







Pandas 介绍

Pandas 是一个功能强大的 Python 数据分析工具库,常用于数据处理与分析工作。它为 Python 提供了快速、灵活以及表达能力强的数据结构,旨在简化“实际工作中”的数据操作,使得 Python 成为一种强大而高效的数据分析环境。
核心特性
-
数据结构:
- Series:一维标签数组,能够存储任意数据类型(整数、字符串、浮点数、Python 对象等)。轴标签统称为索引。
- DataFrame:二维标签数据结构,可以看作是具有共同索引的 Series 的集合。
-
处理数据:
- 读写不同格式的数据(CSV、Excel、数据库、HDF5等)。
- 清洗数据,如处理丢失数据(NA值)、删除重复值。
- 数据过滤、筛选、以及转换。
- 强大的数据聚合和转换功能。
-
数据对齐与缺失数据:
- 自动与显式数据对齐。对象之间的操作通常会对齐数据,并在必要时透明地处理缺失数据。
- 灵活处理缺失数据或不规则数据,并轻松地填充缺失数据或对数据进行插值。
-
时间序列:
- 简单、强大且高效的功能来执行时间序列数据的操作,如生成日期范围、转换频率、移动窗口统计等。
-
合并/连接数据集:
- 高效地对齐索引以连接/合并多个数据集。
- 提供多种方式来合并和连接数据集,如按索引合并、按列合并等。
-
分组操作:
- "拆分-应用-组合"操作使数据集可以被分组,并对每组应用一个函数,然后将结果合并回一起。
-
灵活的重塑与透视:
- 能够轻松地重塑(堆叠和展开)和透视数据表。
-
高性能:
- Pandas 的底层依赖于 NumPy(一种用于高效数学计算的 Python 库),使得 pandas 在处理大数据时保持良好的性能。
应用场景
Pandas 被广泛用于各种领域中的数据分析任务,包括但不限于金融、经济学、统计学、广告、Web 分析等。它是数据科学与机器学习项目中数据探索与清洗的重要工具。通过与诸如 NumPy、SciPy、Matplotlib、scikit-learn 和 statsmodels 等库的结合使用,pandas 提供了一个强大的环境,用于更广泛的科学计算应用。
为什么选择 Pandas?
选择使用 pandas 的原因很多,其核心优势在于它提供了一种高效、直观且高层的 API,使得数据操作和分析变得快捷和容易。Pandas 的设计目标就是简化复杂的数据操作,减少数据处理任务的编程负担。
如果你需要在 Python 中进行数据分析或数据处理,学习和使用 pandas 无疑是一个值得的投资。它将帮助你更高效地完成数据分析任务,释放出更多时间来关注数据的洞察与解释。
-
安装 Pandas:
pip install pandas -
导入 Pandas:
import pandas as pd
1. 创建 Pandas 数据结构
Pandas 有两种主要的数据结构:Series, DataFrame, 和单个元素(标量)。这些结构是构建和管理数据的基础。下面是对每一种数据结构的详细介绍:
1. Series 对象
Series 是一种一维的数组型对象,它包含了一个值序列(与NumPy的数组类似),并且每个值都有一个索引。索引在默认情况下是从0开始的整数,但也可以显式定义为其他类型的值(如字符串、日期等)。Series 可以被看作是一个定长、定序的字典,因为它是索引值到数据值的一个映射。
特点:
- 一维数组:
Series是一个一维数组结构,可以存储各种类型的数据(整数、字符串、浮点数、Python对象等)。 - 索引:每个
Series对象都有一个索引,索引链接到每个数据点。索引可以是数字系列,也可以是标签(如字符串)。
结构:
- 数据值(data values)
- 索引(index)
应用
由于每个 Series 对象都可以看作是数据表中的一列,它常常被用于表达数据表中的单个特征。例如,如果有一个包含多个人员信息的 DataFrame,其中可能包括姓名、年龄、城市等,这里的每一列(如“年龄”列)都可以被单独提取出来作为一个 Series 对象进行处理。
Series 是一维数据结构。
s = pd.Series([1, 3, 5, 7, 9])
print(s)2.DataFrame
DataFrame 是二维的表格型数据结构,非常类似于 Excel 表格。可以看作是Series 对象的容器。DataFrame 有行索引和列索引,每列可以是不同的值类型(数值、字符串、布尔值等),它既可以作为一个整体被高效地处理,也可以逐块进行处理。
data = {'Name': ['Tom', 'Jerry', 'Mickey'],
'Age': [20, 21, 22],
'Salary': [7000, 8000, 9000]}
df = pd.DataFrame(data)
3. 单个元素(标量)
在pandas中处理数据时,访问DataFrame或Series的单个值会返回一个标量。这个标量通常是Python原生数据类型(如int、float、str等)或者NumPy数据类型,取决于数据的具体类型。当你从DataFrame或Series中索引单个数据时,返回的就是一个标量。
1.创建df 依据 现有的字符串列名 和列表变量
要创建一个 DataFrame 依据现有的字符串列名和列表变量,你可以使用 Pandas 的 pd.DataFrame 函数,并传入一个字典,其中键是列名,值是相应的列表。每个列表的长度应该相同,因为它将对应于 DataFrame 的每一行。
以下是一个例子:
import pandas as pd
# 假设我们有以下列名
column_names = ['Name', 'Age', 'Salary']
# 和相应的列表变量
names = ['Tom', 'Jerry', 'Mickey']
ages = [20, 21, 22]
salaries = [7000, 8000, 9000]
# 创建一个字典,将列名映射到列表
data = {'Name': names, 'Age': ages, 'Salary': salaries}
# 使用这个字典创建 DataFrame
df = pd.DataFrame(data)
print(df)
2.添加一行数据
在 pandas DataFrame 中添加一行数据可以通过多种方法完成,包括使用 append() 方法或直接使用 loc 索引器。下面是两种常见的方法来添加一行数据到现有的 DataFrame。
方法 1:使用 append()
append() 方法可以用来向 DataFrame 添加新行。这种方法在 pandas 的新版本中已经不推荐使用(建议使用 concat()),但它仍然是一个简单直观的方法。以下是如何使用 append() 方法:
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Boston', 'Los Angeles']
}
df = pd.DataFrame(data)
# 创建一个新行的数据
new_row = {'Name': 'David', 'Age': 28, 'City': 'Miami'}
# 使用 append 方法添加行
df = df.append(new_row, ignore_index=True)
print(df)
方法 2:使用 loc[]
如果你知道新行的索引,可以直接使用 loc[] 索引器来添加或修改行。这种方法对于在特定位置插入数据特别有用:
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Boston', 'Los Angeles']
}
df = pd.DataFrame(data)
# 使用 loc 方法添加行
df.loc[len(df)] = ['David', 28, 'Miami']
print(df)
输出结果
执行上述代码后,你的 DataFrame 将包括一个新添加的行:

loc[] 索引器详解
loc[] 是一个基于标签的索引器,你可以使用它来访问 DataFrame 中的行或列。在添加行的情况下:
- 索引: 用
len(df)来确定新行的索引位置。因为 Python 的索引从0开始,len(df)总是指向当前 DataFrame 中下一个空闲的行位置。这是因为len(df)返回的是 DataFrame 的行数,正好也是新添加行的索引(因为索引从0开始计数)。
方法 3:使用 concat()
推荐的方法是使用 concat(),特别是当需要添加多行数据时。这里是如何用 concat() 添加单行的例子:
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Boston', 'Los Angeles']
}
df = pd.DataFrame(data)
# 创建一个新行的 DataFrame
new_row = pd.DataFrame([['David', 28, 'Miami']], columns=['Name', 'Age', 'City'])
# 使用 concat 方法添加行
df = pd.concat([df, new_row], ignore_index=True)
print(df)
3.添加列数据
在 pandas DataFrame 中添加列数据是一个常见的数据处理操作,可以根据特定的需求以多种方式完成。以下是几种向 DataFrame 添加新列的基本方法:
方法 1:直接赋值
最直接的方法是使用列名称和一个值或一系列值来为 DataFrame 添加列。如果你提供单一值,pandas 会将这个值广播到整个列中。如果提供的是一个列表或系列,那么这些值将逐行填充。
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
# 添加一个新列,所有行的值都是同一个值
df['Sex'] = 'Female'
# 添加一个新列,每行的值不同
df['Salary'] = [50000, 60000, 70000]
print(df)
方法 2:使用 assign()
assign() 方法可以在不修改原始 DataFrame 的情况下添加新列。这是一个非常有用的功能,特别是在链式调用中。
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
# 使用 assign 方法添加一个列名为 ‘Salary’ 的新列, 传递一个包含三个整数的列表 [50000, 60000, 70000]。这三个数值将分别对应 DataFrame 中三行的薪资信息。
df = df.assign(Salary=[50000, 60000, 70000])
# 使用 assign 方法添加一个列名为 'Sex' 的新列,这列的值对于所有行都是相同的,即 'Female'。由于我们提供了一个单一的字符串,pandas 将这个值广播到 DataFrame 的每一行。
df = df.assign(Sex='Female')
#同时添加两列
# 准备添加的全新列数据
birthdates = ['1995-02-15', '1988-08-23', '1993-07-04'] # 出生日期
job_titles = ['Engineer', 'Designer', 'Manager'] # 职务
# 使用 assign 方法同时添加两个完全新的列
df = df.assign(Birthdate=birthdates, JobTitle=job_titles)
print(df)
方法 3:使用 insert()
如果你需要在特定的位置插入一列,可以使用 insert() 方法。你可以指定列的位置(索引号),列的名称和列的值。
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
# 使用 insert 方法在指定位置插入新列
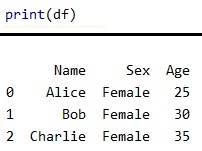
df.insert(1, 'Sex', 'Female')
print(df)
输出结果
执行上述代码后,你的 DataFrame 将包含一个新的列 "Sex",位置在 "Name" 列之后,"Age" 列之前:
insert() 方法详解
insert() 方法的调用格式如下:
DataFrame.insert(loc, column, value, allow_duplicates=False)- loc: 整数,指定了新列插入的位置的索引。索引
0表示最前面,len(df.columns)表示最后面。在我们的例子中,1表示新列将放在第二的位置(索引从 0 开始计数)。 - column: 字符串,是新添加的列的名称。
- value: 可以是单个值或与 DataFrame 行数相等的数组。如果是单个值,它将被广播到所有行。
- allow_duplicates: 布尔值,默认为
False。如果设置为True,允许插入名称已存在的列。
索引的重要性
在使用 insert() 方法时,选择正确的索引是关键。索引值决定了新列将出现在 DataFrame 中的哪个位置。这对于数据的展示顺序非常重要,尤其是在准备数据报告或执行数据可视化时。调整 loc 参数,你可以精确控制列的插入位置。
方法 4:使用字典扩展
如果新列的数据是通过现有列计算得出的,你也可以通过字典方式添加新列。例如,我们基于年龄添加一个描述列:
import pandas as pd
# 假设已有的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
# 添加新列,基于其他列的数据
df['Age Group'] = df['Age'].apply(lambda x: 'Young' if x < 30 else 'Adult')
print(df)
4. 数据的读取和写入
读取 CSV 文件
df = pd.read_csv('filename.csv')1.写入 CSV 文件
使用 to_csv() 方法将 DataFrame 数据导出到 CSV 文件,同时指定编码为 UTF-8。
df.to_csv('output.csv', index=False, encoding='utf-8-sig')参数解释
index=False: 这个参数确保不将 DataFrame 的索引作为一列数据写入 CSV 文件中。如果你想保留索引,可以将此参数设置为True。encoding='utf-8-sig': 这个参数指定文件的编码。使用'utf-8-sig'而非'utf-8'是为了在某些情况下避免出现带有 BOM(字节顺序标记)的问题,这在一些老旧的程序或系统中读取 UTF-8 编码的文件时可能会遇到。这样可以确保文件的兼容性更强。
2.写入到 Excel 文件
将数据从 pandas DataFrame 写入到 Excel 文件,你可以使用 to_excel() 方法。这是一个非常有用的功能,尤其是当你需要与不熟悉编程的同事共享数据时。下面是如何使用 to_excel() 方法将 DataFrame 数据写入 Excel 文件的步骤:
1. 首先,确保安装了 openpyxl
pandas 的 to_excel() 方法依赖于 openpyxl(或 xlsxwriter)库来写入 Excel 文件(.xlsx)。如果你还没有安装这些库,可以通过以下命令安装:
pip install openpyxl2. 使用 to_excel() 方法
以下是将 DataFrame 写入 Excel 文件的基本语法:
import pandas as pd
# 创建一个示例 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Boston', 'Los Angeles']
}
df = pd.DataFrame(data)
# 写入到 Excel 文件
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)
详细参数说明
- 文件名:
'output.xlsx'是要写入的文件名。 - sheet_name:
'Sheet1'是工作表的名称。 - index: 设置为
False以避免将 DataFrame 的索引也写入到 Excel 文件中。如果你希望索引也被写入,可以设置为True。
3. 进阶选项
-
多个工作表:你可以将不同的 DataFrames 写入到同一个 Excel 文件的不同工作表中。
import pandas as pd # 创建第一个DataFrame data1 = { 'Column1': [1, 2, 3], 'Column2': ['A', 'B', 'C'] } df = pd.DataFrame(data1) # 创建第二个DataFrame data2 = { 'Column1': [4, 5, 6], 'Column2': ['D', 'E', 'F'] } df2 = pd.DataFrame(data2) # 将两个DataFrame写入同一个Excel文件的不同工作表 with pd.ExcelWriter('output.xlsx', engine='openpyxl') as writer: df.to_excel(writer, sheet_name='Sheet1', index=False) df2.to_excel(writer, sheet_name='Sheet2', index=False) -
指定列写入:如果你只想写入某些特定的列,可以在
to_excel()方法中使用columns参数。df.to_excel('output.xlsx', sheet_name='Sheet1', columns=['Name', 'City'], index=False)
5. pandas 中的不同数据访问和修改方法
行列选择 [] ,loc[],iloc[]
单个元素 at[] ,iat[]
这里的标签就是列名称,位置就是已知行列索引位置时
| 方法 | 描述 | 最佳使用场景 | 示例代码 |
|---|---|---|---|
[] | 直接访问列 | 当需要访问一个或多个列,且不涉及行选择时。 | df['Age'] 或 df[['Name', 'City']] |
loc[] | 基于标签的索引器 | 需要通过行标签或列标签选择数据,或使用条件表达式选择行时。 | df.loc[0] 或 df.loc[:, 'Name'] 或 df.loc[df['Age'] > 30] |
iloc[] | 基于位置的索引器 | 需要通过行列的位置(整数索引)快速访问数据时。 | df.iloc[0] 或 df.iloc[:, 1] 或 df.iloc[1:3, 0:2] |
at[] | 快速访问单个元素(基于标签) | 当确切知道所需数据的标签,并且频繁访问单个元素时。 | df.at[0, 'Age'] |
iat[] | 快速访问单个元素(基于位置) | 当确切知道所需数据的位置索引,并且频繁访问单个元素时。 | df.iat[0, 1] |
query() | 使用字符串表达式查询 DataFrame | 处理复杂的查询逻辑时,能提供更清晰和简洁的语法。 | df.query('Age > 30') |
| 布尔索引 | 直接根据条件过滤 | 需要根据条件动态过滤行时,特别是处理大型数据集时。 | df[df['Age'] > 30] |
where() | 保留满足条件的数据,其他为 NaN | 当需要保留满足条件的数据同时标记不满足条件的数据时。 | df.where(df['Age'] > 30) |
mask() | 替换满足条件的数据为 NaN | 当需要隐藏或替换满足条件的数据,同时保留不满足条件的数据时。 | df.mask(df['Age'] > 30) |
1.使用场景详解:
[]:适用于快速简单地访问列,或进行列的简单操作(如添加新列)。loc[]:非常适合处理需要根据标签索引进行选择的情况,如选择特定行数据或基于条件选择某些行。iloc[]:当你不需要考虑 DataFrame 的实际索引标签,只需要根据数据的位置进行操作时,iloc[]是最佳选择。at[]和iat[]:这两种方法是访问单个元素的最快方法,特别适合在循环或迭代中频繁访问单个数据点。query():当查询条件较复杂,或者希望使代码更易于阅读和维护时,使用query()可以使代码更加优雅。- 布尔索引:适用于基于复杂逻辑条件进行数据筛选,特别是当条件涉及多个列时。
where()和mask():这两个方法提供了一种灵活的方式来处理 DataFrame 数据的可视化或预处理,允许通过条件逻辑保留或替换数据。
2.示例代码详解:
-
[]:- 单列访问:
df['Age']— 这行代码返回包含DataFrame中所有'Age'列数据的Series。 - 多列访问:
df[['Name', 'City']]— 这行代码返回一个新的DataFrame,仅包含'Name'和'City'这两列。
- 单列访问:
-
loc[]:- 单行访问:
df.loc[0]— 返回DataFrame中索引为0的行。 - 单列访问:
df.loc[:, 'Name']— 返回DataFrame中所有行的'Name'列。 - 条件访问:
df.loc[df['Age'] > 30]— 返回所有'Age'大于30的行组成的DataFrame。
- 单行访问:
-
iloc[]:- 单行访问:
df.iloc[0]— 返回DataFrame中第一行的数据。 - 列访问:
df.iloc[:, 1]— 返回DataFrame中第二列的所有数据。 - 范围访问:
df.iloc[1:3, 0:2]— 返回DataFrame从第二行到第三行,从第一列到第二列的数据。
- 单行访问:
-
at[]和iat[]:df.at[0, 'Age']— 快速访问第一行的'Age'列的值。这是访问单个值的最快方式,适用于已知行列标签时。df.iat[0, 1]— 快速访问第一行第二列的值。使用位置而不是标签进行访问,适用于已知行列索引位置时。
-
query():- 使用字符串表达式查询年龄大于30的行:
df.query('Age > 30')— 这行代码利用一个字符串表达式来过滤DataFrame,返回所有'Age'大于30的行。
- 使用字符串表达式查询年龄大于30的行:
-
布尔索引:
- 选择年龄大于30的所有行:
df[df['Age'] > 30]— 直接使用条件表达式过滤DataFrame,返回满足条件的行。
- 选择年龄大于30的所有行:
-
where():df.where(df['Age'] > 30)— 这行代码返回一个新的DataFrame,其中不满足条件的行会被替换为NaN值。适用于需要保留数据结构同时标记不符合条件的数据时。
-
mask():df.mask(df['Age'] > 30)— 相反地,这行代码返回一个新的DataFrame,其中满足条件的行的数据会被替换为NaN值。这可以用于隐藏或删除某些数据
6. loc[] 详解
loc[] 索引器是 pandas 中非常强大的工具,它允许你通过标签来访问和修改 DataFrame 的行和列。下面我会详细解释如何使用 loc[] 来访问和操作特定的行和列。
loc根据访问对象返回不同的类型
- 当使用 .loc 来访问单个元素时,它会返回该元素的值。
- 如果选择一行或一列数据,
.loc通常返回一个 Series 对象。 - 如果选择行和列的特定子集,
.loc返回的是一个 DataFrame 对象。
import pandas as pd
# 创建一个 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 访问单个元素
element = df.loc[0, 'Age']
print("单个元素:")
print(element)
print(type(element))
print() # 用于添加空行
# 选择一列数据
column = df.loc[:, 'Age']
print("一列数据:")
print(column)
print(type(column))
print()
# 选择一行数据
row = df.loc[0]
print("一行数据:")
print(row)
print(type(row))
print()
# 选择多行多列
subset = df.loc[0:1, ['Name', 'Age']]
print("多行多列:")
print(subset)
print(type(subset))
print()
输出结果

访问单个元素
import pandas as pd
# 创建一个简单的DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
}
df = pd.DataFrame(data)
# 使用df.loc[0, 'Age']
result_loc = df.loc[0, 'Age']
print("df.loc[0, 'Age']:", result_loc)
print("df.loc[0, 'Age'] 类型:", type(result_loc))
# 使用df.at[0,'Age']
result_at = df.at[0, 'Age']
print("df.at[0, 'Age']:", result_at)
print("df.at[0, 'Age'] 类型:", type(result_at))输出结果
df.loc[0, 'Age']: 25
df.loc[0, 'Age'] 类型: <class 'numpy.int64'>
df.at[0, 'Age']: 25
df.at[0, 'Age'] 类型: <class 'numpy.int64'>
df.loc[0, 'Age'] 和 df.at[0, 'Age'] 这两个表达式返回的结果是一样的,它们都用于获取DataFrame中第0行(第一行)'Age’列的值。其中 0 是行索引,'Age' 是列名。
不过,两者之间存在一些差异:
性能:df.at[] 比 df.loc[] 更快,因为 df.at[] 专门用于访问单个元素,而 df.loc[] 则更为通用,可以用于选择多行或多列。
灵活性:df.loc[] 更加灵活,可以用于选择多行或多列,也可以用于进行切片等复杂的数据选择。而 df.at[] 只能用于访问单个具体的元素。
在只需要访问单个数据点时,推荐使用 df.at[] 以获得更好的性能;在需要访问多个数据或进行复杂的数据选择时,应使用 df.loc[]。在功能上,如果只是访问单个数据点,两者的结果是相同的。
.loc 方法可以用于更灵活的数据访问方式,包括选择行和/或列的子集,这时它可能返回 Series 或 DataFrame 对象,具体取决于选择的内容:
访问单个行或列
使用 loc[],你可以通过指定行标签(索引名称)和列标签来访问特定的行或列。
import pandas as pd
# 创建一个 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 访问单个行
print(df.loc[0]) # 访问索引为0的行
# 访问单个列
print(df.loc[:, 'Name']) # 访问名为'Name'的列
访问多个行或列
你可以通过传递一个列表来访问多个行或列。
# 访问多个行
print(df.loc[[0, 2]]) # 访问第1行和第3行的数据
# 访问多个列
print(df.loc[:, ['Name', 'City']]) # 访问'Name'和'City'两列
访问行和列的特定组合
loc[] 同时允许你通过指定行和列的组合来访问数据。
# 访问特定行的特定列
print(df.loc[1, 'Age']) # 访问索引为1的行的'Age'列
# 访问多个行的多个列
print(df.loc[[0, 1], ['Name', 'City']])
条件访问
loc[] 也可以与布尔条件一起使用,使你能够基于列的值来选择行。
# 条件访问
print(df.loc[df['Age'] > 30]) # 访问'Age'大于30的所有行
# 条件访问特定列
print(df.loc[df['Age'] > 30, 'Name']) # 访问'Age'大于30的行的'Name'列
修改 DataFrame 中的数据
loc[] 不仅可以用于访问数据,还可以用于修改数据。你可以指定行列位置来更新 DataFrame 中的数据。
# 修改特定元素
df.loc[0, 'Name'] = 'Ann' # 将索引为0的行的'Name'修改为'Ann'
# 修改一行数据
df.loc[2] = ['Dave', 29, 'Miami'] # 修改索引为2的整行数据
# 修改一列数据
df.loc[:, 'City'] = ['City1', 'City2', 'City3'] # 修改整列数据
print(df)
通过这些示例,你可以看到 loc[] 的使用是非常灵活的,它可以访问和修改单个值、整行或整列,以及行和列的任意子集。
7. 几种 pandas 数据访问和操作方法
1. 使用 at[] 和 iat[]
at[] 例子
at[] 主要用于访问和修改单个元素。它的优势在于速度,特别是当你需要频繁访问和修改单个元素时。
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 修改使用 at[]
df.at[0, 'Name'] = 'Alison'
print("Updated Name:", df.at[0, 'Name'])
# 访问使用 at[]
print("Access single element with at[]:", df.at[2, 'City'])iat[] 例子
与 at[] 类似,iat[] 用于通过位置访问和修改单个元素,适合已知行列位置的情况。
# 修改使用 iat[]
df.iat[0, 0] = 'Alice'
print("Updated Name:", df.iat[0, 0])
# 访问使用 iat[]
print("Access single element with iat[]:", df.iat[2, 2])
2. 使用 query() 方法
query() 方法可以让您使用字符串形式的表达式来查询 DataFrame,这使得代码更易于编写和阅读,特别是在处理复杂条件时。
# 查询年龄大于 30 的行
adults = df.query('Age > 30')
print("Adults:", adults)3. 布尔索引
布尔索引允许您直接根据条件过滤数据,这是 pandas 中非常直观和强大的数据筛选技术。
# 直接使用布尔条件选择行
over_30 = df[df['Age'] > 30]
print("People over 30:", over_30)
# 结合多个条件
over_30_in_ny = df[(df['Age'] > 30) & (df['City'] == 'New York')]
print("People over 30 in NY:", over_30_in_ny)
4. 使用 where() 和 mask()
这两个方法用于基于条件选择数据,where() 在条件为 False 的地方放置 NaN,而 mask() 则在条件为 True 的地方放置 NaN。
# 使用 where,不满足条件的位置将被设置为 NaN
where_filtered = df.where(df['Age'] > 30)
print("Where filtered:", where_filtered)
# 使用 mask,满足条件的位置将被设置为 NaN
mask_filtered = df.mask(df['Age'] > 30)
print("Mask filtered:", mask_filtered)
5. 结合修改
使用这些方法不仅可以查询数据,还可以结合修改操作,如更新或改变数据。
# 使用 loc 来增加年龄
df.loc[df['Age'] > 30, 'Age'] += 1
print("Ages incremented for people over 30:", df)
# 使用 query 和 loc 修改数据
df.loc[df.query('City == "Chicago"').index, 'City'] = "Chicago - IL"
print("Updated city name for Chicago:", df)
8. query()
使用 query() 方法可以非常方便地处理更复杂的查询条件,并使代码更加清晰。下面我将举例说明如何使用 query() 方法执行各种不同的查询操作,这些示例将涵盖多条件查询、字符串匹配以及使用外部变量等情况。
示例数据集
首先,让我们定义一个包含更多详细信息的示例 DataFrame。
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Ella'],
'Age': [25, 30, 35, 40, 22],
'City': ['New York', 'Los Angeles', 'Chicago', 'Miami', 'Boston'],
'Income': [70000, 85000, 65000, 72000, 80000] #收入
}
df = pd.DataFrame(data)
1. 基础查询
查询年龄大于30岁的成年人:
adults = df.query('Age > 30')
print("Adults over 30:\n", adults)
2. 多条件查询
查询年龄大于 30 并且收入超过 70000 的人:
如果你的查询更加复杂,例如包含多个 and 和 or 条件,确保适当使用括号来组织优先级,避免逻辑错误。
#查询年龄大于 30 并且 收入超过 70000 的人
result = df.query('Age > 30 and Income > 70000')
print("Adults over 30 with income over 70000:\n", result)
#查询年龄大于 30 或者 收入超过 70000 的人,你可以使用 or 运算符
result = df.query('Age > 30 or Income > 70000')
print("People over 30 or with income over 70000:\n", result)
3. 字符串操作查询
查询城市名称以 'New' 开头的所有记录:
new_cities = df.query('City.str.startswith("New")', engine='python')
print("People in cities starting with 'New':\n", new_cities)
#查询所有在以 "os" 结尾的城市名的记录:
ends_with_os = df.query('City.str.endswith("os")', engine='python')
print("People in cities ending with 'os':\n", ends_with_os)
4. 使用外部变量
假设我们有一个外部变量,我们希望在查询中使用这个年龄阈值:
age_threshold = 25
result = df.query('Age > @age_threshold')
print(f"People older than {age_threshold}:\n", result)
5. 使用索引查询
如果要基于 DataFrame 的索引进行查询,假设索引是一个特定的属性(例如设置'Name'为索引后的查询):
#设置索引,将'Name'列 DataFrame 的设置为索引。这意味着该列的值将被用作行标识符(即索引),而不再是 DataFrame 中的普通列。inplace=True 参数意味着更改将直接在原始 DataFrame 上进行,而不是创建一个新的 DataFrame。
df.set_index('Name', inplace=True)
# 使用 query() 方法来查找索引(此处索引是人名)为 "Alice" 的行。这里的 'index' 是一个特殊的关键字,在使用 query() 方法时,它代表 DataFrame 的索引。
result = df.query('index == "Alice"')
#这一行代码打印出索引值为 "Alice" 的所有行的信息。如果 "Alice" 是唯一的,那么只会返回一行,包含 Alice 的所有数据(除了 Name,因为它现在是索引)。
print("Data for Alice:\n", result)
6. 组合字符串条件
查询名字包含 'a' 且收入低于 80000 的人:
result = df.query('Name.str.contains("a") and Income < 80000', engine='python')
print("People with 'a' in their names and income less than 80000:\n", result)
9. 索引
在Pandas中,索引(Index)是用来标识数据帧(DataFrame)或者序列(Series)的行的标签。索引是数据处理和分析的关键组件,因为它允许快速访问、定位和修改数据。以下是关于Pandas索引的一些详细信息和重要概念:
1. 索引的类型
Pandas提供了多种类型的索引,每种类型都有其特定的用途和性能特点:
- RangeIndex:这是最常见的索引类型,类似于Python的range对象。当你创建一个新的DataFrame而没有指定索引时,默认会创建一个从0开始的整数序列。
- Int64Index:用于存储整数的索引。
- Float64Index:用于存储浮点数的索引,不常用。
- DatetimeIndex:特别用于存储日期时间值,非常有用于时间序列数据。
- PeriodIndex:用于存储周期性数据(例如,具有特定频率的日期范围)。
- CategoricalIndex:基于类别数据创建的索引,可以提高性能和内存效率。
- MultiIndex(层次化索引):允许你在一个轴上拥有多个(两个以上)索引级别,非常适合处理高维数据。
2. 设置索引
你可以通过set_index()方法将DataFrame中的一个或多个列转换为索引,也可以在创建DataFrame时通过index参数直接设置。
df.set_index('Column_Name', inplace=True)
# 或在创建时指定
df = pd.DataFrame(data, index=my_index)
在 Pandas 中设置索引列时,虽然你可以将任何列设置为索引,但有一些最佳实践和考虑因素可以帮助你更有效地使用索引,确保数据结构的优化和数据操作的效率。以下是设置索引列时应考虑的几个要点:
1. 唯一性
虽然索引不强制要求必须唯一,但最好使用具有唯一值的列作为索引。唯一的索引值可以提高数据检索的效率,使得每个索引值精确对应一行数据,避免在使用索引访问数据时出现混淆或错误。
2. 不变性
索引列的值最好是不变的。使用不会随时间改变的数据(如用户ID、产品序列号等)作为索引,可以避免因索引变化导致的数据一致性问题。
3. 有意义
索引列应该是有意义的,即它应该对数据分析和操作有实际的帮助。例如,如果你经常需要通过某个特定的字段(如客户ID、时间戳等)来查询数据,那么将这个字段设置为索引会使查询操作更加高效。
4. 数据类型
考虑索引列的数据类型。数值型或日期型的索引通常比字符串型的索引更高效。如果索引列是字符串类型,确保这些字符串不会过长,因为过长的字符串作为索引会增加存储开销并可能影响检索性能。
5. 避免空值
尽量避免在索引列中使用包含空值(NaN)的列。空值在索引中可能导致不预期的行为或错误。
示例
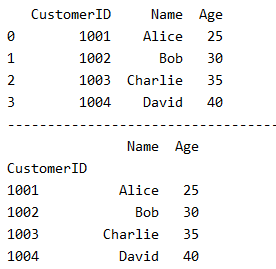
考虑以下数据集,我们将根据上述标准选择合适的索引:
import pandas as pd
data = {
'CustomerID': [1001, 1002, 1003, 1004],
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40]
}
df = pd.DataFrame(data)
print(df)
print('----------------------------------------')
# 设定 CustomerID 为索引
df.set_index('CustomerID', inplace=True)
print(df)
这里,CustomerID 是一个好的索引选择,因为它满足唯一性和不变性的要求,同时对数据操作有实际帮助(如查找特定客户的记录)。
输出结果
3. 重置索引
如果你需要将索引列转回数据列,或者想要重置索引为默认的整数索引,可以使用reset_index()方法。
df.reset_index(inplace=True)
4. 索引的操作
索引使得数据的切片和访问非常高效。你可以通过索引标签或位置快速访问数据:
df.set_index('Column_Name', inplace=True)
# 或在创建时指定
df = pd.DataFrame(data, index=my_index)
5. 索引的性能
设置合适的索引可以显著提高数据查询的性能。对于大数据集,建议使用适合数据特性的索引类型(例如,对于时间序列数据使用DatetimeIndex)。
6. 索引的陷阱
- 修改索引:直接在原索引上修改是不被允许的,因为索引对象是不可变的(Immutable)。如果需要修改索引,你可以替换整个索引或者使用以上的重置方法。
- 索引的对齐:在进行数据操作时,如两个DataFrame相加,Pandas会根据索引来对齐数据,这可能会导致非预期的结果。因此,明确索引的对齐方式是很重要的。















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









