









 文章探讨了两种针对大型Transformer模型的量化方法——ZeroQuant和SmoothQuant。ZeroQuant采用动态的激活量化和静态的权重量化,而SmoothQuant通过平滑激活异常值来减轻量化误差。两者都关注于处理激活值的分布不均和离群点问题,以实现高效且精度损失小的量化。文章还讨论了量化策略,如per-token、per-channel和group-wise量化,以及它们在不同模型组件上的应用。知识蒸馏在ZeroQuant中的应用使得量化过程无需原始数据集。文章指出,SmoothQuant的简单性和ZeroQuant的通用性是两者的重要特点。
文章探讨了两种针对大型Transformer模型的量化方法——ZeroQuant和SmoothQuant。ZeroQuant采用动态的激活量化和静态的权重量化,而SmoothQuant通过平滑激活异常值来减轻量化误差。两者都关注于处理激活值的分布不均和离群点问题,以实现高效且精度损失小的量化。文章还讨论了量化策略,如per-token、per-channel和group-wise量化,以及它们在不同模型组件上的应用。知识蒸馏在ZeroQuant中的应用使得量化过程无需原始数据集。文章指出,SmoothQuant的简单性和ZeroQuant的通用性是两者的重要特点。
ref
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
ZeroQuant与SmoothQuant是比较新的大模型量化方法,都提出了相应的方法来缓解激活outlier导致的量化误差,并且都采用后量化而不是量化感知训练的方法,使得量化成本相对低,实现难度相对较低。
量化基础
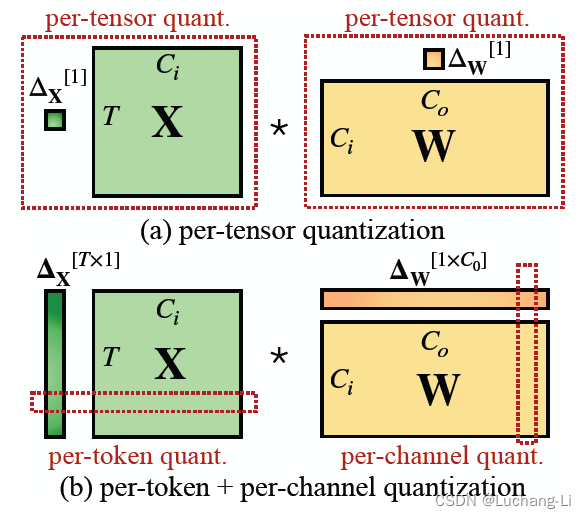
per-token quantization:每个token对应的tensor共享量化系数
per-channel quantization
group-wise quantization: A coarse-grained version of per-channel quantization is to use different quantization steps for different channel groups. Q-BERT (Q-bert: Hessian based ultra low precision quantization of bert)提出的。把多个channel合在一起用一组量化系数,相比每个chennel用单独的量化系数确实要coarse一些。
per-axis量化:多维tensor指定某一个维度,在该维度上,每个索引的子tensor共享量化系数。显然通过指定相应的axis即可得到per-channel或者per-token量化。

activation outliers
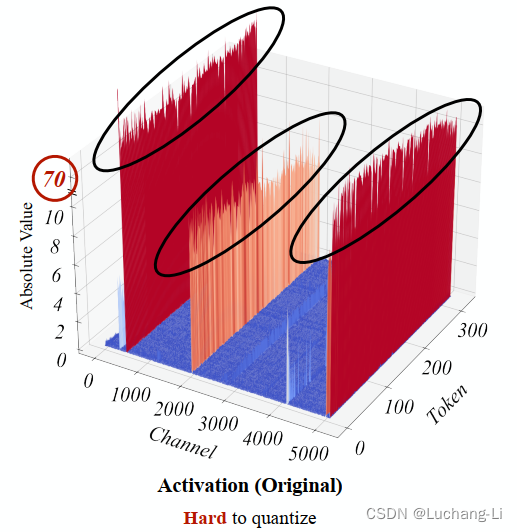
不像weight权重数值分布比较均匀接近,很少有离群点。激活值可能存在较大的分布差异,较多离群点导致量化缩放系数太大,导致很大的量化误差。
ZeroQuant量化
动态还是静态量化:
dynamic per-token activation quantization and static group-wise weight quantization
对称还是非对称量化?激活和权重都是对称量化。
量化方法1: 不需要知识蒸馏
激活采用per-token动态量化,权重采用per-group静态量化,group采用48或64。
量化方法2: 结合逐层知识蒸馏
不需要原始数据集, 可以用于4bit量化
不像传统的量化感知训练和知识蒸馏直接训练全部参数和量化参数,ZeroQuant的方法是一次只训练一个transformer层。

前L-1层的结果techer和student模型都用的techer模型的结果?
知识蒸馏训练的参数是什么?因为激活是动态量化,这里只训练更新权重?
MSE计算为何要做前L层所有结果乘积的的误差,而不是直接第L层结果的误差?
论文中没有展示只有TQ (token-wise activation quantization)而没有group-wise量化的精度,因为不清楚TQ和group weight quant哪个更重要,以及有TQ时是否还有必要group-wise量化。
性能优化:把量化、反量化算子融合到其他算子计算中中。
SmoothQuant量化
Since weights are easy to quantize while activations are not.
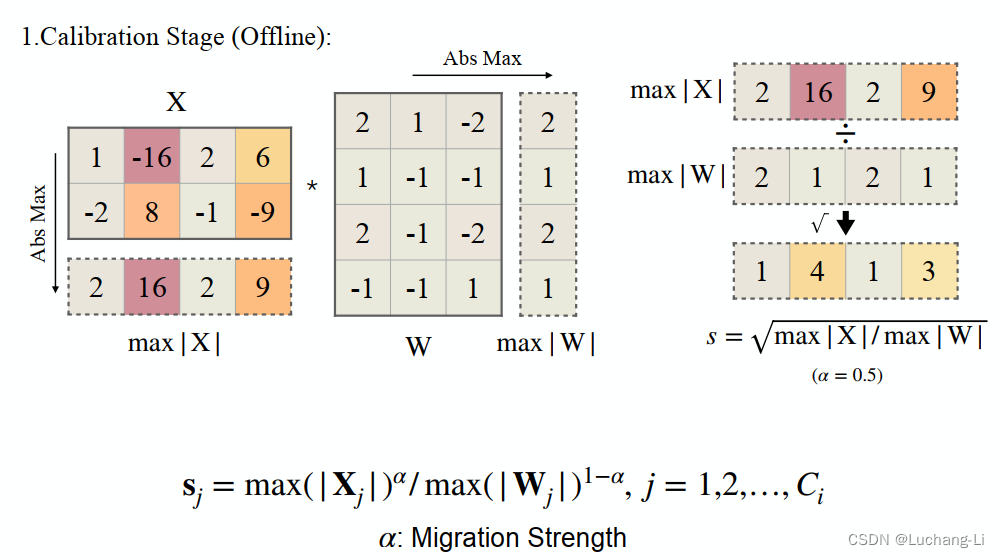
SmoothQuant smooths the activation outliers by offline migrating the quantization difficulty from activations to weights with a mathematically equivalent transformation.
SmoothQuant enables an INT8 quantization of both weights and activations for all the matrix multiplications in LLMs
观察结果:
Outliers persist in fixed channels
Fixed channels have outliers, and the outlier channels are persistently large.
算法原理
仔细看明白了会发现这个方法非常简单。其中diag(v)函数是根据向量生成一个对角线上元素为v,其余为0的矩阵,Xdiag(s)^-1相当于把X的每一行分别除以v中的元素,而不需要真的去做这个矩阵乘。

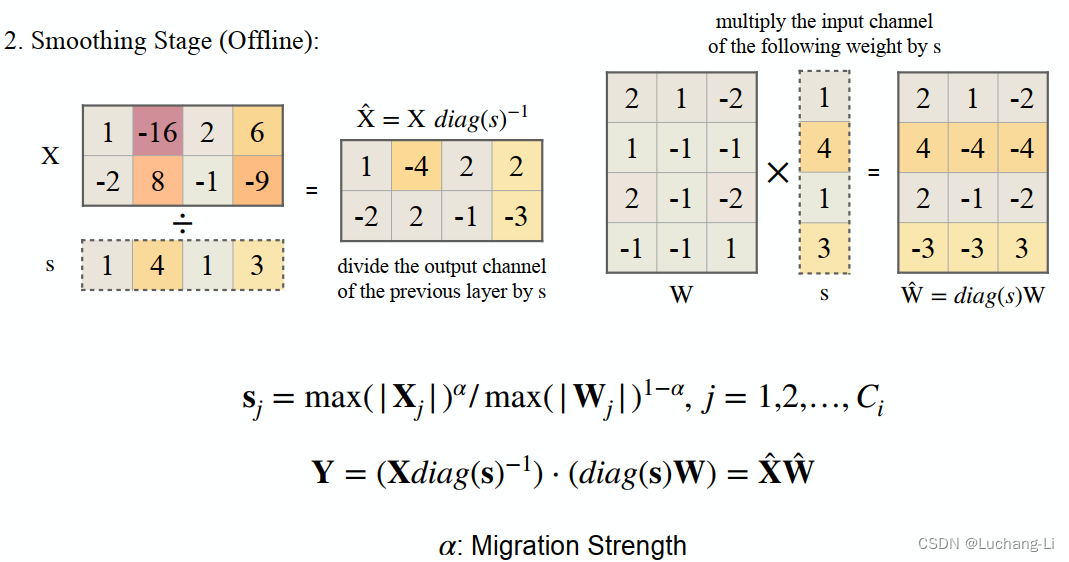
具体量化配置:
可见其可以采用动态也可以采用静态量化。
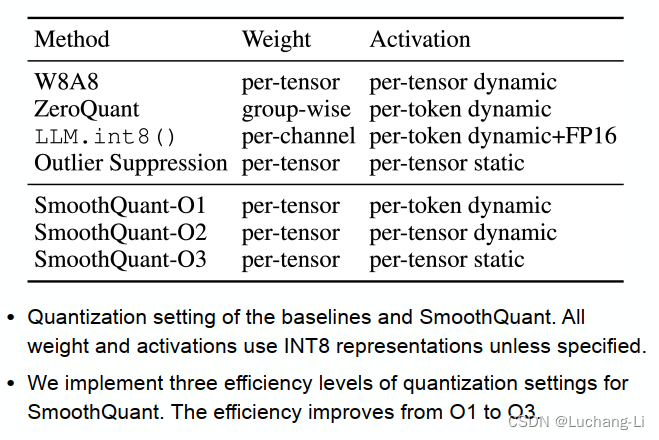
Migration strength大小选择
一些实践的考虑
smooth quant用per-tensor weight quant看上去有些震惊,这个对精度并不友好。为何其不分别对激活和权重用per-channel量化?下面可以给一些解释。
与矩阵乘的计算兼容问题
参考量化的基础
深度学习模型量化基础_Luchang-Li的博客-CSDN博客
首先从对称和非对称量化的角度,activation可以用非对称量化,而激活一般只能用对称量化。(当然如果activation是float, 把weight cast到float做计算的话激活用什么量化都可以)。如果不想额外加一个bias,activation也要用对称量化。
其次,从量化per-axis量化的角度,actication和weight并不是独立都想量化哪个axis就量化哪个axis。
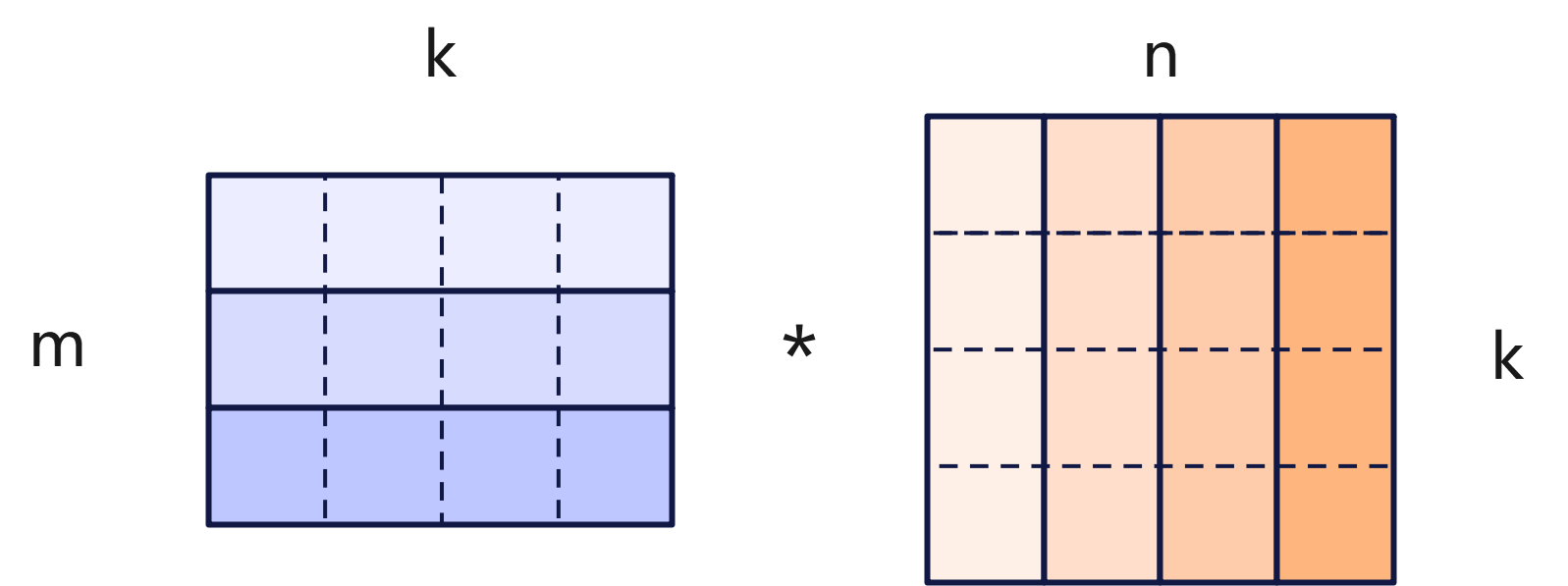
如果激活用per-tensor量化,weight对axis=n进行per-axis量化量化,也就是每一列元素共享同样的量化系数,那么结果矩阵仍然是对axis=n的per-axis量化。
如果激活对axis=m,weight对axis=n分别进行per-axis量化,那么结果矩阵乘将会出现m*n个元素每个元素都有不同的量化系数,这个是我们需要避免的。基于同样的道理,你会发现activation和weight都不能对axis=k做per-axis量化,然后激活和权重只能有一个能做per-axis量化,另一个只能per-tensor量化。
zero-quant对激活做per-axis量化,weight按理说只能做per-tensor量化,但是应该为了精度的考虑使用了对weight采用per-group量化,这样矩阵乘的结果量化系数个数为m*group。实际中其采用了group=48和64。
与ONNX模型定义兼容问题
ONNX算子定义的几个量化相关的算子
输入x, scale, zero_point把float tensor量化为int8 tensor。支持标量scale, zero_point,也支持axis attr和1D scale, zero_point实现per axis量化。
输入x, scale, zero_point,把int tensor反量化为float tensor。支持标量scale, zero_point,也支持axis attr和1D scale, zero_point实现per axis量化。
输入为tensor,输出为per-tensor的scale和zero_point标量值。不得不说ONNX的一些算子定义真是考虑不太周全,这个算子缺少通过attr指定量化axis从而支持per-axis量化。前两个算子都支持了axis,这个算子却不支持(不支持的原因很可能是传统CV的量化激活是per-tensor量化,权重为per-channel量化,而不是transformer这里的激活per-axis量化,权重per-tensor量化,参考:TensorFlow Lite 8 位量化规范)。为了实现激活的per-axis量化,只能添加自定义算子支持,或者自研推理引擎实现。
此外上面的算子定义都不支持float类型为半精度,实际上混合精度这里可能反而是float16而不是float32。
此外还有
用于实现int8输出得到FP32输出。
通过ONNX的算子定义可以看到,ZeroQuant的per-group量化是无法支持的,并且这两种量化方法都要对激活采用per-axis量化,只能对dynamicQuant算子做扩展,或者采用静态量化。
其他
这两个方法结合的可能?进一步改进的方向?
总的来说SmoothQuant看上去更简单,实现更容易。
而ZeroQuant动态量化的方法不需要校准数据,这使其量化更加通用。
SmoothQuant加缩放后应该也可以对权重采用per-group量化。
ZeroQuant的蒸馏方法看上去很吸引人,还可以做4bit量化(W4/8, we quantize the MHSA’s weight to INT8 and FFC’s weight to INT4)。


















 5216
5216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











