






简介
中国大数据技术大会,Big Data Technology Conference(BDTC),前身是“Hadoop中国云计算会议”,从2008年始创,连续成功举办了十年,作为国内最具影响力、规模最大的大数据领域技术盛会,有来自学术界、工业界的大咖们,包括:中国科学院院士徐宗本,中科院多名所长,国外知名大学教授Michael Franklin、Jian Pei等,百度、腾讯、阿里、滴滴等知名企业的架构师共近百位技术专家将为现场数千名的大数据行业精英、技术专家及意见领袖带来多场技术演讲,分享最新技术与实践的洞察与经验,探寻大数据发展的未来。
本次会议共分为全体大会、大数据分析与生态系统论坛、金融大数据论坛、大数据云服务论坛、知识图谱论坛、大数据安全与政策法规论坛、交通与旅游大数据论坛、金融级分布式架构专场、TOP10大数据应用最佳时间案例、机器学习与神都学习论坛、数据库论坛、推荐系统论坛、区块链论坛、精准医疗大数据论坛和工业与制造业大数据论坛。
重要会议内容
学术界的各位老师们主要研究解决大数据在各个领域的具体问题的科研方法,更加注重理论,工业界的老师们主要介绍大数据在本行业的落地方式,产生的社会价值,更注重实践。
《模型驱动的深度学习》
徐宗本 ——中国科学院院士,数学家、信号与信息处理专家、西安交通大学教授
徐老师是搞数学出身,对大数据技术应用的难点、痛点的剖析可谓“庖丁解牛”。目前深度学习已经被广泛应用,但也面临许多苦难,如:网络拓扑的设计缺少理论基础,学习过程不可解释、结果不可预测,而这些困难引发的根本原因在于:
分析基础被破坏,比如:有偏的样本采集破坏iid特性使统计学基础动摇;
计算模式受拷问,比如:异构环境下的多粒度分布并行计算;
处理算法不可用;
真伪判断缺标准
这四大困难要解决,根本上我们要结合数据流、非易失数据、分布式、多线程这四个环境去解决七个“巨人“问题,包括:
Basic Statistics
Generalized N-body Problem
Graph-theoretical computations
Linearalgebraic computations
Optimization
Integration
Alignment problem
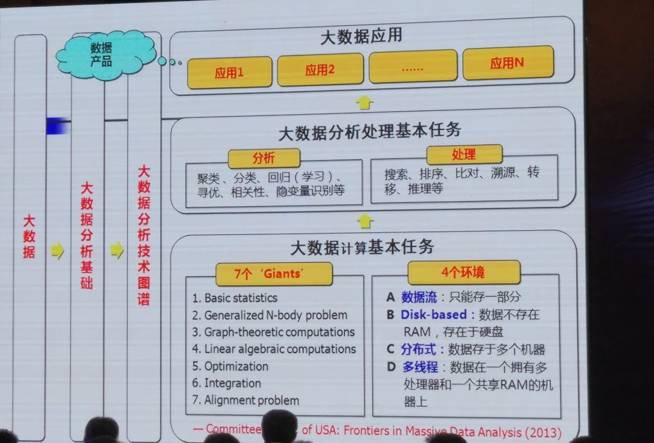
以分布式学习中算法训练的过程来说明基础计算能力中的一大问题。在大数据前提下,一台机器的内存已经远远不够存储训练数据,它们往往分散在集群的各台机器上,大多数算法的优化方法建立在获得全局数据上,将其修改为分布式算法的时候,就需要机器之间做大量的网络传输,然而这样的传输是十分耗时的,导致优化算法的失效。这个问题可以被抽象成一个数学问题:解一个非良定线性方程组。

徐老师提出了一种算法解决上述问题,其核心思想是:提供一个min-max统计最优性,允许少量通讯,保证分布式学习能达到集中学习的统计最优性。
再以解决深入学习不可解释性为例。深度学习基于数据,通用性强,但是网络如何构造(遵循什么理论)、预测结果如何解释非常困难,而传统基于统计模型的方法有较完善的基础理论,但是涉及的参数多,事前确定较困难,且模型的适应度较差,徐老师提出了一种融合统计模型和深度学习的框架,先通过先验知识建模,获得数学理论支撑,提供深度学习的数据结构与拓扑结果,再通过数据来获得自动的参数调节,通过结合解决上述问题。
《Fuel the AI Rochet:Technical andBusiness Challenges》Jian Pei——ACMFellow Simon Fraser University, Canada, ACM KDD Chair, ACM Fellow
Pei教授的主题是关于深度学习的数据量问题的。过去业界人们常说,我使用深度学习的技术,只要能收集大量的数据,那么就可以发挥神奇的作用,然而这样的说法并不能令人满意,比如简单的反问:“那需要多少数据就足够了呢?“往往就得不到正面回答,而Pei教授就深度学习的scalability进行了研究并且得出了有意思的结论:当数据量很大的时候,深度网络可以被拆分为许多线性模型的组合,当数据量逐步增大的时候,深度网络学习到的线性模型组合就越来越复杂,初始状态(数据量很小)时,深度网络可以由一个简单的逻辑回归表达。如下右图,每一线性模型是一个小的多边形,整个图片是一个深度网络。

《Panel:大数据是否还是人工智能的基础?》—— 章文嵩,滴滴出行高级副总裁
Panel有4个老师参加,这里重点介绍一下章老师的观点,他认为“数据+模型=人工智能“,大数据仍然在很长一段时间是人工智能的基础,同时他还认为正确的规则也是数据,比如AlphaZero能发挥巨大的作用,跟围棋规则能提供大量的数据有关,即”规则也是数据“,同样之前很出名的GANs也有异曲同工之妙。

《美团点评数据库智能运维探索与实践》赵应钢——高级技术专家
赵老师和数据库打了10多年的交道了,一直在自动化运维开发、数据库性能优化、大规模数据库集群技术保障方面不断探索,他把运维的历史分为5个阶段:脚本化、工具化、产品化、自助化、自动化,在智能运维这个方面,业界一般的做法是把这个问题建模成各种异常检测的问题(感兴趣的同学还可以参考一些清华裴丹教授最近写的智能运维落地技术路线图),而他们也不例外,从数据库预警、主从延迟预警、容量预警、磁盘空间预警、慢查询预警来入手,搭建了一套规则引擎,做根因定位,并且提供了较为便捷的一键回滚页面,方便应急同学做快速处理。
个人感受
深度学习依旧热门,但也面临问题
深度学习依旧是热门,随着工业界、学术界对其研究和使用也更加深入和频繁,学者们发掘出了更多问题、也提出了部分解决方案,但是深度学习仍然有很多使用的限制条件,而解决这些需要学术界、工业界不断的探索。
AI已经深入各行各业,应该可以比前两次浪潮持续时间更长
前两次AI浪潮的持续时间基本在10年左右,由于数据、算力的影响,最终落幕,随着数据、算法、模型并驾齐驱的发展,目前仍然处于上升期,后续应该还会不断有企业投入,学习AI技术仍然是值得的。

数据融合将会成为下一个AI的重点
本次大会可以看到,AI已经在各行各业落地,那么随着未来物联网的普及,对“人”的刻画将更加全面,医疗、社交、支付、消费等行为通过以往单一的维度将遇到天花板,通过各维度数据的融合,可以获得以往无法突破的价值,未来是流量入口更加是数据入口,成为各大公司的必争之地。
资料
大会主页:http://bdtc2017.bigdataforum.org.cn/m/zone/bdtc2017/index
部分PPT资料下载:http://download.csdn.net/meeting/meeting_detail/37
















 3149
3149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









