







 本文记录了在长时间未接触Hadoop和Spark后重新进行操作的过程,包括启动HDFS、YARN,开启Hive metastore服务,并确保9000和9083端口开放。通过将Hive配置文件复制到Spark的conf目录,可以避免使用Derby,使用Spark Shell连接Hive。遇到metastore实例化错误时,检查Spark和Hive的版本匹配问题,例如Hive 2.1.0与Spark 1.xx不兼容,升级到Hive 2.0.1即可解决问题。
本文记录了在长时间未接触Hadoop和Spark后重新进行操作的过程,包括启动HDFS、YARN,开启Hive metastore服务,并确保9000和9083端口开放。通过将Hive配置文件复制到Spark的conf目录,可以避免使用Derby,使用Spark Shell连接Hive。遇到metastore实例化错误时,检查Spark和Hive的版本匹配问题,例如Hive 2.1.0与Spark 1.xx不兼容,升级到Hive 2.0.1即可解决问题。
有3,4个月没接触hadoop和spark了,有些生疏,实习时用的是nodejs+python,今天休假,在新电脑跑跑大数据(真不敢相信我以前使用赛扬双核内存4G + 核显跑几个虚拟机来运行hadoop和spark的,跑个任务或者编译android源码有时等得蛋疼...)
虽然这些步骤常用好记,不过时间一长-没有-就又得查看doc,所以好记性不如烂笔头
1.开启hdfs
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start history
2.开启hive
配置metaservice已经记录过,不再写
hive --service metaservice
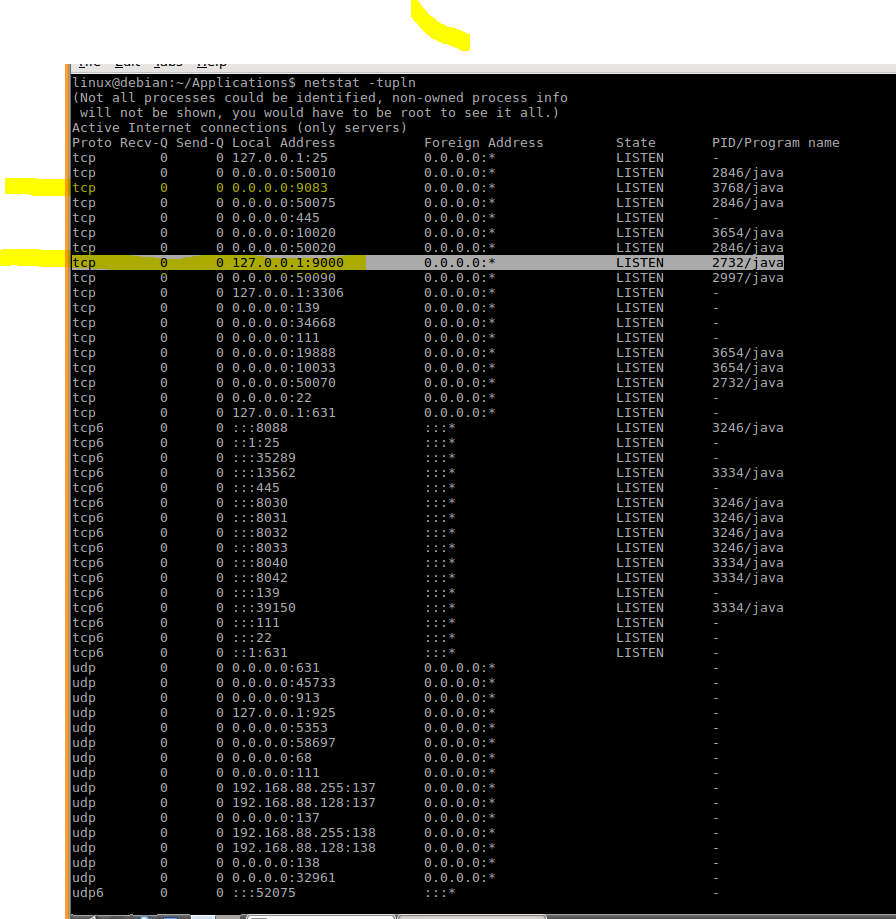
3.查看端口
确保9000和9083端口已经开启,9000为dfs,9083为hive metastore端口
4.连接hive
./hive
5.spark连接hive作为metastore,这样就不用derby了
拷贝三个文件到spark的conf中
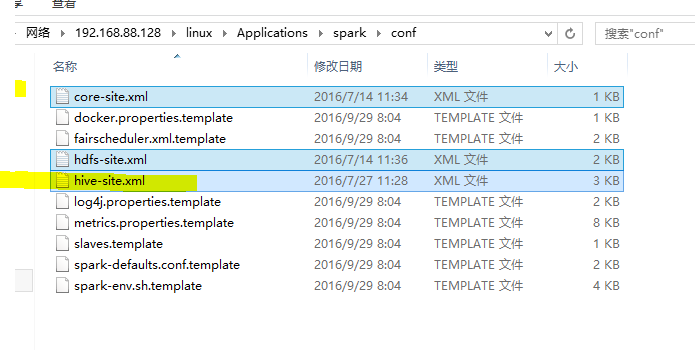
其中hive-site是这个步骤必要的,剩余两个是我们在spark中使用hive时也会经常用到的,如spark-sql
(查找doc得来的)
启动spark-shell
如果此时爆出metastore无法实例化的错误,就看看spark和hive的版本
我此前使用Hive 2.1.0 + spark1.xx就报错了,更新为2.0.1就没事了
















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









