







"结巴"中文分词是Python中文分词组件,作者从三个方面描述jieba中文分词的算法
1. 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
2. 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
3. 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
我从源代码的角度分为三部分对jieba中文分词进行分析,
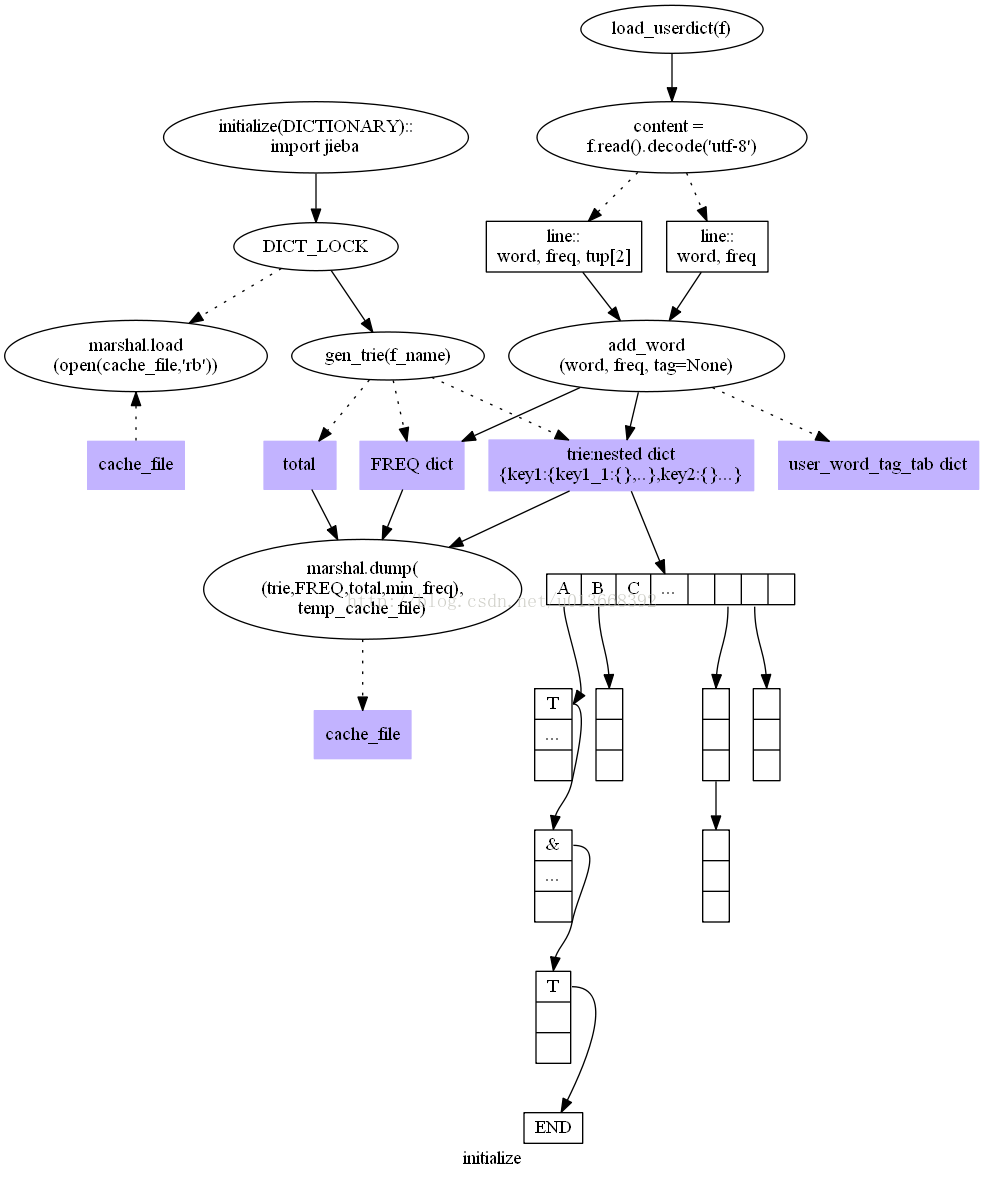
第一部分Jieba分词的初始化,包括核心词典和用户词典的加载,这一部分涉及最基础的数据结构,有:
trie又称前缀树或字典树,jieba中的具体实现是一个嵌套的dict,它用于存储词典;
l FREQ在jieba中的具体实现是一个dict,它存储词和词频的对应关系;
l min_freq存储最小的词频;
l total存储所有词的词频的总和。
第三部分介绍jieba中文分词组件中的HMM模型和Viterbi算法应用















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









