







FPGA verilog做基于模板的图像处理的方法
首先,在如今CPU和GPU具有极强计算能力的情况下,为什么还要考虑用FPGA做图像处理呢?我觉得原因可能有:1,FPGA可以通过硬件接口直接连相机,从而实现实时在线处理。而基于CPU和GPU需要操作相机厂商依赖的SDK,比较难做到实时在线。2,FPGA的计算特点能够很好的匹配某些图像处理模式,处理性能比CPU和GPU更强(比如基于固定模板的图像处理,也称二维卷积。图像与一个固定大小和内容的模板进行卷积,每次操作只涉及到卷积模板覆盖的局部像素区域,如均值、高斯滤波等等)。也就是说选用哪种处理器,还得看具体的应用,不同的处理器适合不同的处理场合。
对于FPGA,我觉得,学会语法仅仅是入门,而要在FPGA的世界里自由的翱翔,必须熟练掌握另外两种核心的思想:流水线(pipeline)和状态机(state machine)。有了这两个强大的工具,往往才能高效、高性能的处理复杂的应用。这里FPGA做图像处理,就要用到pipeline的方式。
首先简单介绍下pipeline是什么。对于一个计算f=(a+b)*(c+d),编写后的模块如图1所示。
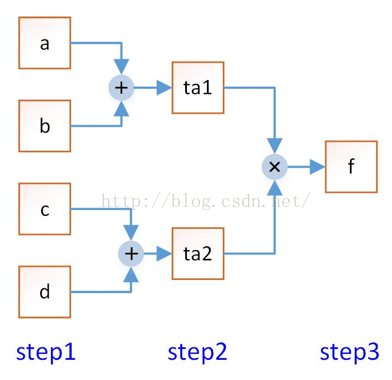
图1
其中,每个方框指一个寄存器,+和x指相应的组合逻辑运算。如果你有好几组数据需要计算,不像C语言那样,第二组数据必须等待第一组数据计算完成之后才能进行。而流水线的模式则是:第一组a,b,c,d完成step1的加法运算后进入step2,这个时候step1的寄存器已经空出来,第二组数据即可马上进入。第一组数据结果进入到step3的时候,第二组数据已经进入step2,而第三组数据则可以进入step1进行计算。这样原始数据可以源源不断连续进行输入,无需等待前一次的数据计算完成。这个例子的代码如下:
<span style="font-size:14px;">module admul1 (
input [15:0] ia,
input [15:0] ib,
input [15:0] ic,
input [15:0] id,
output [31:0] of,
input clk, // Clock
input rst // Synchronousreset active high
);
reg [15:0] a,b,c,d;
reg [16:0] ta1=0;
reg [16:0] ta2=0;
reg [31:0] f=0;
assign of = f;
always @(posedge clk ) begin
// clk1
a <= ia;
b <= ib;
c <= ic;
d <= id;
// clk2
ta1 <= a + b;
ta2 <= c + d;
// clk3
f <= ta1 * ta2;
end
endmodule</span>言归正传,接下来说明FPGA如何做基于模板的图像处理,这里以一个3x3的均值滤波为例。在这之前,你必须了解相机的数据是怎么传到FPGA中的。图像是一个矩阵,如图2所示,这里假设该图像只有4x4个像素。
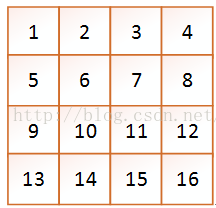
图2
但是由于像素的读出一般不是能够一下全部读出的,而是一个一个或者几个像素为一组,从一个输出端口加上行、场信号(Line valid, Frame valid)进行输出,类似图3,这里假设每次只读出一个像素.

图3
要实现基于模板的处理,我们需要一些移位寄存器来构成行缓冲器,一般都有相应的IP可用(如果没有好用的IP可以用FIFO自己搭建)。其效果如图4,特点是每个时钟右移一个像素,其长度刚好可以储存一行图像,不能多不能少。当第二行的图像的第一个像素开始传入时,第一行的第一个像素则开始移出。

图4
要实现3x3的均值滤波,需要3个行缓冲器加一些外部寄存器,完整实现框图如图5.
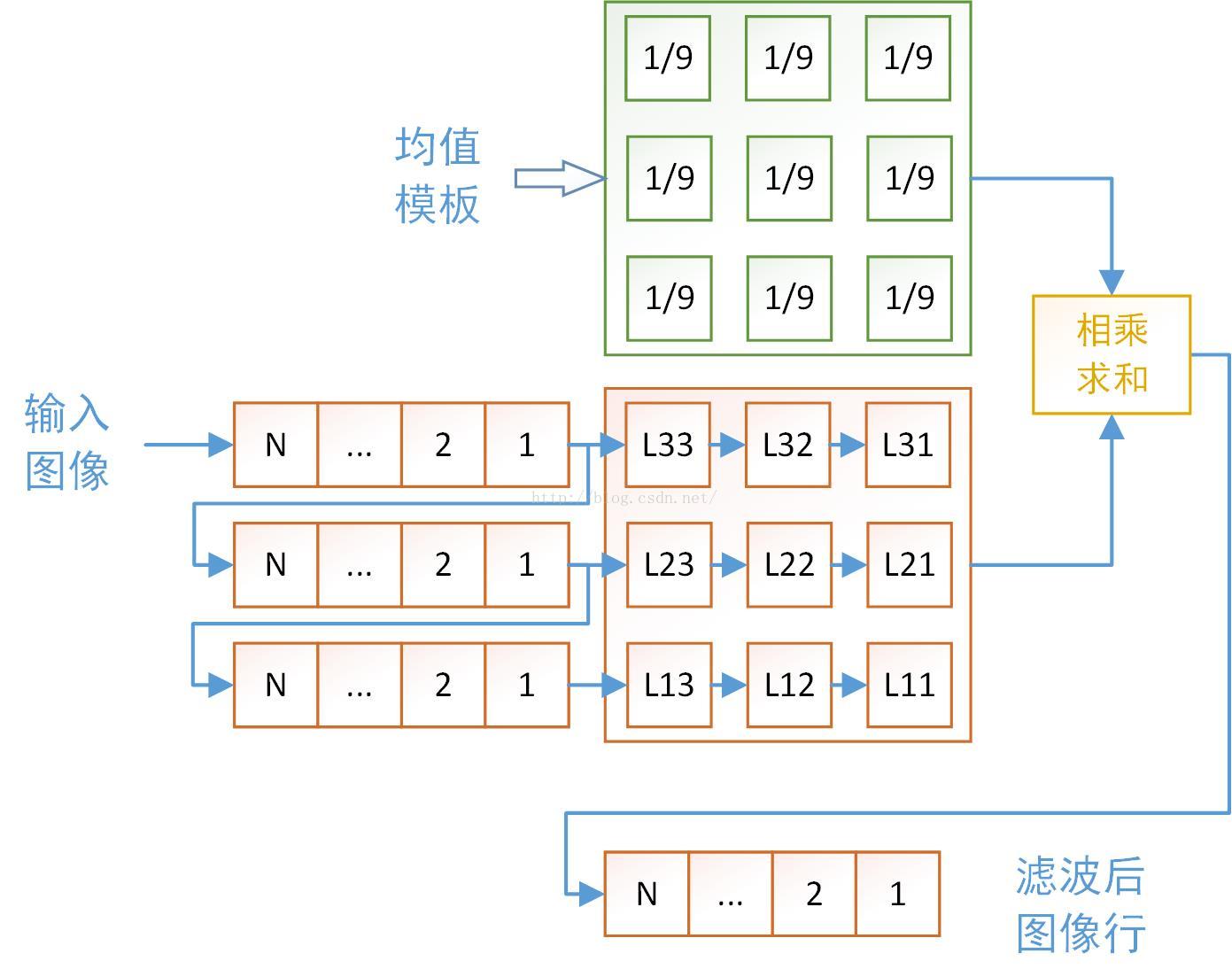
图5
特点是上一个行缓冲器的数据在流入下一个行缓冲器的时候,还要输出给外部的寄存器,用来获取当前位置的像素值。假设刚好图像的前三行像素填满了这三个行缓冲器,然后每个时钟每个行缓冲器移出一个像素,那么效果就是每一个时钟就实现了一次卷积。当然这个必须要结合行有效和帧有效信号来判断当前是不是处理的有效数据。该滤波代码如下所示,不包含line buffer的实现。
<span style="font-size:14px;">module AveFilter_core (
// 3 pixel input
input [47:0] imgLine3,
input [47:0] imgLine2,
input [47:0] imgLine1,
//1 pixel
output [15:0] opixel,
input ival, // keepSynchronous with imgLine2
output oval,
input clk, // Clock
input rst //Synchronous reset active high
);
reg [15:0] DataLine1 [2:0];
reg [15:0] DataLine2 [2:0];
reg [15:0] DataLine3 [2:0];
// clk1
always @(posedge clk ) begin
{DataLine3[2],DataLine3[1],DataLine3[0]}<=imgLine3;
{DataLine2[2],DataLine2[1],DataLine2[0]}<=imgLine2;
{DataLine1[2],DataLine1[1],DataLine1[0]}<=imgLine1;
end
// clk2
reg [16:0] AddDatL11[4:0];
// clk3
reg [17:0] AddDatL12[2:0];
// clk4
reg [18:0] AddDatL13[1:0];
// clk5
reg [18:0] AddDatL14=0;
// clk6
reg [24:0] AddDatL15=0;
// clk7
reg [15:0] AddDatL16=0;
// output valid
reg [6:0] validarry=0;
assign opixel = AddDatL16;
assign oval = validarry[6];
always @(posedge clk or posedgerst) begin
if(rst) begin
validarry<=7'd0;
end else begin
validarry<={validarry[5:0], ival};
end
end
// clk2
always @(posedge clk ) begin
AddDatL11[0] <= DataLine1[0] + DataLine1[1];
AddDatL11[1] <= DataLine1[2] + DataLine2[0];
AddDatL11[2] <= DataLine2[1] + DataLine2[2];
AddDatL11[3] <= DataLine3[0] + DataLine3[1];
AddDatL11[4] <= DataLine3[2] ;
end
// clk3
always @(posedge clk ) begin
AddDatL12[0] <= AddDatL11[0] + AddDatL11[3];
AddDatL12[1] <= AddDatL11[1] + AddDatL11[4];
AddDatL12[2] <= AddDatL11[2] ;
end
// clk4
always @(posedge clk ) begin
AddDatL13[0] <= AddDatL12[0] + AddDatL12[1];
AddDatL13[1] <= AddDatL12[2] ; // for round off ofAddDatL15
end
// clk5
always @(posedge clk ) begin
AddDatL14 <= AddDatL13[0] + AddDatL13[1];
end
// clk6
always @(posedge clk ) begin
AddDatL15 <= AddDatL14*8'd57; // 9=512/57
end
// clk7
always @(posedge clk ) begin
AddDatL16 <= AddDatL15[24:9]; //
end
/*
average filter
f1=[
1 1 1
1 1 1
1 1 1
]*1/9;
*/
Endmodule</span>上面讨论的是每次读出一个像素的情况,但实际中以camera link接口为例,每个时钟可以同时传入5个像素,也就是说每次也必须同时处理5个像素的卷积运算。这就需要实例化5个滤波核心。以每次并行两个像素为例的实现框图如下,这需要两个滤波模块并行处理:
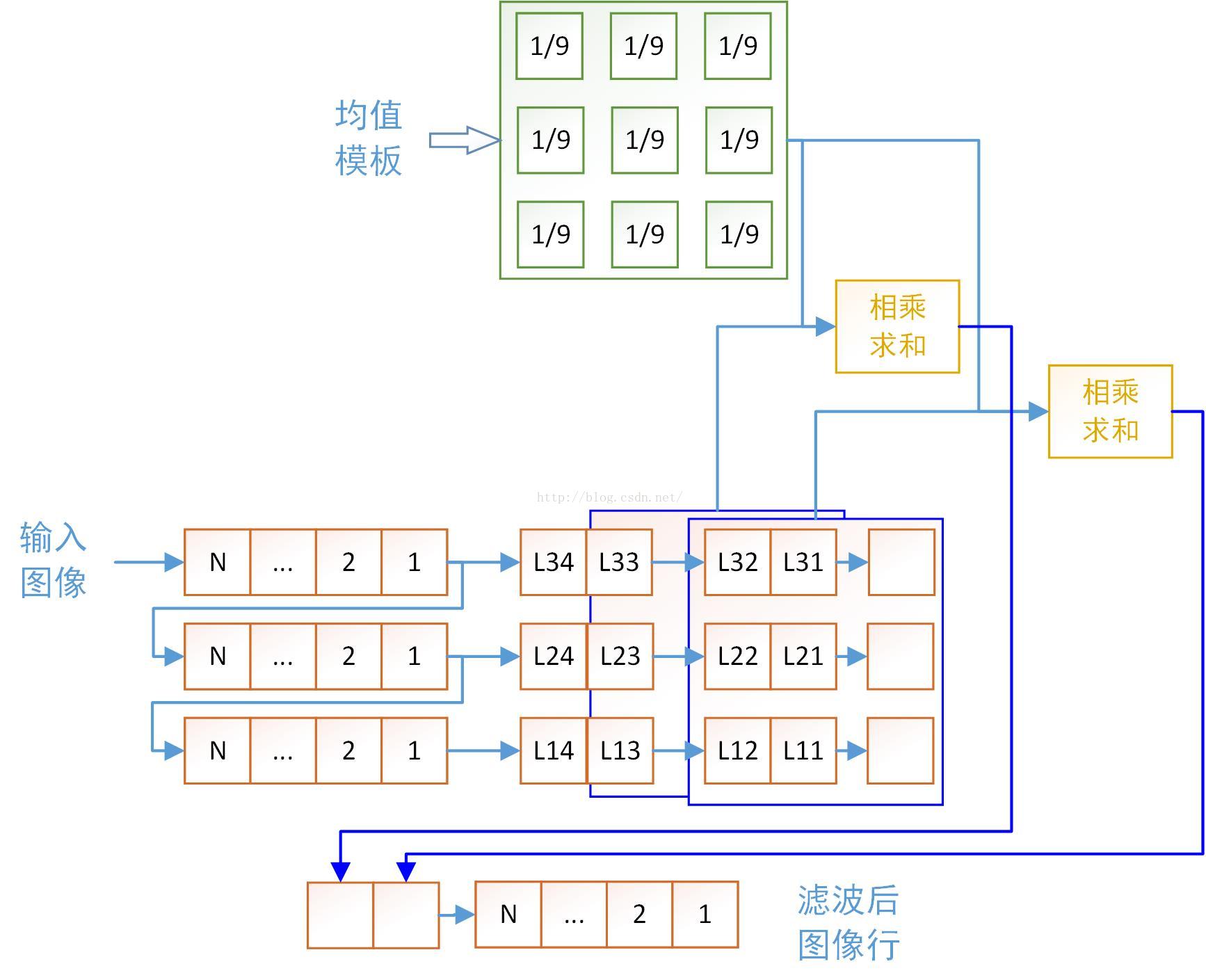
图6
参考文献
http://www.cnblogs.com/oomusou/archive/2008/08/25/verilog_sobel_edge_detector.html
Luchang Li
2016.05.27
















 4907
4907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











