信息检索研究与发展会议论文集, 第1437-1447页.
Cheng-Yu Hsieh, Si-An Chen, Chun-Liang Li, Yasuhisa Fujii, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, Tomas Pfister. 2023. 工具文档使大型语言模型实现零样本工具使用. arXiv 预印本 arXiv:2308.00675.
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, Edouard Grave. 2021. 使用对比学习进行无监督密集信息检索. arXiv 预印本 arXiv:2112.09118.
Gautier Izacard 和 Edouard Grave. 2021. 利用生成模型结合段落检索进行开放式领域问答. 第16届欧洲计算语言学协会年会论文集: 主要卷, 第874-880页, 线上. 计算语言学协会.
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, Pascale Fung. 2023. 通过自我反思缓解LLM幻觉. 第十二届计算语言学学会年度会议论文集: EMNLP 2023, 第1827-1843页.
Mandar Joshi, Eunsol Choi, Daniel S Weld, Luke Zettlemoyer. 2017. Triviaqa: 一个大规模远距离监督的阅读理解挑战数据集. arXiv 预印本 arXiv:1705.03551.
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. 2020. 开放域问答的密集段落检索. arXiv 预印本 arXiv:2004.04906.
Jungo Kasai, Keisuke Sakaguchi, yoichi takahashi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir Radev, Noah A Smith, Yejin Choi, Kentaro Inui. 2023. 实时QA: 当前的答案是什么? 第36卷, 第49025-49043页. Curran Associates, Inc.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, 等人. 2019. Natural questions: 一个问答研究的基准. 计算语言学协会会刊, 7:453466.
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, Ion Stoica. 2023. 带有分页注意力的大型语言模型服务的高效内存管理. 第29届操作系统原理研讨会论文集, 第611-626页.
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping. 2024. Nv-embed: 改进的技术用于训练作为通用嵌入模型的LLM. arXiv 预印本 arXiv:2405.17428.
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, 等人. 2020. 检索增强生成用于知识密集型NLP任务. 神经信息处理系统进展, 33:9459-9474.
Shaobo Li, Xiaoguang Li, Lifeng Shang, Xin Jiang, Qun Liu, Chengjie Sun, Zhenzhou Ji, Bingquan Liu. 2021. Hopretriever: 从维基百科检索跳跃以回答复杂问题. 第35届AAAI人工智能会议论文集, 第13279-13287页.
Yi Liu, Lianzhe Huang, Shicheng Li, Sishuo Chen, Hao Zhou, Fandong Meng, Jie Zhou, Xu Sun. 2023. Recall: 大型语言模型对外部反事实知识鲁棒性的基准. arXiv 预印本 arXiv:2311.08147.
Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, KaiWei Chang, Ying Nian Wu, Song-Chun Zhu, Jianfeng Gao. 2023. Chameleon: 大型语言模型的即插即用组合推理. 神经信息处理系统进展, 第36卷, 第43447-43478页. Curran Associates, Inc.
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, Hannaneh Hajishirzi. 2022. 何时不应信任语言模型: 探究参数化和非参数化记忆的有效性. arXiv 预印本 arXiv:2212.10511.
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, Hannaneh Hajishirzi. 2023. 何时不应信任语言模型: 探究参数化和非参数化记忆的有效性. 第61届计算语言学协会年会论文集(第1卷: 长论文), 第9802-9822页, 加拿大多伦多. 计算语言学协会.
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, 等人. 2022. 文本和代码嵌入通过对比预训练. arXiv 预印本 arXiv:2201.10005.
Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Jiayang Cheng, Cunxiang Wang, Shichao Sun, Huanyu Li, 等人. 2024. Ragchecker: 诊断检索增强生成的细粒度框架. arXiv 预印本 arXiv:2408.08067.
Jon Saad-Falcon, Omar Khattab, Christopher Potts, Matei Zaharia. 2023. Ares: 检索增强生成系统的自动化评估框架. arXiv 预印本 arXiv:2311.09476.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, 等人. 2023. Llama 2: 开放的基础和微调聊天模型. arXiv 预印本 arXiv:2307.09288.
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, 等人. 2023. Freshllms: 使用搜索引擎增强刷新大型语言模型. arXiv 预印本 arXiv:2310.03214.
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei. 2024. 多语言e5文本嵌入: 技术报告. arXiv 预印本 arXiv:2402.05672.
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, Yu Su. 2024. 适应性变色龙还是顽固树懒: 揭示大型语言模型在知识冲突中的行为. 第十二届国际学习表示会议.
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, 等人. 2024. Qwen2技术报告. arXiv 预印本 arXiv:2407.10671.
Yi Yang, Wen-tau Yih, Christopher Meek. 2015. Wikiqa: 开放域问答的一个挑战数据集. 第2015年经验方法自然语言处理会议论文集, 第2013-2018页.
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, Christopher D Manning. 2018. Hotpotqa: 一个多样化的、可解释的多跳问答数据集. arXiv 预印本 arXiv:1809.09600.
Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, Meng Jiang. 2023a. 生成而非检索: 大型语言模型是强大的上下文生成器. 第十一届国际学习表示会议.
Wenhao Yu, Meng Jiang, Peter Clark, Ashish Sabharwal. 2023b. Ifqa: 一个在反事实假设下的开放域问答数据集. arXiv 预印本 arXiv:2305.14010.
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, 等人. 2024. mgte: 泛化长上下文文本表示和重排序模型用于多语言文本检索. arXiv 预印本 arXiv:2407.19669.
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Bin Cui. 2024. 检索增强生成用于AI生成内容: 调查. CoRR, abs/2402.19473.
问题 : John Mayne的职业是什么?
回答 :
模型响应
我很抱歉,但我没有相关信息…
表4:基础设置的推理提示。
A 模型提示的细节
表4、5和6分别展示了基础、Oracle和混合设置使用的提示。我们采用了简单的提示以最小化指令的影响,并专注于评估模型的表现。这些提示适用于实验中使用的所有模型。在3.4节验证过程中,对于llama-3.1-8B-Instruct模型,每个块都像在Oracle设置中一样逐个给出。
对于3.4节描述的支持标签提取过程,我们使用了表7所示的提示。为确定每个映射块的相关性,提取了所有37,800个块的标签,这些块映射到了7,560个查询。为了避免块之间的相互作用效应,每个块都是独立评估的。"
B 数据分布的细节
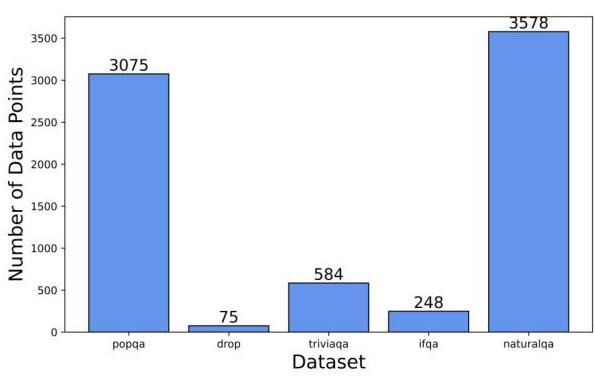
图3:每组数据的数据点数量
图3展示了MiRAGE中每个源数据集派生的数据点数量。这些数据集包括PopQA、NQ、IfQA、DROP和TriviaQA。
NQ贡献了最多的数据点,总计3,578个。这占据了整体数据集的很大一部分,反映了NQ的广泛覆盖。
系统提示
你是有用的助手。
用户提示
问题 : John Mayne的职业是什么?
上下文 : 苏格兰印刷商、记者和诗人John Mayne(1759-1836)是一位出生于邓弗里斯的苏格兰印刷商、记者和诗人。1780年,他的诗作"The Siller Gun"以原始形式出现在爱丁堡Walter Ruddiman出版的"Ruddiman’s Magazine"中。这是一首关于邓弗里斯古老射击"Siller Gun"习俗的幽默作品。他还写了一首关于"Halloween"的诗作,影响了罗伯特·彭斯1785年的诗作"Halloween"。Mayne还创作了名为"Helen of Kirkcomtel"的民谣。他的诗句受到沃尔特·司各特的赞赏。生活经历。他于1759年3月26日出生于邓弗里斯。在当地文法学校接受教育后,他成为"Dumfries Journal"办公室的一名印刷工。1782年,他带着家人前往格拉斯哥,在Foulis兄弟的出版社工作了五年。1787年,他定居伦敦,先是作为印刷工,后来成为晚间报纸"The Star"的老板和联合编辑,在其中他发表了诗歌。他于1836年3月14日在伦敦利森格罗夫去世。作品。Mayne在邓弗里斯创作了诗歌,自1777年后他向爱丁堡的"Ruddiman’s Weekly Magazine"投稿诗歌。1807年至1817年间,他的几首歌词出现在"Gentleman’s Magazine"中
回答 :
打印机、记者、诗人
表5:Oracle设置的推理提示。
PopQA提供了3,075个数据点,略少于NQ,但仍然是MiRAGE的重要组成部分。
TriviaQA贡献了584个数据点,为数据集提供了适度的补充。
IfQA包含248个数据点,较小的贡献表明选择性包含。
DROP提供的最少,只有75个数据点,突显了其更为受限的角色。
图4突出显示了与每个数据点相关的相关块数量。支持和正确标签的对齐定义了相关性的数量。尽管数量较少,但查询中有4到5个相关块的情况是所有块均来自参考文章,整个文档可以推断出查询。这样的例子见表8。
C 额外实验
表9、10和11提供了详细的实验结果,涵盖了四种LLM和五种检索器在三种top-k设置下的表现。这些表格共同展示了总共60种配置,突出了各种RAG系统的RAG适应性。
D 实验细节
我们在四个RTX A6000 GPU上进行了所有实验,并利用vLLM框架加速推理(Kwon等人,2023)。在我们的工作中,我们使用GPT-4o(gpt-4o-2024-08-06)作为写作助手。AI助手仅用于写作相关活动,如语法检查、优化笨拙表达和翻译我们的手稿。
实验中使用的模型及其近似参数大小如下所示:
- BGE-S: 33M 参数
-
- BGE-B: 110M 参数
-
- BGE-L: 335M 参数
-
- Contriever: 110M 参数
-
- NV-embed-v2: 7B 参数
-
- E5-S: 33M 参数
-
系统提示
你是一个准确可靠的AI助手,可以通过外部文档的帮助回答问题。请注意,外部文档可能包含噪声或事实错误的信息。如果文档中的信息包含正确答案,你将生成’Supported’。如果文档中的信息不包含答案,你将生成’Not supported.’
用户提示
文档 : 苏格兰印刷商、记者和诗人John Mayne(1759-1836)是一位出生于邓弗里斯的苏格兰印刷商、记者和诗人。1780年,他的诗作"The Siller Gun"以原始形式出现在爱丁堡Walter Ruddiman出版的"Ruddiman’s Magazine"中。这是一首关于邓弗里斯古老射击"Siller Gun"习俗的幽默作品。他还写了一首关于"Halloween"的诗作,影响了罗伯特·彭斯1785年的诗作"Halloween"。Mayne还创作了名为"Helen of Kirkcomel"的民谣。他的诗句受到沃尔特·司各特的赞赏。生活经历。他于1759年3月26日出生于邓弗里斯。在当地文法学校接受教育后,他成为"Dumfries Journal"办公室的一名印刷工。1782年,他带着家人前往格拉斯哥,在Foulis兄弟的出版社工作了五年。1787年,他定居伦敦,先是作为印刷工,后来成为晚间报纸"The Star"的老板和联合编辑,在其中他发表了诗歌。他于1836年3月14日在伦敦利森格罗夫去世。作品。Mayne在邓弗里斯创作了诗歌,自1777年后他向爱丁堡的"Ruddiman’s Weekly Magazine"投稿诗歌。1807年至1817年间,他的几首歌词出现在"Gentleman’s Magazine"中 问题 : John Mayne的职业是什么? 回答 : 记者
模型响应
Supported
表7:支持标签提取的推理提示。
- E5-B: 110M 参数
-
- E5-L: 335M 参数
-
- E5-Mistral: 7B 参数
-
- GTE-B: 110M 参数
-
- GTE-L: 335M 参数
-
- Llama2-7B: 7B 参数
-
- Llama2-70B: 70B 参数
-
- Llama3-8B: 8B 参数
-
- Qwen2-7B: 7B 参数
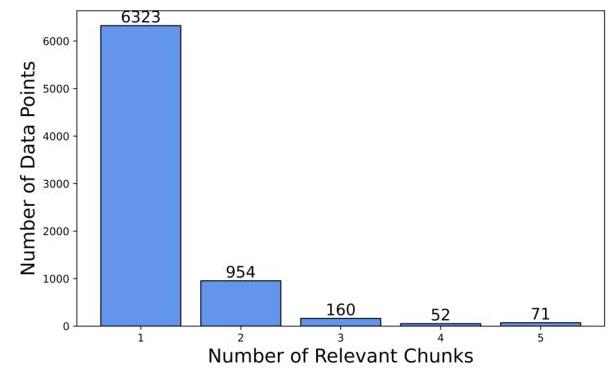
图4:每个相关块的数据点数量
E 人工验证过程
对于人工验证,我们雇佣了三位注释者,他们要么是母语为英语的人士,要么具备计算语言学背景。注释者被提供详细的指南并接受了简短的培训阶段以确保标注的一致性。每位注释者被给予查询、答案跨度以及对应的文档块,包括标题,如图5所示。为了视觉辅助,答案跨度用’****'高亮显示,以引起对潜在相关部分的注意。然而,注释者被指示答案跨度的存在并不直接表示相关性。
注释者A、B和C分别在500个案例中同意模型标签的数量分别为467(93.4%)、477(95.4%)和489(97.8%)。使用Cohen’s Kappa测量的注释者间的成对一致性分别为A和B之间0.83、A和C之间0.83以及B和C之间0.89,表明强一致性。使用Krippendorff’s Alpha测量的整体注释者一致性为0.8512,进一步验证了注释过程的可靠性。注释者因他们的努力获得了公平补偿,且该过程遵守了标准伦理准则,包括获得知情同意。
图5展示了此过程中使用的命令行注释界面。界面显示查询、潜在答案跨度及对应的文档块。注释者可以直接在界面内输入他们的标签,确保高效且流畅的工作流程。
— 处理索引:837,100中的第16个 —
数据集样本:
‘谁是《新》的制作人?’
[‘Mark Ronson’, ‘Mark Daniel Ronson’, ‘DJ Ronson’]
块1:
‘新(保罗·麦卡特尼歌曲)’
(‘“新”是由保罗·麦卡特尼创作的一首歌。它最初由麦卡特尼录制并由英国音乐家马克·朗森制作,用于麦卡特尼的第十六张录音室专辑《新》,并在专辑中作为第六首曲目出现。这首歌在2013年8月28日提前在iTunes商店发布后可供下载。2013年9月2日,这首歌作为单曲发布,并在亚马逊独家发售。这首歌于2013年8月28日在iTunes商店首次亮相,同时正式揭晓了《新》专辑同一天。这首单曲在日本电台获得了大量播放,成为日本Hot 100排行榜上的第四大热门歌曲。这首单曲加入了BBC Radio 2的播放列表,同名专辑成为了“本周记录”。这首歌出现在2013年动画电影《美食从天而降2》的开头和结尾字幕中。反响。“新”受到了评论家和音乐媒体的积极评价。除了被选为BBC Radio 2的“本周记录”并被列入“A-list”,这首歌还被称赞为“每日记录”,赞扬了它的“天真乐观,不可抗拒的旋律”和“编排的流行安排”。《滚石》杂志的威尔·赫尔曼赞扬了它“活泼的羽管键琴丰富的旋律”,给出了四星评级,并将其与披头士的“Got to Get You into My Life”相提并论,这一观点得到了《每日电讯报》的认同,后者形容它为“欢快的披头士风格跺脚”。’) 输入块1的标签(0或1,或输入’exit’退出):
图5:此过程中使用的命令行屏幕。
— 处理索引:837,100中的第16个 —
数据集样本:
‘谁是《新》的制作人?’
[‘Mark Ronson’, ‘Mark Daniel Ronson’, ‘DJ Ronson’]
块1:
‘新(保罗·麦卡特尼歌曲)’
(‘“新”是由保罗·麦卡特尼创作的一首歌。它最初由麦卡特尼录制并由英国音乐家马克·朗森制作,用于麦卡特尼的第十六张录音室专辑《新》,并在专辑中作为第六首曲目出现。这首歌在2013年8月28日提前在iTunes商店发布后可供下载。2013年9月2日,这首歌作为单曲发布,并在亚马逊独家发售。这首歌于2013年8月28日在iTunes商店首次亮相,同时正式揭晓了《新》专辑同一天。这首单曲在日本电台获得了大量播放,成为日本Hot 100排行榜上的第四大热门歌曲。这首单曲加入了BBC Radio 2的播放列表,同名专辑成为了“本周记录”。这首歌出现在2013年动画电影《美食从天而降2》的开头和结尾字幕中。反响。“新”受到了评论家和音乐媒体的积极评价。除了被选为BBC Radio 2的“本周记录”并被列入“A-list”,这首歌还被称赞为“每日记录”,赞扬了它的“天真乐观,不可抗拒的旋律”和“编排的流行安排”。《滚石》杂志的威尔·赫尔曼赞扬了它“活泼的羽管键琴丰富的旋律”,给出了四星评级,并将其与披头士的“Got to Get You into My Life”相提并论,这一观点得到了《每日电讯报》的认同,后者形容它为“欢快的披头士风格跺脚”。’) 输入块1的标签(0或1,或输入’exit’退出):
图5:用于注释过程的命令行屏幕。
| 查询 |
|---|
| Anthony Sharpe的职业是什么? |
| 答案 |
| [演员, 女演员, 演员们, 女演员们] |
| 上下文 |
| 1. 英国演员(1915-1984) |
| Dennis Anthony John Sharp (1915年6月16日 - 1984年7月23日) |
| 是一位英国演员、作家和导演。舞台生涯。 |
| Anthony Sharp毕业于伦敦音乐与戏剧艺术学院 |
| (LAMDA),并在舞台上…开始了他的职业生涯 |
| 2. 在那里他于1958年在《Much Ado About Nothing》中扮演Benedick |
| 并在第二年扮演Twelfth Night中的Malvolio。 |
| 他在1970年代重新加入公司,出演了诸如 |
| 《Love’s Labour’s Lost》和《The Man of…》等剧目 |
| 3. 他的荣誉包括《Any Other Business》 |
| (威斯敏斯特剧院1958),《Caught Napping》(皮卡迪利剧院1959),《Wolf’s Clothing》(Strand Theatre 1959), |
| 《Billy Bunter Flies East》(维多利亚宫1959),《The…》 |
| 4. 他唯一的主演是在Pete Walker 1975年的恐怖片《House of Mortal Sin》中 |
| 扮演杀人牧师Father Xavier Meldrum。他最后出演的电影 |
| 是他饰演外交大臣Lord Ambrose,… |
| 5. 1974年,他在广播版《Steptoe and Son》中出演牧师, |
| 1978年他既是餐厅宇宙尽头的侍者Garkbit |
| ,也是第五套件《Great Prophet Zarquon》中的伟大先知… |
表8:包含5个相关块的数据样本。这些示例包括一般问题的查询,使得答案可以在整个维基百科文章中推断出来。
| LLM | 检索器 | 噪声 脆弱性 ( ↓ ) (\downarrow) (↓) | 上下文 可接受性 ( ↑ \uparrow ↑ ) | 上下文 不敏感性 ( ↓ ) (\downarrow) (↓) | 上下文 误解 ( ↓ ) (\downarrow) (↓) |
|---|---|---|---|---|---|
| Top-1 | |||||
| GPT3.5 | BGE-S | 25.69 | 65.33 | 8.44 | 0.54 |
| BGE-B | 24.36 | 66.67 | 8.44 | 0.54 | |
| BGE-L | 21.67 | 69.35 | 8.44 | 0.54 | |
| Contriever | 42.26 | 48.76 | 8.44 | 0.54 | |
| NV | 17.66 | 73.36 | 8.44 | 0.54 | |
| GPT4o | BGE-S | 22.05 | 69.09 | 8.29 | 0.57 |
| BGE-B | 20.57 | 70.57 | 8.29 | 0.57 | |
| BGE-L | 18.83 | 72.31 | 8.29 | 0.57 | |
| Contriever | 35.73 | 55.42 | 8.29 | 0.57 | |
| NV | 15.38 | 75.76 | 8.29 | 0.57 | |
| BGE-B | 25.77 | 57.19 | 16.37 | 0.67 | |
| BGE-L | 22.80 | 60.16 | 16.37 | 0.67 | |
| Contriever | 47.63 | 35.33 | 16.37 | 0.67 | |
| NV | 18.21 | 64.75 | 16.37 | 0.67 | |
| Qwen2-7B | BGE-S | 29.1 | 61.11 | 9.41 | 0.37 |
| BGE-B | 27.75 | 62.46 | 9.41 | 0.37 | |
| BGE-L | 24.29 | 65.93 | 9.41 | 0.37 | |
| Contriever | 51.14 | 39.07 | 9.41 | 0.37 | |
| NV | 19.04 | 71.17 | 9.41 | 0.37 |
表9:RAG系统Top1性能
| LLM | 检索器 | 噪声 脆弱性 ( ↓ ) (\downarrow) (↓) | 上下文 可接受性 ( ↑ ) (\uparrow) (↑) | 上下文 不敏感性 ( ↓ ) (\downarrow) (↓) | 上下文 误解 ( ↓ ) (\downarrow) (↓) |
|---|---|---|---|---|---|
| Top-3 | |||||
| GPT3.5 | BGE-S | 18.52 | 72.50 | 8.44 | 0.54 |
| BGE-B | 17.39 | 73.63 | 8.44 | 0.54 | |
| BGE-L | 16.00 | 75.02 | 8.44 | 0.54 | |
| Contriever | 30.91 | 60.11 | 8.44 | 0.54 | |
| NV | 13.16 | 77.87 | 8.44 | 0.54 | |
| GPT4o | BGE-S | 14.02 | 77.12 | 8.29 | 0.57 |
| BGE-B | 13.67 | 77.47 | 8.29 | 0.57 | |
| BGE-L | 12.38 | 78.77 | 8.29 | 0.57 | |
| Contriever | 25.94 | 65.20 | 8.29 | 0.57 | |
| NV | 10.75 | 80.39 | 8.29 | 0.57 | |
| LLAMA2-7B | BGE-S | 22.32 | 60.64 | 16.37 | 0.67 |
| BGE-B | 21.72 | 61.23 | 16.37 | 0.67 | |
| BGE-L | 20.32 | 62.63 | 16.37 | 0.67 | |
| Contriever | 36.56 | 46.40 | 16.37 | 0.67 | |
| NV | 16.81 | 66.15 | 16.37 | 0.67 | |
| Qwen2-7B | BGE-S | 21.88 | 68.33 | 9.41 | 0.37 |
| BGE-B | 21.04 | 69.18 | 9.41 | 0.37 | |
| BGE-L | 19.33 | 70.88 | 9.41 | 0.37 | |
| Contriever | 37.09 | 53.13 | 9.41 | 0.37 | |
| NV | 15.83 | 74.39 | 9.41 | 0.37 |
表10:RAG系统Top3性能
| LLM | 检索器 | 噪声 脆弱性 ( ↓ ) (\downarrow) (↓) | 上下文 可接受性 ( ↑ ) (\uparrow) (↑) | 上下文 不敏感性 ( ↓ ) (\downarrow) (↓) | 上下文 误解 ( ↓ ) (\downarrow) (↓) |
|---|---|---|---|---|---|
| Top-5 | |||||
| GPT3.5 | BGE-S | 17.36 | 73.66 | 8.44 | 0.54 |
| BGE-B | 16.42 | 74.60 | 8.44 | 0.54 | |
| BGE-L | 15.36 | 75.66 | 8.44 | 0.54 | |
| Contriever | 27.45 | 63.57 | 8.44 | 0.54 | |
| NV | 13.21 | 77.81 | 8.44 | 0.54 | |
| GPT4o | BGE-S | 13.17 | 77.97 | 8.29 | 0.57 |
| BGE-B | 12.79 | 78.35 | 8.29 | 0.57 | |
| BGE-L | 11.78 | 79.36 | 8.29 | 0.57 | |
| Contriever | 22.65 | 68.49 | 8.29 | 0.57 | |
| NV | 10.64 | 80.50 | 8.29 | 0.57 | |
| LLAMA2-7B | BGE-S | 24.12 | 58.84 | 16.37 | 0.67 |
| BGE-B | 24.08 | 58.88 | 16.37 | 0.67 | |
| BGE-L | 23.19 | 59.77 | 16.37 | 0.67 | |
| Contriever | 36.78 | 46.17 | 16.37 | 0.67 | |
| NV | 19.93 | 63.03 | 16.37 | 0.67 | |
| Qwen2-7B | BGE-S | 22.5 | 67.71 | 9.41 | 0.37 |
| BGE-B | 21.82 | 68.40 | 9.41 | 0.37 | |
| BGE-L | 20.15 | 70.06 | 9.41 | 0.37 | |
| Contriever | 34.46 | 55.76 | 9.41 | 0.37 | |
| NV | 17.61 | 72.60 | 9.41 | 0.37 |
表11:RAG系统Top5性能
参考论文:https://arxiv.org/pdf/2504.17137
2 { }^{2} 2 https://dumps.wikimedia.org/
 ↩︎
↩︎


















 3392
3392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











