






冯昊洋*
杜克大学,美国北卡罗来纳州达勒姆,brianmaga2024@gmail.com
戴燕军
布兰迪斯大学,美国马萨诸塞州沃尔瑟姆,Yanjudai0000@gmail.com
高远
波士顿大学,美国马萨诸塞州波士顿,xyan56379@gmail.com
摘要:尽管大型语言模型在实验环境中展示了个性化广告推荐的潜力,但在实际操作中,如何将广告推荐系统与用户隐私保护和数据安全等措施相结合仍然是一个值得深入探讨的领域。为此,本文研究了大型语言模型在数字广告中的个性化风险及监管策略。本研究首先概述了大型语言模型(LLM)的基本原理,特别是基于Transformer架构的自注意力机制,以及如何使模型理解和生成自然语言文本。然后,结合BERT(双向编码器表示从Transformer)模型和注意力机制构建了一个用于个性化广告推荐和用户因素风险保护的算法模型。具体步骤包括:数据收集与预处理、特征选择与构建、使用如BERT等大型语言模型进行广告语义嵌入,以及基于用户画像的广告推荐。随后,通过本地模型训练和数据加密确保用户隐私的安全性,避免个人数据泄露。本文设计了一项基于BERT大型语言模型的个性化广告推荐实验,并使用真实用户数据进行验证。实验结果表明,基于BERT的广告推送可以有效提高广告的点击率和转化率。同时,通过本地模型训练和隐私保护机制,在一定程度上降低了用户隐私泄露的风险。
关键词:大型语言模型;个性化广告;隐私保护;BERT模型;数据安全
1. 引言
随着个性化广告推荐技术的广泛应用,用户隐私问题也引起了越来越多的关注。在追求精准推荐的同时,如何平衡个性化与用户隐私保护之间的矛盾已成为当前研究和实践中的主要挑战。为了解决这一问题,本研究提出了一种基于BERT模型的个性化广告推荐方法,并结合本地训练和加密技术保护用户隐私。通过本地训练,用户数据无需上传到服务器,从而有效避免了数据泄露的风险。同时,结合加密技术,确保了用户隐私信息在训练过程中的充分保护,进一步提高了广告推荐系统的隐私安全性。
本文首先讨论了数字广告中的个性化推荐技术及其面临的隐私保护挑战,并分析了大型语言模型在广告推荐中的应用前景和问题。接着,提出了一种基于BERT模型的个性化广告推荐方法,结合本地训练和加密技术提高用户隐私保护。随后,详细描述了实验设计和数据处理方法,并展示了实验结果,验证了该方法在隐私保护和推荐效果方面的优势。最后,文章总结了研究的主要贡献,并展望了未来的研究方向和技术发展。
2. 相关工作
在快速发展的数字广告环境中,人工智能(AI)的兴起正在重新定义个性化策略,同时也带来了许多挑战和风险。基于现有文献,本文将探讨大型语言模型在数字广告中的个性化风险及其监管策略。Chen等人通过20次深入访谈收集数据,并采用现象学分析方法。他们发现,人们对语音助手人工智能(AI)的看法集中在功能性、沟通、适应性、关系和隐私方面[1]。Wach等人通过批判性文献回顾提出了生成式人工智能(GAI)在管理和经济领域的负面影响,并总结了七大主要威胁:人工智能市场的缺乏监管、低质量内容、自动化导致失业、个人数据和隐私侵犯、社会操控、加剧的社会经济不平等以及人工智能技术压力[2]。吴淑瑞、黄欣怡和卢定新[13]通过提出一个知识增强框架,将大型语言模型的应用扩展到心理健康领域,识别社交媒体中的危机干预信号,提供了关于高敏感领域(如数字广告)负责任个性化策略的新见解。Bulchand-Gidumal等人采用扎根理论方法探讨了人工智能对酒店营销功能的影响。结果确定了与人工智能在酒店营销中的贡献相关的十个趋势,涵盖四个主要主题:人工智能重塑内部流程和程序、改善与利益相关者的关系、支持组织网络整合和分销模式转型、通过智能预测客户服务和增强产品设计转变客户流程和服务[3]。Kim等人研究了监管重点和隐私担忧对消费者对高度个性化聊天机器人广告反应的影响。通过两项实验研究,发现以促销为导向的消费者更有可能接受并积极回应高度个性化的广告[4]。Kronemann等人借鉴个性化-隐私悖论(PPP)和隐私计算理论(PCT),提出人工智能的人格化和个性化有助于提高消费者对数字助手的态度和信息披露意愿,而隐私担忧则对态度和信息披露产生负面影响[5]。Bhattacharya等人通过在线调查收集了355份有效问卷,并使用R编程进行分析。结果显示,原产国(COO)显著影响消费者的隐私、信任和购买意图[6]。
Raji等人全面回顾了美国和非洲的数字营销实践,揭示了其相似性、差异性和新兴趋势。非洲的数字营销结合了传统和现代方法,各地在面临基础设施挑战的同时,也在努力利用数字平台展示其丰富的文化和自然资源吸引力[7]。Matthews和Tucker认为,其在许多传统营销应用中的有效性可能有限。这一观点揭示了区块链技术、数据和隐私之间的相互作用。由于其特性,如果不限制地用于营销,区块链可能会带来重大的隐私风险[8]。Ke和Sudhir通过动态两期模型研究了《通用数据保护条例》(GDPR)的影响,发现尽管数据安全法规对公司处以罚款,但可以在低泄露风险的情况下提高用户同意率[9]。Paul等人探讨了基于人工智能的聊天生成预训练变压器的多维益处和潜在弊端,并强调需要鼓励新颖的研究。ChatGPT(聊天生成预训练变压器)面临的问题包括消费者福利、偏见、隐私和伦理[10]。Goldberg指出,现代网站依赖个人数据来改进内容和营销,而欧盟的《通用数据保护条例》旨在保护用户隐私并增加获取个人数据的难度[11]。Lim等人研究了380名数字原住民样本,发现在线广告的易用性、实用性、娱乐性、可信度、设计和个性化对其态度有积极影响,但广告的安全性并未显著影响其态度,显示出数字原住民对数字环境的信心[12]。现有研究的局限性在于,大多数研究专注于个别领域或特定群体的视角,缺乏对跨行业、跨区域和多利益相关者之间复杂互动的全面考虑。
3. 方法
3.1 大型语言模型概述
大型语言模型(LLM)是一种基于深度学习和自然语言处理(NLP)技术的人工智能模型,能够理解和生成自然语言文本。其核心原理是利用Transformer架构通过自注意力机制捕捉文本中的长距离依赖关系,从而生成具有语义理解能力的文本。
大型语言模型的训练分为两个主要阶段:预训练和微调。在预训练阶段,模型通过大量无监督语料库学习掌握语言的基本规律。在微调阶段,根据特定任务进一步优化模型以适应实际应用场景。
3.2 算法应用的实现过程
3.2.1 数据收集与预处理
个性化广告推荐系统的实现需要收集和处理用户和广告数据,包括用户行为数据、兴趣数据、社交关系数据,以及广告内容、结构、语言风格等数据。具体步骤如下:(1) 从数据库和网站等数据源获取原始数据并进行清洗,以确保数据的正确性和完整性。(2) 实现数据转换和集成,统一多源多格式数据的表达方式,并在此基础上进行特征筛选和构建,提取具有典型意义的特征。(3) 对图像进行缩放和归一化处理,以减少图像元素之间的比例差异。(4) 将预处理后的数据划分为训练集和测试集,并进行必要的平衡,以确保两个数据集中样本的均匀分布。通过上述工作,获得高质量的数据,为后续研究奠定坚实基础。
3.2.2 BERT模型的训练
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的大型语言模型。它在文本数据向量编码任务中表现出色,能够学习丰富的上下文信息,并更好地处理词汇的多义性和复杂关系。因此,我们选择BERT大型语言模型来实现广告个性化集合的语义嵌入。基于BERT的广告推送解决方案集合的语义嵌入主要由以下三个部分组成:(1) 解决方案集合嵌入层将文本解决方案集合分解为多个标记,并将这些标记转换为固定维度的向量表示;(2) Transformer编码器通过多层Transformer结构深入理解和学习解决方案集合中每个解决方案的上下文语义信息,并对其进行编码;(3) 输出层输出每个行程计划的解决方案集合的嵌入向量,并确保所有嵌入向量的长度一致以便于后续分类模型的使用。
(1) 解决方案集合嵌入层
广告文案被转换为BERT可处理的标记序列,并为每个标记生成固定维度的向量表示。
假设广告文案为 S = [ s 1 , s 2 , ⋯ , s n ] S=\left[s_{1}, s_{2}, \cdots, s_{n}\right] S=[s1,s2,⋯,sn],其中 s i s_{i} si 表示文案中的单个单词或子词(标记)。BERT模型首先通过嵌入层将每个标记转换为向量 e ( s i ) e\left(s_{i}\right) e(si),并通过位置编码保留序列中的位置信息。
标记嵌入公式如下:
e ( s i ) = W e m b ⋅ s i e\left(s_{i}\right)=W_{e m b} \cdot s_{i} e(si)=Wemb⋅si
其中, W emb W_{\text {emb }} Wemb 是BERT模型中学习到的词嵌入矩阵, e ( s i ) e\left(s_{i}\right) e(si) 是单词 s i s_{i} si 的向量表示。
由于Transformer本身没有位置顺序的概念,需要添加位置编码。
e p o s ( s i ) = e ( s i ) + p i e_{p o s}\left(s_{i}\right)=e\left(s_{i}\right)+p_{i} epos(si)=e(si)+pi
其中,
P
i
P_{i}
Pi 是位置 i 对应的编码向量,
e
pos
(
s
i
)
e_{\text {pos }}\left(s_{i}\right)
epos (si) 是带有位置信息的词向量。
(2) Transformer编码器
使用多层Transformer编码器处理标记之间的关系,深入理解广告文案的上下文信息,并为每个标记生成上下文向量表示。
BERT模型使用多层Transformer编码器进行处理。在每一层中,使用自注意力机制计算标记之间的相关性。给定一个标记,通过计算与其他所有标记的相关性(即注意力权重)获得其上下文表示。
(3) 自注意力机制
对于每个输入标记 S S S,我们首先计算其查询、键和值向量:
Q i = W Q ⋅ e p o s ( s i ) K i = W k ⋅ e p o s ( s i ) V i = W V ⋅ e p o s ( s i ) \begin{aligned} & Q_{i}=W_{Q} \cdot e_{p o s}\left(s_{i}\right) \\ & K_{i}=W_{k} \cdot e_{p o s}\left(s_{i}\right) \\ & V_{i}=W_{V} \cdot e_{p o s}\left(s_{i}\right) \end{aligned} Qi=WQ⋅epos(si)Ki=Wk⋅epos(si)Vi=WV⋅epos(si)
其中,
W
Q
,
W
K
,
W
V
W_{Q}, W_{K}, W_{V}
WQ,WK,WV 是映射词嵌入到查询、键和值空间的训练矩阵。
然后,计算查询向量与键向量之间的相似度(点积),并通过softmax函数生成注意力权重。
α i j = exp ( Q i , K j ) ∑ k exp ( Q i , K k ) \alpha_{i j}=\frac{\exp \left(Q_{i}, K_{j}\right)}{\sum_{k} \exp \left(Q_{i}, K_{k}\right)} αij=∑kexp(Qi,Kk)exp(Qi,Kj)
其中, α i j \alpha_{i j} αij 表示标记 s i s_{i} si 和 s j s_{j} sj 之间的注意力权重。通过这一过程,模型可以自适应地关注与目标标记相关的上下文信息。
最终,输出标记 s i s_{i} si 的上下文向量为:
h i = ∑ j α i j V j h_{i}=\sum_{j} \alpha_{i j} V_{j} hi=j∑αijVj
其中,
h
i
h_{i}
hi 是通过注意力机制加权的价值向量,表示标记
s
i
s_{i}
si 的上下文。这一过程将在多层Transformer中重复,每层将继续基于前一层的输出建模上下文。
(4) 输出层
将所有标记的上下文向量合并为固定维度的广告语义嵌入向量,为后续广告推荐系统提供输入。通常,BERT的输出是每个标记的上下文表示 h i h_{i} hi,我们需要将这些表示聚合为固定维度的向量。最常用的方法是使用BERT中的 [CLS] 标记的输出作为整个序列的表示。
在BERT中,输入序列的开头插入一个特殊的 [CLS] 标记,以表示整个序列的语义。通过池化操作,我们可以提取与 [CLS] 标记对应的向量 h C L S h_{C L S} hCLS 作为广告解决方案集合的整体语义表示:
h C L S = h a d h_{C L S}=h_{a d} hCLS=had
其中,
h
a
d
h_{a d}
had 是整个广告文案的语义嵌入向量。
为了确保输出向量的维度一致性,通常会对嵌入向量进行标准化,例如L2归一化:
h C L S = h a d ∥ h a d ∥ 2 h_{C L S}=\frac{h_{a d}}{\left\|h_{a d}\right\|_{2}} hCLS=∥had∥2had
这样,所获得的嵌入向量长度将为1,便于后续模型的输入。
(5) 分类或推荐任务
一旦获得了广告文案的语义嵌入向量 h a d h_{a d} had,它可以输入到后续的分类或推荐模型中进行个性化广告推送。Haoyang Feng和Yuan Gao [14] 的最新研究表明,将传统的广告优化技术与机器学习相结合可以显著提高在线广告的有效性,支持我们方法的实际应用潜力。假设我们有一个分类任务,目标是预测广告是否会被用户点击。模型可以通过以下公式进行预测:
y ^ = σ ( W ⋅ h a d + b ) ( 10 ) \hat{y}=\sigma\left(W \cdot h_{a d}+b\right)_{(10)} y^=σ(W⋅had+b)(10)
其中, y ^ \hat{y} y^ 是预测标签(例如点击概率),W 是权重矩阵,b 是偏置项, σ \sigma σ 是Sigmoid激活函数,用于输出0到1之间的概率值。
3.3 用户信息权利
在某种程度上,用户的个人信息权利是一种控制其个人信息的方式。衡量APP用户所享有的信息权利是确定APP隐私政策内容是否完整的关键。隐私政策是否规定用户可以随时浏览、复制、删除和修改个人信息,以及是否对用户在操作过程中的权利作出具体规定,都是涉及用户信息权利的重大问题。
在带有隐私插件的广告环境中,当用户浏览或点击广告时,不必担心其个人信息被收集。根据本地模型上传的参数生成相应的用户标签,然后进行过滤和显示。在显示过程中,仅通过本地模型的学习保留本地用户数据,从而降低用户隐私泄露的风险。类似的高风险敏感AI应用已在金融环境中进行了探索。例如,王珠琦、张清河和程卓培[15] 展示了如何使用AI进行实时信用风险检测,展现了AI在管理敏感数据同时保持运营效率的更广泛作用。本文将此过程分为两个阶段,以便详细描述广告展示的过程。第一步是通过用户本地训练生成相应的用户标签,然后基于用户标签进行推荐并向用户展示。
4. 结果与讨论
4.1 实验设置
实验数据来自多个公共广告推荐数据集和模拟数据,主要包括广告点击日志数据、用户行为数据、广告内容数据和用户社交数据。广告点击日志记录用户在广告平台上的点击行为,用户行为数据包括浏览、搜索和购买记录,广告内容数据涉及广告文本、图片和标签,社交数据帮助理解用户之间的潜在联系。此外,为确保实验的全面性,本文还在特定场景中使用数据生成广告推荐数据。所有数据都经过清理和预处理以用于实验训练和评估。数据预处理和类别平衡已被证明对健康预测任务中的机器学习性能有显著影响。例如,钟和王[18] 演示了适当的集成模型和平衡策略可以显著提高甲状腺疾病分类的预测准确性。
基于BERT的大型语言模型(以下简称“BERT”)、协同过滤系统(以下简称“RF”)、基于内容的推荐系统(以下简称“基于内容”)和随机推荐系统(以下简称“RRS”)进行了比较,以验证本文模型的优越性。
4.2 个性化广告推荐性能
从点击率(CTR)和转化率(CR)方面评估个性化广告推荐系统的有效性。
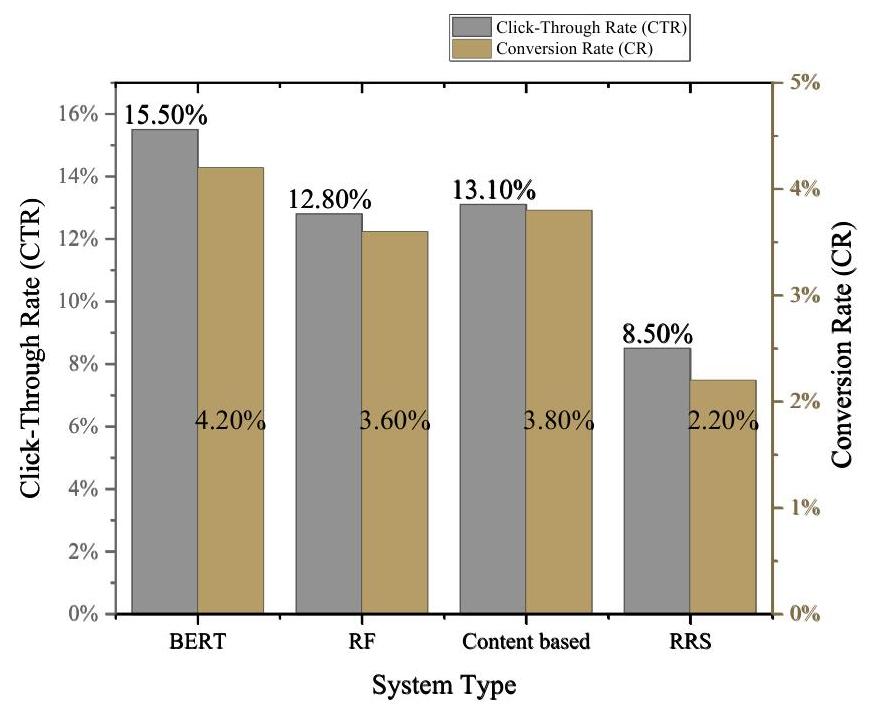
图1. 广告推荐系统性能评估
根据图1中的实验数据,BERT模型在点击率(CTR)和转化率(CR)方面表现优异,明显优于其他推荐系统。具体而言,BERT的点击率为
15.50
%
15.50 \%
15.50%,转化率为
4.20
%
4.20 \%
4.20%,这表明它可以更准确地推荐用户感兴趣的广告,从而增加用户的点击和购买转化。相比之下,协同过滤系统(RF)和基于内容的推荐系统(Content based)分别实现了
12.80
%
12.80 \%
12.80% 和
13.10
%
13.10 \%
13.10% 的点击率,以及
3.60
%
3.60 \%
3.60% 和
3.80
%
3.80 \%
3.80% 的转化率。虽然它们表现良好,但仍低于BERT模型。这表明BERT在个性化推荐和广告推送方面更为高效。随机推荐系统(RRS)表现最差,点击率仅为
8.50
%
8.50 \%
8.50%,转化率为
2.20
%
2.20 \%
2.20%,远低于其他模型,表明其推荐效果不够准确,用户参与度较低。因此,从广告效果的角度来看,BERT不仅在提高点击率和转化率方面具有显著优势,还展示了在个性化广告推荐方面的高潜力。
4.3 隐私保护效果分析
为了评估本地模型训练和传统云模型训练的隐私保护效果,实验可以使用隐私泄露风险指标(如数据泄露概率、隐私泄露事件数量等)来衡量不同模型解决方案的能力。以下是实验数据,显示了这两种模型解决方案的隐私保护效果。
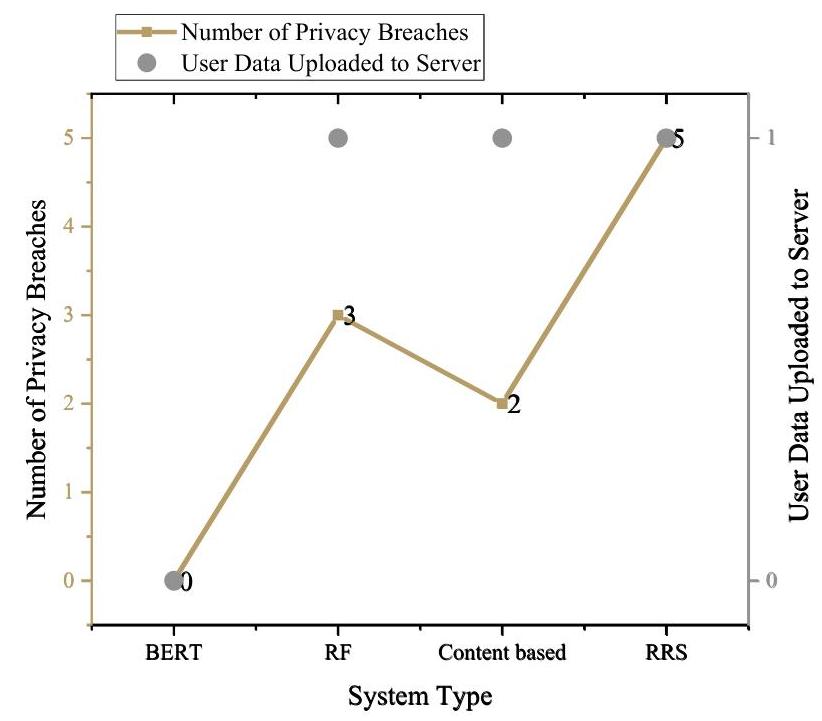
注意:当用户数据上传到服务器时,1表示是,0表示否。
图2. 用户隐私保护效果对比
根据实验数据分析,BERT模型在隐私保护方面表现良好。BERT未发生任何隐私泄露事件(隐私泄露事件数量为0),用户数据完全保留在本地且未上传到服务器(上传到服务器的用户数据数量为0)。这种本地模型训练和数据处理方法有效降低了隐私泄露的风险。相比之下,协同过滤系统(RF)和基于内容的推荐系统(Content based)均发生了隐私泄露事件,其中RF发生了3次隐私泄露事件,Content based发生了2次。这些系统的用户数据已上传到服务器(上传到服务器的用户数据为1),增加了数据泄露的潜在风险。随机推荐系统(RRS)表现最差,发生了5次隐私泄露事件,其用户数据也已上传到服务器,进一步暴露了隐私泄露的风险,如图2所示。
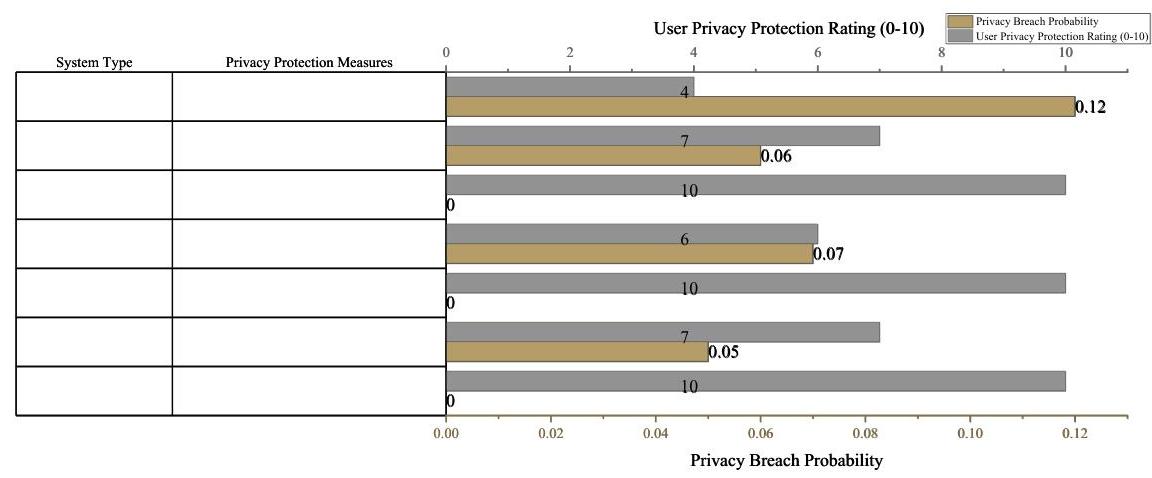
图3. 本地模型训练与云模型训练的隐私保护效果对比
BERT - 本地模型采用数据加密、匿名化和本地存储等隐私保护措施,确保用户数据无需上传到云端,从而完全消除隐私泄露的风险,其隐私泄露概率为
0
%
0 \%
0%。用户隐私保护得分为10分,表现优秀。由于所有数据处理都在本地完成,用户对其隐私保护能力具有极高的信任度。相比之下,尽管BERT - 云模型也采用了数据加密、匿名化和加密传输等技术,但由于数据需要上传到服务器进行处理,其隐私泄露概率为
5
%
5 \%
5%,因此用户隐私保护得分降至7分。这表明,尽管云已经采取了充分的隐私保护措施,用户仍对云数据处理的隐私安全性存在顾虑。对于基于内容的云模型,尽管也使用了加密、匿名化和加密传输技术,但由于数据需要上传到云端,隐私泄露概率为
6
%
6 \%
6%,用户隐私保护得分为7分(如图3所示)。这再次表明,与本地模型相比,云模型在隐私保护方面仍存在较大的信任差距。
4.4 系统的用户满意度及用户点击与转化
为了评估个性化广告推荐系统的用户满意度,可以通过用户调查或实验记录收集数据,了解用户对广告推荐的接受度和满意度以及对隐私保护机制的认可程度。以下是通过调查或实验记录收集的用户满意度数据表。
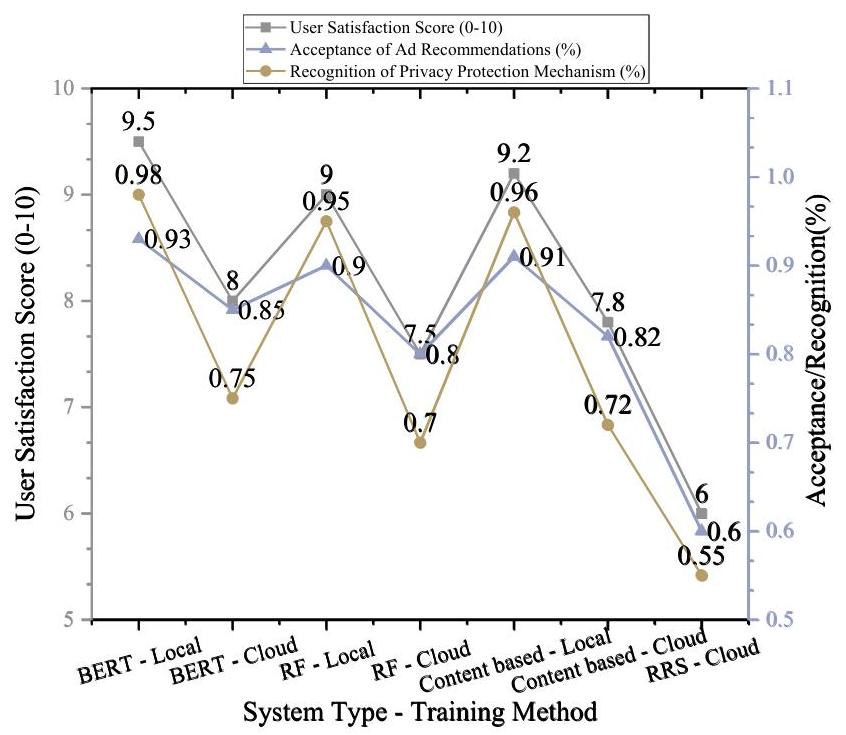
图4. 用户满意度分析 - 个性化广告推荐与隐私保护机制
根据实验数据分析,基于BERT的大型语言模型(BERT)在用户满意度、广告推荐接受度和隐私保护机制认可度方面表现最佳。在本地训练方法下,BERT的用户满意度得分为9.5分,广告推荐接受度达到
93
%
93 \%
93%,隐私保护机制认可度高达
98
%
98 \%
98%。这一结果表明,BERT模型的本地训练方法不仅可以提供高质量的广告推荐,还可以有效提升用户对隐私保护的信任和认可。吴和黄[16] 强调了融合结构化和非结构化健康数据以预测弱势人群心理结果的重要性,这与包容性个性化的目标一致,并进一步启发我们在广告系统设计中考虑以用户为中心的多样性。相比之下,BERT的云训练方法表现相对较差。尽管用户满意度仍然较高(8分),广告推荐接受度降至
85
%
85 \%
85%,隐私保护机制认可度显著下降至
75
%
75 \%
75%,如图4所示。
表1. 用户ID和推荐广告的点击与转化情况
| 用户 ID | 推荐 广告 | 点击 否 | 转化 否 | 广告类别 | 时间段 | 设备 类型 | 用户 兴趣 |
|---|---|---|---|---|---|---|---|
| 100 | 智能手机 | 是 | 是 | 电子产品 | 上午 | 移动设备 | 科技, |
| 1 | 促销 | 小工具 | |||||
| 00 | 健身 | 否 | 否 | 健康 & | 下午 | 台式机 | 健身, |
| 2 | 追踪器广告 | 健身 | 运动 | ||||
| 00 | 度假 | 是 | 否 | 旅游 | 晚上 | 移动设备 | 旅行, |
| 3 | 套餐广告 | 休闲 | |||||
| 00 | 笔记本电脑 | 是 | 是 | 电子产品 | 上午 | 笔记本电脑 | 科技, |
| 4 | 折扣 | 小工具 | |||||
| 00 | 流媒体 | 是 | 是 | 娱乐 | 夜晚 | 移动设备 | 电影, |
| 5 | 服务 | t | 电视 | ||||
| 节目 | |||||||
| 00 | 家居 | 家居 & | 下午 | 台式机 | 家居, | ||
| 6 | 家电 | 否 | 否 | 生活 | 家具 | ||
| 特卖 | |||||||
| 00 | 汽车保险 | 是 | 否 | 金融 | 晚上 | 移动设备 | 金融, |
| 7 | 优惠 | 保险 | |||||
| 00 | 在线 | 是 | 是 | 教育 | 上午 | 台式机 | 教育 |
| 8 | 学习广告 | ,课程 |
根据表1中的用户ID和推荐广告的点击与转化情况,可以看出本文的模型可以根据用户兴趣、时间和设备类型推荐相关广告,并实现高点击率和转化率。例如,U001和U004分别点击并转化了“智能手机促销”和“笔记本折扣”广告,显示了广告推荐的高度相关性和准确性。当广告类别与用户兴趣匹配时,点击率和转化率显著提高。例如,U001(兴趣为“科技,小工具”)点击并转化了“智能手机促销”广告,U005(兴趣为“电影,电视节目”)点击并转化了“流媒体服务”广告。尽管一些用户未点击广告(如U002和U006),模型仍根据用户的兴趣和行为预测并推荐合适的广告,但转化率较低,这可能是由于广告内容、时间段和设备等因素未能完全匹配用户需求的交互效应所致。
5. 结论
本文探讨了使用大型语言模型(LLMs)在数字广告中平衡个性化推荐与隐私保护的问题,特别是通过结合BERT模型进行广告推荐实验,并使用本地训练和加密技术保护用户隐私。实验结果表明,使用本地训练和加密技术可以在不泄露用户敏感数据的情况下提高广告推荐系统的性能,不仅保护了隐私,还有效增强了广告个性化的效果。通过比较现有的广告推荐方法,本研究突显了在隐私保护框架下优化广告推荐的可行性和必要性。尽管现有的广告推荐系统在个性化方面取得了显著进展,但隐私问题一直是技术应用中需要解决的关键挑战。本研究的创新之处在于提出了一种基于加密本地训练的方案,能够在确保隐私的同时实现广告推荐的高效性和准确性。Lu、Wu和Huang[17] 还提出了一种基于群体相对政策优化的个性化干预策略模型,表明通过智能优化可以实现个性化与公平性的平衡,这一概念可以扩展到广告场景中。然而,本研究也存在一定的局限性。由于实验数据的限制,所获得的实验结果主要适用于特定场景,其在其他应用领域的有效性需要进一步验证。未来研究可以进一步扩展数据集,以验证所提方法的广泛适用性。正如Wang、Zhong和Kumar[19] 的工作所强调的那样,针对传染病预测的系统回顾显示,可扩展的机器学习应用既受益于领域特定调整,也受益于更广泛的算法评估原则,这些原则可以扩展到数字广告系统中。
参考文献
[1] Chen H, Chan-Olmsted S, Kim J, et al. 消费者对市场营销传播中人工智能应用的看法[J]. 定性市场研究:国际期刊, 2022, 25(1):
125
−
142
125-142
125−142.
[2] Wach K, Duong C D, Ejdys J, et al. 生成式人工智能的阴暗面:ChatGPT争议和风险的批判性分析[J]. 创业企业与经济评论, 2023, 11(2): 7-30.
[3] Bulchand-Gidumal J, William Secin E, O’Connor P, et al. 人工智能对酒店和旅游营销的影响:探索关键主题和应对挑战[J]. 当代旅游问题, 2024, 27(14): 2345-2362.
[4] Kim W J, Ryoo Y, Lee S Y, et al. 聊天机器人广告的双刃剑:监管重点和隐私担忧的作用[J]. 广告杂志, 2023, 52(4): 504-522.
[5] Kronemann B, Kizgin H, Rana N, et al. 人工智能如何鼓励消费者分享他们的秘密?人格化、个性化和隐私担忧的作用及未来研究途径[J]. 西班牙营销-ESIC期刊, 2023, 27(1): 3-19.
[6] Bhattacharya S, Sharma R P, Gupta A. 电子商务零售商的原产国是否影响消费者隐私、信任和购买意向?[J]. 消费者市场杂志, 2023, 40(2): 248-259.
[7] Raji M A, Olodo H B, Oke T T, et al. 旅游业中的数字营销:美国和非洲实践的综述[J]. 国际应用社会科学研究杂志, 2024, 6(3): 393-408.
[8] Marthews A, Tucker C. 区块链能做什么和不能做什么:在营销和隐私中的应用[J]. 国际营销研究杂志, 2023, 40(1): 49-53.
[9] Ke T T, Sudhir K. 隐私权和数据安全:GDPR和个人数据市场[J]. 管理科学, 2023, 69(8): 4389-4412.
[10] Paul J, Ueno A, Dennis C. ChatGPT与消费者:益处、隐患和未来研究议程[J]. 国际消费者研究杂志, 2023, 47(4): 1213-1225.
[11] Goldberg S G, Johnson G A, Shriver S K. 在线隐私监管:对GDPR的经济评估[J]. 美国经济杂志:经济政策, 2024, 16(1): 325-358.
[12] Lim W M, Gupta S, Aggarwal A, et al. 数字原住民如何看待和反应在线广告?对中小企业的启示[J]. 战略营销杂志, 2024, 32(8): 1071-1105.
[13] Wu, S., Huang, X., & Lu, D. (2025). 心理健康知识增强的基于LLM的社会网络危机干预文本转移识别方法. arXiv. https://arxiv.org/abs/2504.07983
[14] Feng, H., & Gao, Y. (2025). 结合机器学习的互联网电商广告位优化算法. 预印本. https://doi.org/10.20944/preprints202502.2167.v1
[15] Wang, Z., Zhang, Q., & Cheng, Z. (2025). AI在实时信用风险检测中的应用. 预印本. https://doi.org/10.20944/preprints202502.1546.v1
[16] Wu, S., & Huang, X. (2025). 基于EHR中结构化和非结构化数据融合的心理健康预测:低收入人群案例研究. 预印本. https://doi.org/10.20944/preprints202502.2104.v1
[17] Lu, D., Wu, S., & Huang, X. (2025). 基于群体相对政策优化和时间序列数据融合的个性化医疗干预策略生成系统研究. arXiv. https://arxiv.org/abs/2504.18631
[18] Zhong, J., & Wang, Y. (2025). 使用机器学习增强甲状腺疾病预测:集成模型和类别平衡技术的比较研究.
[19] Wang, Y., Zhong, J., & Kumar, R. (2025). 机器学习在传染病预测、诊断和爆发预报中的应用的系统综述. 预印本. https://www.preprints.org/manuscript/2025
参考论文:https://arxiv.org/pdf/2505.04665


















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











