







简介
项目叫 BigScience,
模型叫 BLOOM,
BLOOM 的英文全名代表着大科学、大型、开放科学、开源的多语言语言模型。
拥有 1760 亿个参数的模型.
BLOOM 是去年由 1000 多名志愿研究人员,学者 在一个名为“大科学 BigScience”的项目中创建的.
BLOOM 和今天其他可用大型语言模型存在的一个主要区别:该模型可以理解多达 46 种人类语言,包括法语、越南语、普通话、印度尼西亚语、加泰罗尼亚语、13 种印度语言(如印地语)和 20 种非洲语言。超过 30% 的训练数据是英文的。该模型还可以理解 13 种编程语言。
下载部署步奏
新建一个Anaconda conda 环境,然后安装 pytorch >1.3版本
下载模型
模型下载:https://huggingface.co/bigscience
打开以后 Models 模块就可以看到 它不同参数级别的模型 ,B代表英文简写亿 1B1,就代表模型的参数是1亿1千万.1B3好像丢失了下不了.
这里选择单击 bloom-1b1 模型,然后在单击 Files and versions ,下载所有文件,新建文件夹取名1b1,放里面.
加载本地模型,只要写上本地模型所在的目录
#分词
tokenizer = AutoTokenizer.from_pretrained('./1b1/')
#模型
model = AutoModelForCausalLM.from_pretrained('./1b1/')
3.运行代码,代码放到1b1父级目录
cmd调用模型代码
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
import torch
#从https://huggingface.co/bigscience/bloom-1b1/tree/main
#下载所有文件,放到新创建的文件夹1b1
checkpoint = "./1b1/"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)#分词
model = AutoModelForCausalLM.from_pretrained(checkpoint)#模型
#设置为gpu,推理更快
device = torch.device('cuda')
model.to(device)
#device=0表示使用第一个可用的GPU
generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer, device=0)
out = generator("你是谁?", max_length=30)
print(out[0]['generated_text']) #输出 "你是谁?我:她说"因为1B1只是一个文本生成模型,你给一个短语,它接着生成.没有问答功能.而且中文生成效果也不好.
GUI调用代码
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
import tkinter as tk
import torch
checkpoint = "./1b1/"
#分词
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
#模型
model = AutoModelForCausalLM.from_pretrained(checkpoint)
#设置为gpu,推理更快
device = torch.device('cuda')
model.to(device)
#device=0表示使用第一个可用的GPU
generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer, device=0)
def clean_string(s, substr): #substr=问题,s=回答
s = s.replace(substr, '')
lst = s.split(',')
result_lst = list(set(lst))
result_lst.sort()
result = ','.join(result_lst) + ','
return result
# 创建主窗口
root = tk.Tk()
root.title("Bloom:1亿3千万参数版")
root.geometry("800x600+{}+{}".format(root.winfo_screenwidth() // 2 - 400, root.winfo_screenheight() // 2 - 350))
# 创建输入框和滚动条
input_frame = tk.Frame(root)
input_label = tk.Label(input_frame, text="用户:")
input_text = tk.Text(input_frame, height=10, width=87,padx=6, pady=6)
input_scrollbar = tk.Scrollbar(input_frame)
input_text.config(yscrollcommand=input_scrollbar.set)
input_scrollbar.config(command=input_text.yview)
input_label.pack(side="left")
input_text.pack(side="left",pady=10)
input_scrollbar.pack(side="right", fill="y")
input_frame.pack()
# 创建按钮
button_frame = tk.Frame(root)
def show_text():
#清空 Tkinter Text 组件中的文本
output_text.delete('1.0', 'end')
input_str = input_text.get("1.0", "end-1c")
# 去掉最后一个换行符
if input_str.endswith('\n'):
input_str = input_str[:-1]
out = generator(input_str, max_length=30)
print(out[0])
anwer = out[0]['generated_text'] #clean_string(out[0]['generated_text'])
output_text.insert("end",anwer)
button = tk.Button(button_frame, text="回答", command=show_text,width=6, height=3)
button.pack(pady=10)
button_frame.pack()
# 创建输出框和滚动条
output_frame = tk.Frame(root)
output_label = tk.Label(output_frame, text="bloom:")
output_text = tk.Text(output_frame, height=26, width=87,padx=6, pady=6)
output_scrollbar = tk.Scrollbar(output_frame)
output_text.config(yscrollcommand=output_scrollbar.set)
output_scrollbar.config(command=output_text.yview)
output_label.pack(side="left",pady=10)
output_text.pack(side="left",pady=10)
output_scrollbar.pack(side="right", fill="y")
output_frame.pack()
def copy():
global text
text.event_generate("<<Copy>>")
def cut():
global text
text.event_generate("<<Cut>>")
def paste():
global text
text.event_generate("<<Paste>>")
# 创建右键菜单
menu = tk.Menu(root, tearoff=0)
menu.add_command(label="复制", command=copy)
menu.add_command(label="剪切", command=cut)
menu.add_command(label="粘贴", command=paste)
# 创建右键菜单2
menu2 = tk.Menu(root, tearoff=0)
menu2.add_command(label="复制", command=copy)
# 绑定鼠标右键(第一个文本框)
def show_menu1(event):
global text
text = input_text
menu.post(event.x_root, event.y_root)
input_text.bind("<Button-3>", show_menu1)
# 绑定鼠标右键(第二个文本框)
def show_menu2(event):
global text
text = output_text
menu2.post(event.x_root, event.y_root)
output_text.bind("<Button-3>", show_menu2)
# 创建按钮
button_frame = tk.Frame(root)
button = tk.Button(button_frame, text="回答", command=show_text,width=6, height=3)
# 响应回车键 绑定 <Return> 事件
root.bind("<Return>", lambda event: show_text())
root.lift()
# 运行主循环
root.mainloop()
生成300字效果

中英翻译 效果 不堪 ,诱导式
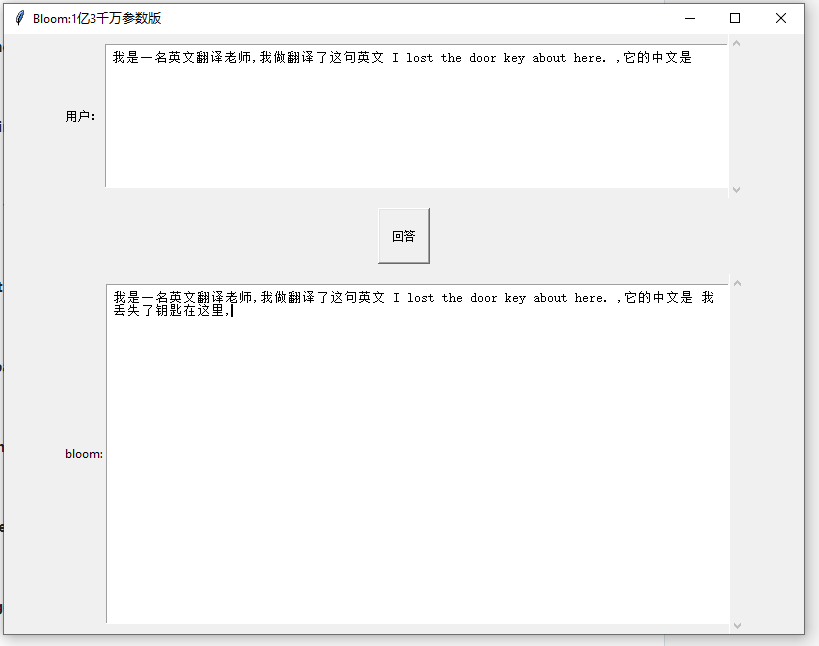
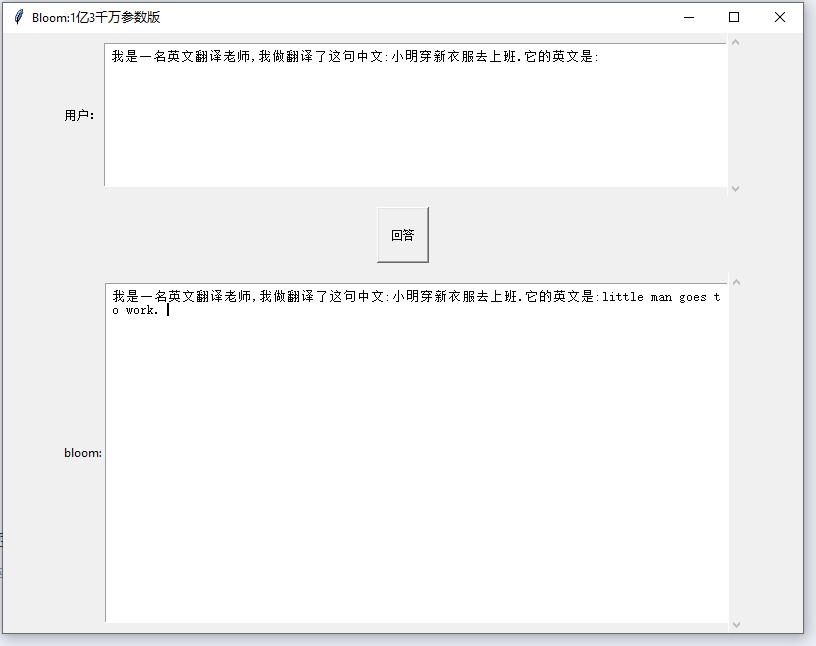
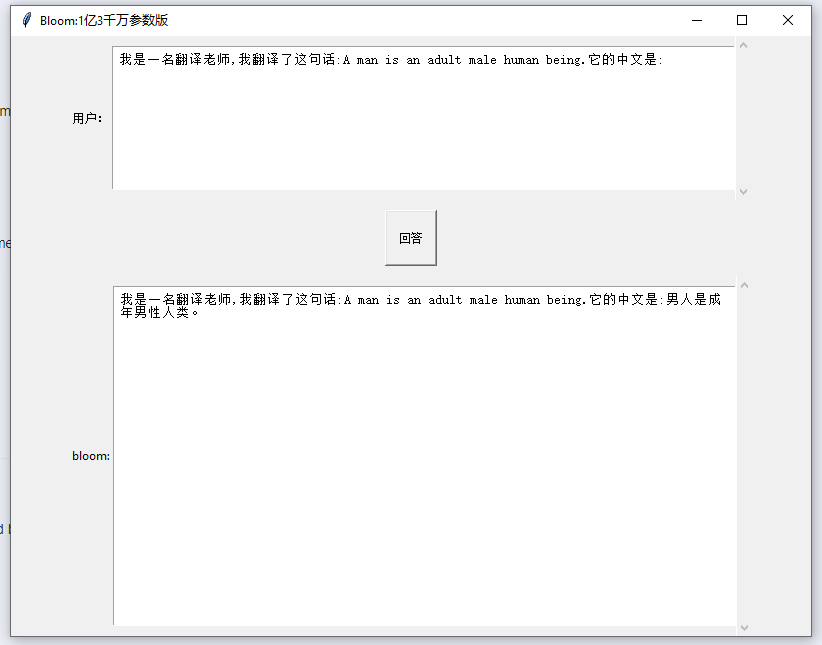
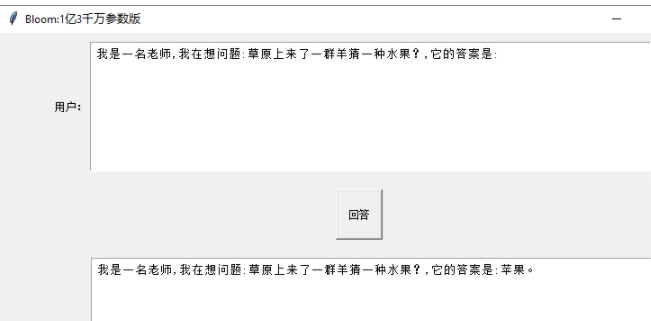
问答
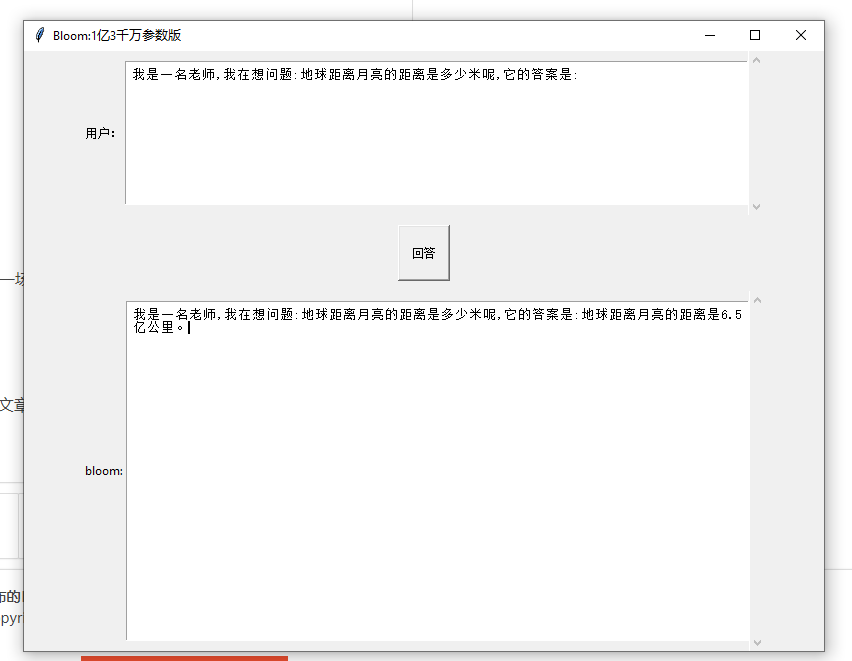
















 1430
1430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









