






一、数据预处理
1. 探索性数据分析
- 丢掉数据缺失高于30%的列
- 检查数据类型
- 类型转换,字符串转成浮点数
- eg:货币、面积
- 检查数字列的最大最小值是否合理
- 过滤掉不正常值的列
可视化方法
- displot
- subplots/ heaetmap
- boxplot
2. 数据清洗
流程图
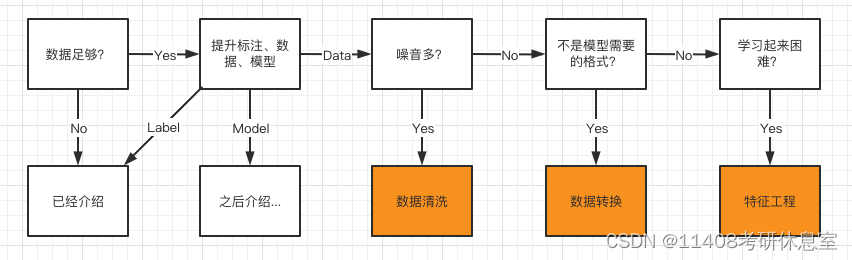
2.1 数据错误
- 缺值、错误、极端值
- 好的ML模型对错误容忍度很高,但是会影响精度
- 把错误的模型部署在线上会影响新收集到的数据质量,模型慢慢变差
2.1.1 数据错误类型
-
Outliers:数据的值不再正常分布区间内
- 类别:可能单词间有空格。手动fix归类或者直接丢掉

- 实数:boxplot中,以25%和75%分界线上下1.5倍的box height

-
Rule violations:规则冲突,一般来说是数据库的完整性约束要求。eg:Not Null/Unique
- 函数依赖:x->y x确定了唯一的y
- 拒绝约束:指定一些规则(一阶逻辑表达式)
-
Pattern violations:语法/语义规则冲突。eg:拼写错误
- 语法模式
- eg:eng->English
- 语义模式: 通过知识图
- eg:Country列需要有国家,所以’四川‘这个值是错误的
- 语法模式
3. 数据变换
流程图

3.1 Tabular实数列的转换(标准化Normalization)
3.1.1. Min-Max Normalization:线性映射到一个[a,b]区间内
3.1.2. Z-Score Normalization:标准正态分布
3.1.3. 10的n次方缩放:把Xi缩放到[-1,1]之间
3.1.4. Log缩放: Xi取Log
四种标准化公式

3.2 图片转换
3.2.1. 图片进行缩小和下采样
- jpeg格式的中等质量图片(80%-90%)以下进行下采样会导致精度降低1%
3.2.2. 图片白化
- 对图片降维
3.3 视频转换
3.3.1. 通常使用短视频片段,每段包含一个单独的事件(<10s)
3.3.2. 对视频的帧进行采样
3.3.3. 权衡存储成本、视频质量
3.4 文本转换
- 语法和词根化:单词转换成一个通用的形式
- eg: 语法化am,are,is -> be car, 词根化cars,car’s ->car
- 词元化tokenization: 单词转换成一系列的词元
- 根据单词划分
- 根据字符划分
- 根据子词划分
4. 特征工程
- 在深度学习之前,特征工程是关键任务
- 深度学习就是用神经网络替换掉手动的特征工程进行自动抽取特征,但是更耗费计算资源‘
4.1. 表数据特征
- Int/float:直接用,或者分散到n个桶里面变成int
- Categorical类别数据:独热编码,向量只有某一列是1其他全是0
- 时间
- eg: [year,month,day,day_of_year,week_of_year,day_of_week]
- 特征组合:多个特征的笛卡尔积
4.2. 文本数据特征
把文本表示成词元的特征
- Bag of Words模型(BoW):每个词的独热编码表示出来,做向量加法
- 词嵌入word embeddings(Word2vec):把词表示成有语义信息的向量,通过预测目标词的上下文词来训练
- 预训练好的模型(BERT,GPT-3)
- 大的transformer模型
- 在一个很大的无标注的数据上进行自训练
- 可以做fine-tuning
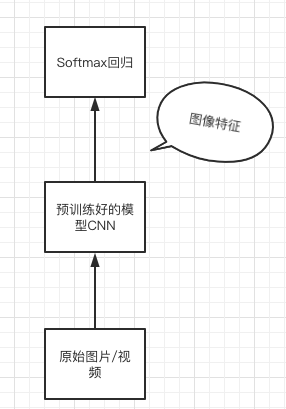
4.3. 图像/视频数据特征
- 深度学习之前用手工特征抽取如SIFT
- 现在的深度学习用ResNet(用ImageNet的图像分类器)/I3D(用Kinetics训练的动作分类器)
5. 总结
本章节流程图

面临的挑战
- 质量于数量的平衡
- 产品质量角度:数据多样性、数据不偏向、公平性(对人)
- 大规模数据的管理问题:存储、处理、版本控制、安全















 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









