







在本地搭建好Spark 1.6.0后,除了使用官方文档中的sbt命令打包,spark-submit提交程序外,我们可以使用IntelliJ IDEA这个IDE在本地进行开发调试,之后再将作业提交到集群生产环境中运行,使用IDE可以提升我们的开发效率。转载请注明博客原文地址:http://blog.tomgou.xyz/shi-yong-intellij-ideapei-zhi-sparkying-yong-kai-fa-huan-jing-ji-yuan-ma-yue-du-huan-jing.html
1. 安装IntelliJ IDEA
我的系统环境(Ubuntu 14.04.4 LTS),其他配置见:Spark 1.6.2 单机版安装配置。下载最新版本的IntelliJ IDEA,官网地址:https://www.jetbrains.com/idea/download/ 。 最新版本的IntelliJ IDEA支持新建SBT工程,安装scala插件。
安装步骤:
解压 idea-15.0.4.tar.gz
tar xfz idea-15.0.4.tar.gz在bin目录下运行 idea.sh文件
记得最初配置时安装插件,在IntelliJ IDEA的“Configure”菜单中,选择“Plugins”,安装“Scala”插件。
补充:
(1).出现下面类错误:
ERROR: cannot start IntelliJ IDEA. No JDK found to run IDEA.。。。
解决:
若确定你的系统已经安装了JAVA 并设置好了环境变量,那么在/etc/profile文件最后加一行
export IDEA_JDK= 此处为你的系统中$JAVA_HOME的值。(2)最新版的IntelliJ IDEA2016只支持jdk8及以上,否则报错。
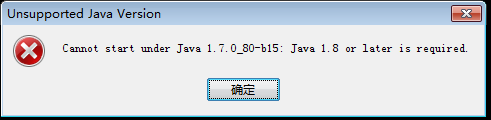
解决:换成jdk1.8即可。
2. 以本地local模式运行Spark程序
1)创建“New Project”,选择“Scala”。“Project SDK”选择JDK目录,“Scala SDK”选择Scala目录。

2)选择菜单中的“File” ->“Project Structure” ->“libraries” ->+“java”,导入Spark安装目录/home/tom/spark-1.6.0/lib下的“spark-assembly-1.6.0-hadoop2.6.0.jar”。
3)运行Scala示例程序SparkPi: Spark安装目录的examples目录下,可以找到Scala编写的示例程序SparkPi.scala,该程序计算Pi值并输出。 在Project的main目录下新建SparkPitest.scala,复制Spark示例程序代码。

选择菜单中的“Run” ->“Edit Configurations”,修改“Main class”和“VM options”。

运行结果:

注意: 在我最初运行Spark的测试程序SparkPi时,点击运行,出现了如下错误: Exception in thread “main” org.apache.spark.SparkException: A master URL must be set in your configuration 从提示中可以看出找不到程序运行的master,此时需要配置环境变量。 搜索引擎查询错误后,了解到传递给spark的master url可以有如下几种,具体可以查看Spark官方文档:
local 本地单线程
local[*] 本地多线程(指定所有可用内核)
spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。
mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。
yarn-client客户端模式 连接到 YARN集群。需要配置 HADOOP_CONF_DIR。
yarn-cluster集群模式 连接到 YARN 集群。需要配置HADOOP_CONF_DIR。
在VM options中输入“-Dspark.master=local”,指示本程序本地单线程运行。
补充:
若出现此类错误:java.lang.IllegalArgumentException: System memory 259522560 must be at least 4.718592E8. Please use a larger heap size.
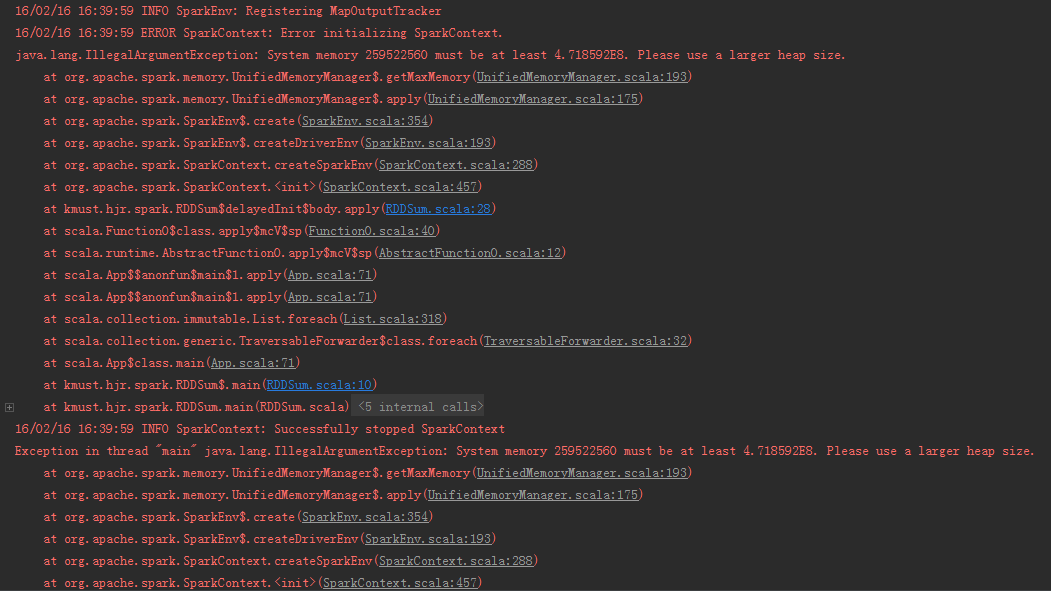
解决:
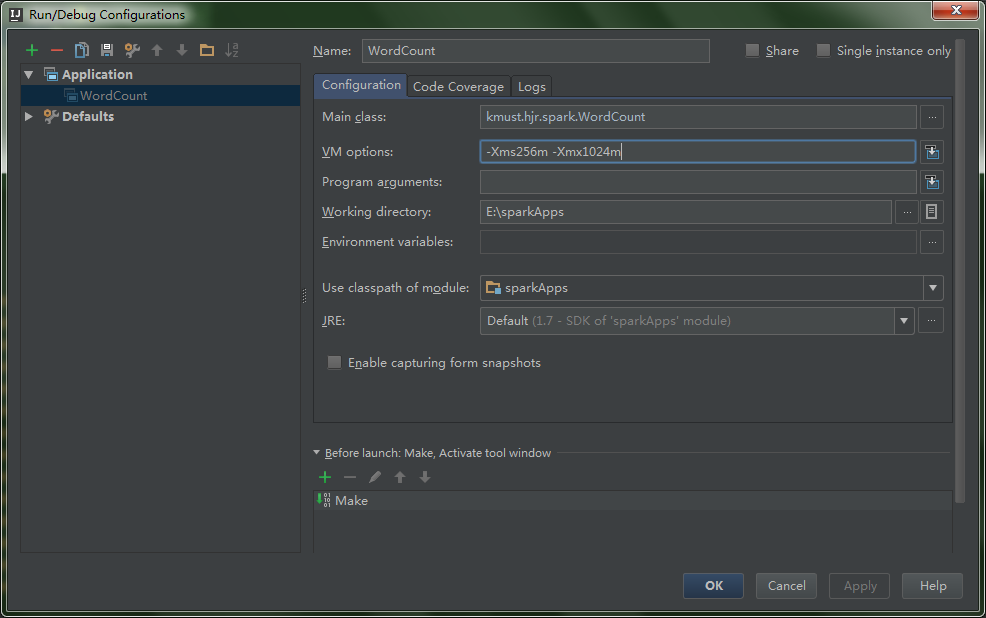
idea的设置路径在:Run -Edit Configurations-Application选择对应的程序,设置VM options,如下:
-Xms256m-Xmx1024m此处截图为网上的,就这么个意思
3. 生成jar包提交到集群
1)和本地local模式运行Spark相同,我们建立起project。
2)选择菜单中的“File” ->“Project Structure” ->“Artifact” ->“jar” ->“From Modules with dependencies”,之后选择Main Class和输出jar的Directory。


3)在主菜单选择“Build” ->“Build Artifact”,编译生成jar包。 4)将jar包使用spark-submit提交:
$SPARK_HOME/bin/spark-submit --class "SimpleApp" --master local[4] simple.jar 4. 配置Spark源码阅读环境
克隆Spark源码:
$ git clone https://github.com/apache/spark然后在IntelliJ IDEA中即可通过“Import Project”,选择sbt项目,选择“Use auto-import”,即可生成IntelliJ项目文件。
















 5470
5470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









