







先看看InputFormat接口和
public interface InputFormat<K, V> {
InputSplit[] getSplits(JobConf var1, int var2) throws IOException;
RecordReader<K, V> getRecordReader(InputSplit var1, JobConf var2, Reporter var3)
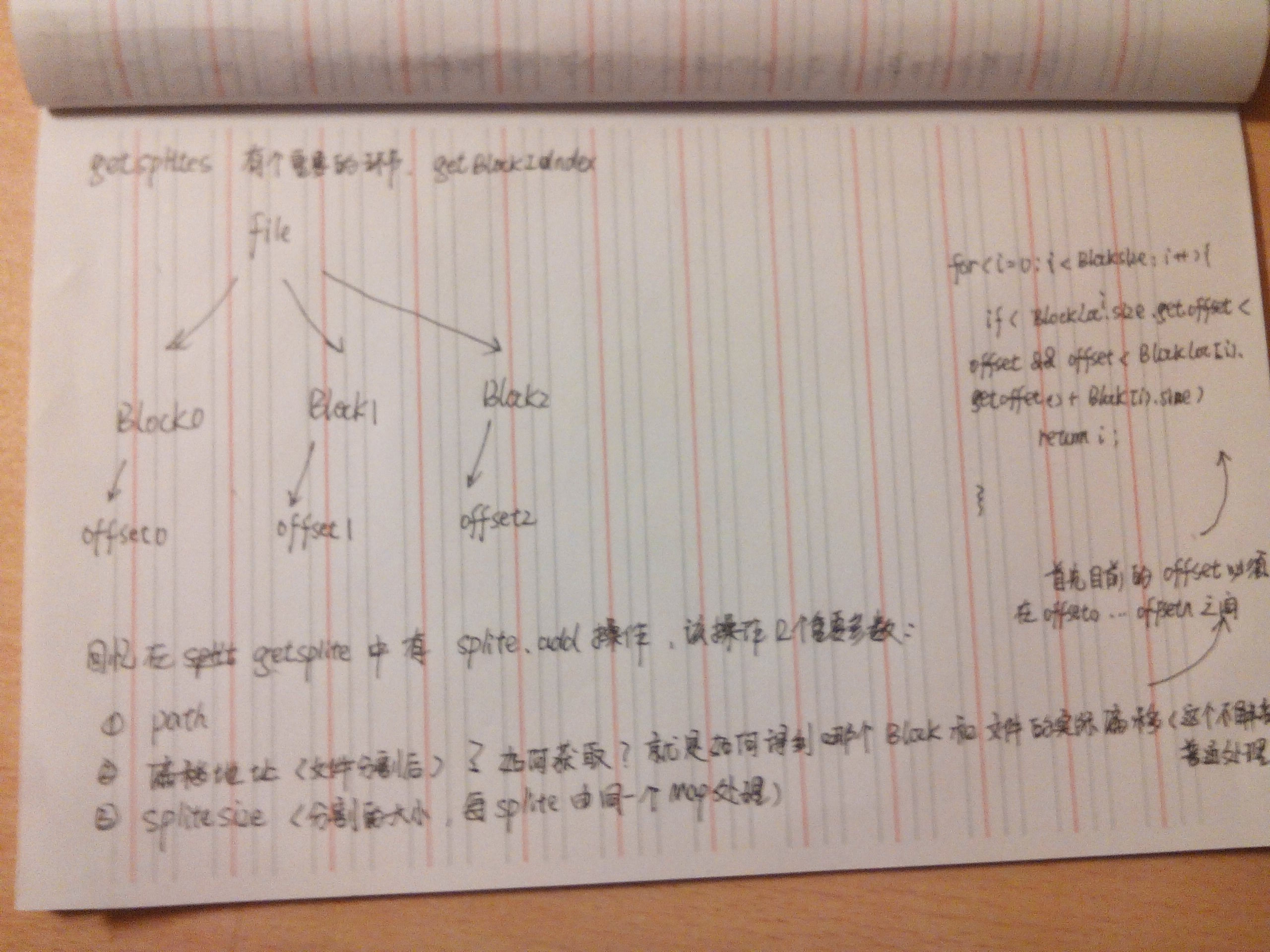
throws IOException;}public interface RecordReader<K, V> { boolean next(K var1, V var2) throws IOException; K createKey(); V createValue(); long getPos() throws IOException; void close() throws IOException; float getProgress() throws IOException; }其中Input定义了如何分割数据,recordread定义了如何给mapper提供k,v我们如何实现定制呢?Inputformat有个实现版本,FileInputFormat,里面的代码很值得去查看<span style="font-size:18px;">// // Source code recreated from a .class file by IntelliJ IDEA // (powered by Fernflower decompiler) // package org.apache.hadoop.mapred; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.HashSet; import java.util.IdentityHashMap; import java.util.Iterator; import java.util.LinkedList; import java.util.List; import java.util.Map; import java.util.Set; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.fs.BlockLocation; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.PathFilter; import org.apache.hadoop.mapred.FileSplit; import org.apache.hadoop.mapred.InputFormat; import org.apache.hadoop.mapred.InputSplit; import org.apache.hadoop.mapred.InvalidInputException; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.RecordReader; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapreduce.security.TokenCache; import org.apache.hadoop.net.NetworkTopology; import org.apache.hadoop.net.Node; import org.apache.hadoop.net.NodeBase; import org.apache.hadoop.util.ReflectionUtils; import org.apache.hadoop.util.StringUtils; public abstract class FileInputFormat<K, V> implements InputFormat<K, V> { public static final Log LOG = LogFactory.getLog(FileInputFormat.class); private static final double SPLIT_SLOP = 1.1D; private long minSplitSize = 1L; private static final PathFilter hiddenFileFilter = new PathFilter() { public boolean accept(Path p) { String name = p.getName(); return !name.startsWith("_") && !name.startsWith("."); } }; static final String NUM_INPUT_FILES = "mapreduce.input.num.files"; public FileInputFormat() { } protected void setMinSplitSize(long minSplitSize) { this.minSplitSize = minSplitSize; } protected boolean isSplitable(FileSystem fs, Path filename) { return true; } public abstract RecordReader<K, V> getRecordReader(InputSplit var1, JobConf var2, Reporter var3) throws IOException; public static void setInputPathFilter(JobConf conf, Class<? extends PathFilter> filter) { conf.setClass("mapred.input.pathFilter.class", filter, PathFilter.class); } public static PathFilter getInputPathFilter(JobConf conf) { Class filterClass = conf.getClass("mapred.input.pathFilter.class", (Class)null, PathFilter.class); return filterClass != null?(PathFilter)ReflectionUtils.newInstance(filterClass, conf):null; } protected FileStatus[] listStatus(JobConf job) throws IOException { Path[] dirs = getInputPaths(job); if(dirs.length == 0) { throw new IOException("No input paths specified in job"); } else { TokenCache.obtainTokensForNamenodes(job.getCredentials(), dirs, job); ArrayList result = new ArrayList(); ArrayList errors = new ArrayList(); ArrayList filters = new ArrayList(); filters.add(hiddenFileFilter); PathFilter jobFilter = getInputPathFilter(job); if(jobFilter != null) { filters.add(jobFilter); } FileInputFormat.MultiPathFilter inputFilter = new FileInputFormat.MultiPathFilter(filters); Path[] arr$ = dirs; int len$ = dirs.length; for(int i$ = 0; i$ < len$; ++i$) { Path p = arr$[i$]; FileSystem fs = p.getFileSystem(job); FileStatus[] matches = fs.globStatus(p, inputFilter); if(matches == null) { errors.add(new IOException("Input path does not exist: " + p)); } else if(matches.length == 0) { errors.add(new IOException("Input Pattern " + p + " matches 0 files")); } else { FileStatus[] arr$1 = matches; int len$1 = matches.length; for(int i$1 = 0; i$1 < len$1; ++i$1) { FileStatus globStat = arr$1[i$1]; if(globStat.isDir()) { FileStatus[] arr$2 = fs.listStatus(globStat.getPath(), inputFilter); int len$2 = arr$2.length; for(int i$2 = 0; i$2 < len$2; ++i$2) { FileStatus stat = arr$2[i$2]; result.add(stat); } } else { result.add(globStat); } } } } if(!errors.isEmpty()) { throw new InvalidInputException(errors); } else { LOG.info("Total input paths to process : " + result.size()); return (FileStatus[])result.toArray(new FileStatus[result.size()]); } } } public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException { FileStatus[] files = this.listStatus(job); job.setLong("mapreduce.input.num.files", (long)files.length); long totalSize = 0L; FileStatus[] goalSize = files; int len$ = files.length; for(int minSize = 0; minSize < len$; ++minSize) { FileStatus file = goalSize[minSize]; if(file.isDir()) { throw new IOException("Not a file: " + file.getPath()); } totalSize += file.getLen(); } long var29 = totalSize / (long)(numSplits == 0?1:numSplits); long var30 = Math.max(job.getLong("mapred.min.split.size", 1L), this.minSplitSize); ArrayList splits = new ArrayList(numSplits); NetworkTopology clusterMap = new NetworkTopology(); FileStatus[] arr$ = files; int len$1 = files.length; for(int i$ = 0; i$ < len$1; ++i$) { FileStatus file1 = arr$[i$]; Path path = file1.getPath(); FileSystem fs = path.getFileSystem(job); long length = file1.getLen(); BlockLocation[] blkLocations = fs.getFileBlockLocations(file1, 0L, length); if(length != 0L && this.isSplitable(fs, path)) { long var28 = file1.getBlockSize(); long splitSize = this.computeSplitSize(var29, var30, var28); long bytesRemaining; for(bytesRemaining = length; (double)bytesRemaining / (double)splitSize > 1.1D; bytesRemaining -= splitSize) { String[] splitHosts1 = this.getSplitHosts(blkLocations, length - bytesRemaining, splitSize, clusterMap); splits.add(new FileSplit(path, length - bytesRemaining, splitSize, splitHosts1)); } if(bytesRemaining != 0L) { splits.add(new FileSplit(path, length - bytesRemaining, bytesRemaining, blkLocations[blkLocations.length - 1].getHosts())); } } else if(length != 0L) { String[] splitHosts = this.getSplitHosts(blkLocations, 0L, length, clusterMap); splits.add(new FileSplit(path, 0L, length, splitHosts)); } else { splits.add(new FileSplit(path, 0L, length, new String[0])); } } LOG.debug("Total # of splits: " + splits.size()); return (InputSplit[])splits.toArray(new FileSplit[splits.size()]); } protected long computeSplitSize(long goalSize, long minSize, long blockSize) { return Math.max(minSize, Math.min(goalSize, blockSize)); } protected int getBlockIndex(BlockLocation[] blkLocations, long offset) { for(int last = 0; last < blkLocations.length; ++last) { if(blkLocations[last].getOffset() <= offset && offset < blkLocations[last].getOffset() + blkLocations[last].getLength()) { return last; } } BlockLocation var7 = blkLocations[blkLocations.length - 1]; long fileLength = var7.getOffset() + var7.getLength() - 1L; throw new IllegalArgumentException("Offset " + offset + " is outside of file (0.." + fileLength + ")"); } public static void setInputPaths(JobConf conf, String commaSeparatedPaths) { setInputPaths(conf, (Path[])StringUtils.stringToPath(getPathStrings(commaSeparatedPaths))); } public static void addInputPaths(JobConf conf, String commaSeparatedPaths) { String[] arr$ = getPathStrings(commaSeparatedPaths); int len$ = arr$.length; for(int i$ = 0; i$ < len$; ++i$) { String str = arr$[i$]; addInputPath(conf, new Path(str)); } } public static void setInputPaths(JobConf conf, Path... inputPaths) { Path path = new Path(conf.getWorkingDirectory(), inputPaths[0]); StringBuffer str = new StringBuffer(StringUtils.escapeString(path.toString())); for(int i = 1; i < inputPaths.length; ++i) { str.append(","); path = new Path(conf.getWorkingDirectory(), inputPaths[i]); str.append(StringUtils.escapeString(path.toString())); } conf.set("mapred.input.dir", str.toString()); } public static void addInputPath(JobConf conf, Path path) { path = new Path(conf.getWorkingDirectory(), path); String dirStr = StringUtils.escapeString(path.toString()); String dirs = conf.get("mapred.input.dir"); conf.set("mapred.input.dir", dirs == null?dirStr:dirs + "," + dirStr); } private static String[] getPathStrings(String commaSeparatedPaths) { int length = commaSeparatedPaths.length(); int curlyOpen = 0; int pathStart = 0; boolean globPattern = false; ArrayList pathStrings = new ArrayList(); for(int i = 0; i < length; ++i) { char ch = commaSeparatedPaths.charAt(i); switch(ch) { case ',': if(!globPattern) { pathStrings.add(commaSeparatedPaths.substring(pathStart, i)); pathStart = i + 1; } break; case '{': ++curlyOpen; if(!globPattern) { globPattern = true; } break; case '}': --curlyOpen; if(curlyOpen == 0 && globPattern) { globPattern = false; } } } pathStrings.add(commaSeparatedPaths.substring(pathStart, length)); return (String[])pathStrings.toArray(new String[0]); } public static Path[] getInputPaths(JobConf conf) { String dirs = conf.get("mapred.input.dir", ""); String[] list = StringUtils.split(dirs); Path[] result = new Path[list.length]; for(int i = 0; i < list.length; ++i) { result[i] = new Path(StringUtils.unEscapeString(list[i])); } return result; } private void sortInDescendingOrder(List<FileInputFormat.NodeInfo> mylist) { Collections.sort(mylist, new Comparator() { public int compare(FileInputFormat.NodeInfo obj1, FileInputFormat.NodeInfo obj2) { return obj1 != null && obj2 != null?(obj1.getValue() == obj2.getValue()?0:(obj1.getValue() < obj2.getValue()?1:-1)):-1; } }); } protected String[] getSplitHosts(BlockLocation[] blkLocations, long offset, long splitSize, NetworkTopology clusterMap) throws IOException { int startIndex = this.getBlockIndex(blkLocations, offset); long bytesInThisBlock = blkLocations[startIndex].getOffset() + blkLocations[startIndex].getLength() - offset; if(bytesInThisBlock >= splitSize) { return blkLocations[startIndex].getHosts(); } else { long bytesInFirstBlock = bytesInThisBlock; int index = startIndex + 1; for(splitSize -= bytesInThisBlock; splitSize > 0L; splitSize -= bytesInThisBlock) { bytesInThisBlock = Math.min(splitSize, blkLocations[index++].getLength()); } long bytesInLastBlock = bytesInThisBlock; int endIndex = index - 1; IdentityHashMap hostsMap = new IdentityHashMap(); IdentityHashMap racksMap = new IdentityHashMap(); String[] allTopos = new String[0]; for(index = startIndex; index <= endIndex; ++index) { if(index == startIndex) { bytesInThisBlock = bytesInFirstBlock; } else if(index == endIndex) { bytesInThisBlock = bytesInLastBlock; } else { bytesInThisBlock = blkLocations[index].getLength(); } allTopos = blkLocations[index].getTopologyPaths(); if(allTopos.length == 0) { allTopos = this.fakeRacks(blkLocations, index); } String[] arr$ = allTopos; int len$ = allTopos.length; for(int i$ = 0; i$ < len$; ++i$) { String topo = arr$[i$]; Object node = clusterMap.getNode(topo); if(node == null) { node = new NodeBase(topo); clusterMap.add((Node)node); } FileInputFormat.NodeInfo nodeInfo = (FileInputFormat.NodeInfo)hostsMap.get(node); Node parentNode; FileInputFormat.NodeInfo parentNodeInfo; if(nodeInfo == null) { nodeInfo = new FileInputFormat.NodeInfo((Node)node); hostsMap.put(node, nodeInfo); parentNode = ((Node)node).getParent(); parentNodeInfo = (FileInputFormat.NodeInfo)racksMap.get(parentNode); if(parentNodeInfo == null) { parentNodeInfo = new FileInputFormat.NodeInfo(parentNode); racksMap.put(parentNode, parentNodeInfo); } parentNodeInfo.addLeaf(nodeInfo); } else { nodeInfo = (FileInputFormat.NodeInfo)hostsMap.get(node); parentNode = ((Node)node).getParent(); parentNodeInfo = (FileInputFormat.NodeInfo)racksMap.get(parentNode); } nodeInfo.addValue(index, bytesInThisBlock); parentNodeInfo.addValue(index, bytesInThisBlock); } } return this.identifyHosts(allTopos.length, racksMap); } } private String[] identifyHosts(int replicationFactor, Map<Node, FileInputFormat.NodeInfo> racksMap) { String[] retVal = new String[replicationFactor]; LinkedList rackList = new LinkedList(); rackList.addAll(racksMap.values()); this.sortInDescendingOrder(rackList); boolean done = false; int index = 0; Iterator i$ = rackList.iterator(); while(i$.hasNext()) { FileInputFormat.NodeInfo ni = (FileInputFormat.NodeInfo)i$.next(); Set hostSet = ni.getLeaves(); LinkedList hostList = new LinkedList(); hostList.addAll(hostSet); this.sortInDescendingOrder(hostList); Iterator i$1 = hostList.iterator(); while(i$1.hasNext()) { FileInputFormat.NodeInfo host = (FileInputFormat.NodeInfo)i$1.next(); retVal[index++] = host.node.getName().split(":")[0]; if(index == replicationFactor) { done = true; break; } } if(done) { break; } } return retVal; } private String[] fakeRacks(BlockLocation[] blkLocations, int index) throws IOException { String[] allHosts = blkLocations[index].getHosts(); String[] allTopos = new String[allHosts.length]; for(int i = 0; i < allHosts.length; ++i) { allTopos[i] = "/default-rack/" + allHosts[i]; } return allTopos; } private static class NodeInfo { final Node node; final Set<Integer> blockIds; final Set<FileInputFormat.NodeInfo> leaves; private long value; NodeInfo(Node node) { this.node = node; this.blockIds = new HashSet(); this.leaves = new HashSet(); } long getValue() { return this.value; } void addValue(int blockIndex, long value) { if(this.blockIds.add(Integer.valueOf(blockIndex))) { this.value += value; } } Set<FileInputFormat.NodeInfo> getLeaves() { return this.leaves; } void addLeaf(FileInputFormat.NodeInfo nodeInfo) { this.leaves.add(nodeInfo); } } private static class MultiPathFilter implements PathFilter { private List<PathFilter> filters; public MultiPathFilter(List<PathFilter> filters) { this.filters = filters; } public boolean accept(Path path) { Iterator i$ = this.filters.iterator(); PathFilter filter; do { if(!i$.hasNext()) { return true; } filter = (PathFilter)i$.next(); } while(filter.accept(path)); return false; } } public static enum Counter { BYTES_READ; private Counter() { } } } </span>比如我们需要定制每个spit的大小,我们且看FileinputFormat是如何定义分割大小的protected long computeSplitSize(long goalSize, long minSize, long blockSize) { return Math.max(minSize, Math.min(goalSize, blockSize)); }其实split的大小可以超过block的(这样会导致跨block读取导致网络堵塞)如果你需要定制1024b的分割量,修改即可
















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









