







1.XML基础知识见:http://www.w3school.com.cn/xml/index.asp
2.DTD基础知识见:http://www.w3school.com.cn/dtd/index.asp 和 http://blog.csdn.net/xiazdong/article/details/7270593
3.SAX解析XML文件核心JAVA语句:
SAXParserFactory factory = SAXParserFactory.newInstance();//使用SAXParserFactory创建SAX解析工厂
SAXParser saxParser = factory.newSAXParser();//通过SAX解析工厂得到解析器对象
saxParser.parse( new File(argv[0]), handler);//将解析对象和事件处理器对象关联,关于xml文件的解析过程中的处理全部在Handler里面实现
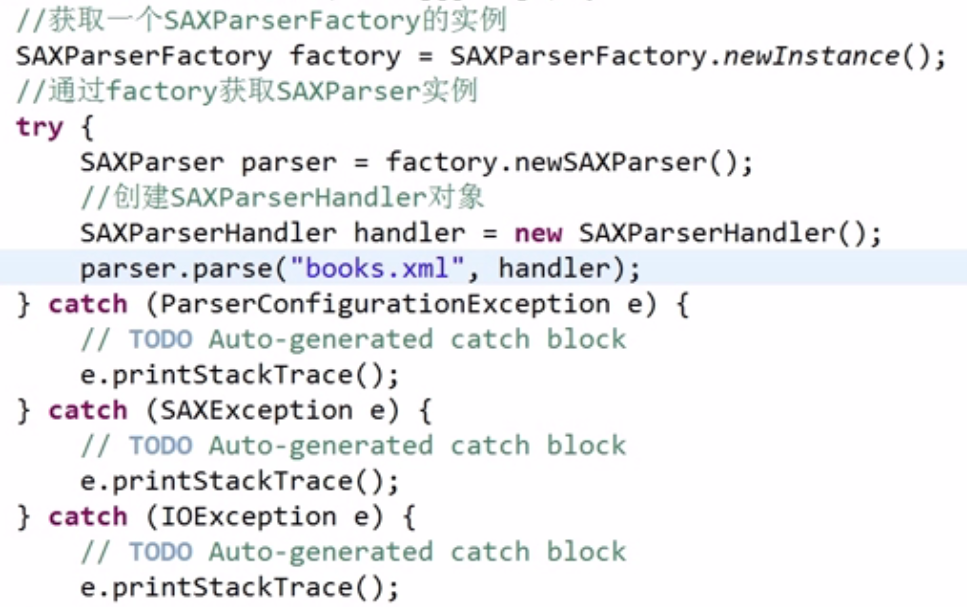
上SAXParserHandler为自定义类,继承了DefaultHandler,并重写其startDocument(),endDocument(),startElement(),character(),endElement() 5个方法。
详细过程见:
http://blog.csdn.net/rainv/article/details/1673022,文档中元素逐个解析时方法回调过程很详细。
http://blog.csdn.net/wssiqi/article/details/8239357 ,XML SAX localName和qName的区别,看了一些程序大都是SAX1。
4. DOM (Document Object Model,与平台和语言无关的方式表示XML文档的官方W3C标准) 解析原理:基于内存,先把XML文件整个文档信息和和构造层次结构(树型)加载到内存中,在逐个解析。DOM可以读取XML也可以向XML文件中插入数据,可以指定要访问的元素进行随机访问。但是DOM方式读取大文件时消耗很大的内存空间。
SAX (Simple API for XML) 解析原理:基于事件,通过自己创建的Handler类,去逐个分析遇到的每一个节点(节点分析是从最外层向里层逐个开始),这种串行化的模型不允许对XML文档进行随机读取,也就是说只能获得XML文件正在解析的信息。这种层次型和串行的访问方式也使得SAX模型在元素之间的横向移动非常困难。但是SAX方式适于解析较大的复杂的XML文件。















 1793
1793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









